 文章
面向服务的架构
文章
面向服务的架构
在 Oracle Service Bus 和 Oracle SOA Suite 中避免服务调用失败
作者:Rolando Carrasco 和 Leonardo Gonzalez
2017 年 4 月
简介
本文面向希望了解/验证在集成管道中避免服务调用失败的策略的 Oracle Service Bus (OSB) 开发人员和架构师。
本文作者身兼架构师和开发人员双重角色,见过在很多项目中,开发人员或架构师未能设计或实施良好的异常/故障管理策略。
本文将概述一系列避免此类故障的策略。
本文中的一些想法最初由我们的同事 David Hernández 于 2015 年10 月在秘鲁利马的微服务和 API 管理专题讲座上提出。该专题讲座重点介绍在服务开发过程中减少故障的各种策略:
- 断路器
- 隔板
- 超时
- 冗余
在本文中,我们将对 Oracle Service Bus 应用这些策略。
这些策略可以使用 OSB 和 Oracle SOA Suite(组合)实施。当前新版本 (12.2.1) 的一些特性可以帮助您实施这些策略;其他策略是 OSB 中非常基本的配置,很多人都忽略了,因此在其 Service Bus 实现中为保持稳定性而绞尽脑汁。
切记,在任何实现 Service Bus 的基础架构中,Service Bus 都是一个核心要素。CIO 和经理们有时并未特别重视这个平台,他们还觉得奇怪,为什么如果 OSB/SOA Suite 不可用,整个基础架构就会崩溃。有时候,他们还奇怪为什么一个平台不可用或承受高负载时,OSB 就会运行困难。答案很简单:OSB 是您的基础架构和架构中的集成管道。假设您家里的水管破裂:您虽然看不到,但墙里面或者是地板下面正在变得一团糟。此处同理。
还要记住,60% 的服务开发与异常管理和避免故障的能力有关。如果我们对此并不关心,或者期望别人来操心,那就错了。您需要能够识别以下情况:
- 如果我调用的服务停止怎么办?
- 如果我调用的服务在预期的响应时间内不响应怎么办?
- 如果我调用的服务未准备好接收我将发给它的调用量怎么办?
- 如果 JMS 队列失败怎么办?
- 如果数据库调用费时比预期长怎么办?
- 如果我来处理错误怎么办 — 接下来会发生什么?
- 如果我管理错误,将消息保留在队列中以便稍后重新处理,怎么办?端点是否准备好了?
- 如果我发送所有这些事务进行手动恢复,怎么办?
- 如果我不管理任何事情,会怎么样?
- 如果平台发生故障或不可用,怎么办?我准备好避免多米诺效应了吗?
- 如果我需要切断管道回路,怎么办?
- 如果我的文件系统空间不足,怎么办?
这只是分您要面对的部分“该怎么办”问题。
您可以看到,故障随时随地都可能发生,我们必须做好准备。
在本文中,我们将详细阐述不同情况,并展示 OSB 如何用不同的策略应对这些情况。我们还将介绍一个概念,创建它主要是为了解释划分责任在任何 SOA-Service Bus 架构/基础架构中的重要性:服务总线共谋。
您可能会想:这是什么?
答案很简单:如果我们听任自己的 SOA/OSB 实现成为导致事故、停机时间、持续可用性中断和 SOA/OSB 服务器崩溃的问题的一部分,那么我们就是与其他人的问题构成共谋。不仅如此 — 我们还非常可能是问题的根本原因,或者是业务持续可用性的阻碍。这难道不严重吗?
我们认为这非常严重。它可能让我们失去工作,搞得我们身心俱疲。
那么我们来看看在 SOA/OSB 实现中避免故障的不同策略,以避免成为刚刚提到的同谋。
断路器
这一概念体现在 Oracle SOA Suite 12.2.1 版中的一个特性中,作为一个选项(持续可用性)提供,可在当前 Oracle SOA Suite 许可的基础之上获得许可。
断路器是用于中断上游服务未按预期响应的特定情形的机制。一个常见用例是当用于与其他平台(如 CRM 应用)通信的 Web 服务(例如)停止时,或是在其承受高负载,无法如数处理从集成管道(Service Bus 管道、组合)接收的请求时。
中断适用于向上游产生负载的下游服务。这种情况下,断路器将避免上游过载。下游将暂停,向调用方返回错误。现在调用方负责管理故障并进行报告。
除了这种常见情况导致的明显问题之外,它还令运营团队、CIO 及企业本身头痛不已。
Service Bus 和 SOA 基础架构通常会向不同的系统/平台生成请求。当这些系统/平台不可用或有问题时,OSB 或 SOA 服务器就可能面临以下情况:
- 许多线程需要一些时间才能完成。它们仍在运行,因为要等待给定服务/平台的响应。
- 随着时间的流逝,管道渐渐塞满。时间再长些,会有更多请求到达,更多线程有被阻塞的风险。
- 我们的 WebLogic 服务器开始报错(我们的意思是:WARNING 状态)。
- 这些服务的使用者要么收到许多错误,要么根本收不到任何响应。
- 如果是最终用户系统,客户已经在等待“系统恢复”。
- WebLogic 服务器由 WARNING 进入 FAILED 状态。
- 现在所有运营团队进入应急模式!
我们来看看在 Oracle SOA Suite 12.2.1 之上实现断路器功能是多么轻松。
在 Enterprise Manager 中,转到 SOA-INFRA 页面:
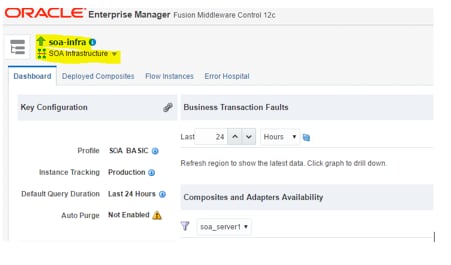
图 1
单击 SOA Infrastructure 子菜单,然后单击以下选项:
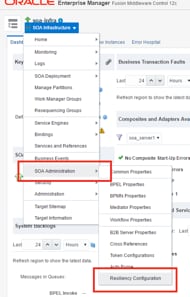
图 2
在 Resiliency Configuration 部分,我们需要进行一些非常简单的配置来激活断路器:
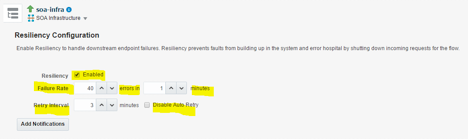
图 3
- Resiliency 复选框。激活此框以启用断路器特性。注意:此特性需要许可(请向销售代表咨询定价模式)。
- Failure Rate。特定上游服务将引发的错误数。如果错误数高于此数字,断路器将启动。
- Errors in minutes。此参数确定 Failure Rate 指定的错误需要在多长时间内发生。在上面的例子中,如果特定服务上 1 分钟内有超过 40 个错误,断路器将启动。
- Retry Internal。检查上游服务是否响应之前必须经过的分钟数。如果正在响应,请求流将继续。
- Disable Auto Retry。如果激活此框,就必须在问题解决后手动激活服务。
您可以看到,此特性非常强大,但也很容易配置。
以下示例说明了断路器的功能:
假设我们有一个由 CRM 应用提供的 Web 服务,在某些情况下,它需要 30 多秒才能响应。此 Web 服务作为 Oracle SOA Suite 12.2.1 中一组服务和组合的一部分使用:
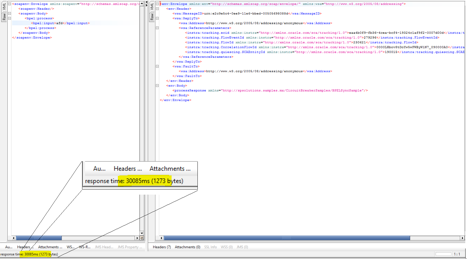
图 4
在高负载情况下,需要的时间可能不止 30 秒,甚至可能没有响应。开发团队未配置任何可以避免灾难的超时或故障策略。
我们有一个下游服务一直在调用此服务。在第一个服务用了超过 30 秒才响应,甚至更糟,根本不响应的情况下,这第二个服务就非常费劲,对依赖于它的其余使用者产生多米诺效应。错误开始发生,WebLogic 进入 WARNING 状态,然后因为有大量阻塞线程,WebLogic 就会宕掉。
现在我们来看看如果激活断路器特性会发生什么情况:
- 执行下游服务(上一段描述的第二个服务)时,第一个服务非常缓慢地开始响应,甚至根本不响应,我们得到这个答案:
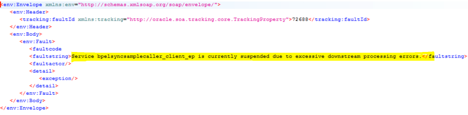
图 5
这已经抛出了一个故障,并说明了故障的起源。因此我们已经掌握了这个情况。调用方根本未挂起;它正在接收响应。
- 在日志文件中,我们看到:

图 6
- 在 SOA-INFRA 主页上,我们看到一个挂起服务(1 分钟内有超过 40 个错误的服务)的列表:
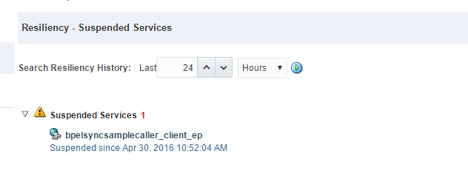
图 7
比如说,我们有一个有问题的服务(我们称之为服务 A),在高负载下可能令人头痛。有时它的响应时间超过 30 秒,有时则根本不响应。我们还有另一个服务(我们称之为服务 B),它一直在调用服务 A。如果没有恰当的故障管理,这种情况就是一个定时炸弹。要消除它,请使用断路器。服务 B 暂停,因此其调用方不受服务 A 不响应的影响。
您在以下部分可以看到,如果我们混用不同策略,SOA 服务将得到保护,我们可避免与其他人的危机形成共谋。
隔板
“隔板”一词通常与船舶相关联。隔板的作用是避免全军覆没。如果部分船体进水,隔板就会将水流限制在该舱室,这样船就不会沉。
这个想法如何应用于 OSB 实现呢?OSB 实现中常见的情况是:“后端系统停机时,SOA 基础架构不起作用!为什么?”听起来是不是很熟悉?
在 Oracle SOA Suite 中,有一些保护 SOA 基础架构的机制。因此,如果集成应用的任何部分停止工作,您的船也不会沉。
这些机制包括:
- 工作管理器
- 超时
- 节流
可以使用本文所述的其他三种策略实现隔板。但我们先试着阐述一下隔板的想法,而不赘述其他策略。
隔板让船具备容错功能。但是不是隔板越多,故障的可能性就越小?在我们的 OSB/SOA Suite 场景中,情况并不一定如此 — 除非每个隔板专用于特定的服务域。
想像一个想与 eTOM 域保持一致的电信公司:
- 履约
- 计费
- 保证
- 运营和支持
现在假设我们有强大的硬件,使用 Oracle Exalogic 部署 4 个 Oracle SOA Suite 域,使其与 eTOM 保持一致。我们创建 4 个隔板,每个隔板存储和维护一个 eTOM 域。如果一个域关闭,船可以继续航行,但如果两个或更多个域关闭,船很可能要下沉。
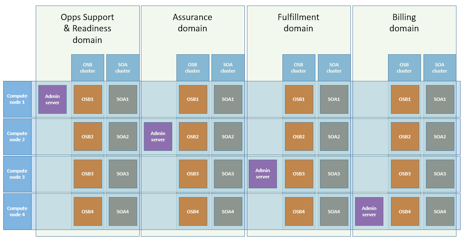
图 8
图 8 阐释了隔板的概念。接收方可能停机,但我们的“船”将继续航行。每个接收方还分成更小的单位。
在本例中,我们的隔板可以和域内的托管服务器一样小。我们可以看到,域之间是隔离的,也可以将其视为更大的隔板。在这种情况下,如果运营和支持部分停止工作,计费、保证和履约部分仍然正常工作,企业可以继续运营。
我们可以将这种想法进一步延伸,使用 SOA Suite 分区作为更小的隔板。不仅我们的域被隔离,而且在这些域中的服务也被隔离。请记住,12.2.1 能够为每个 SOA 分区分配一个 Weblogic 工作管理器。通过该功能,较小的隔板可以是 SOA Suite 域中的一个分区,而且由于它使用特定的工作管理器,线程之类的就被隔离了。影响一个分区中的服务的问题不会影响另一个分区中的服务。
我们可以看到,Oracle SOA Suite提供了一些很好的技术方案来支持隔板策略。
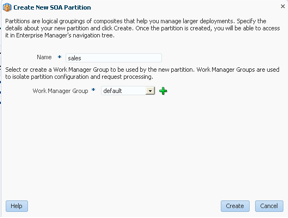
图 9
这里提供了与此有关的 Oracle 官方文档。
还可以用其他几种方式创建这个隔板策略。本文限于篇幅,就不一一介绍了,但会在另外一篇单独的文章中讨论 Docker、WebLogic 12.2.1 多租户和微服务。
超时
在 Oracle SOA Suite 中,某些基础架构属性可以控制事务超时。超时对于保护 SOA 基础架构不受长期运行的对外部组件(数据库、Web 服务和其他应用)的同步调用的影响至关重要。如果这些组件中有一个需要很长时间才响应我们的调用,就会产生长时间运行的线程。
如果这些线程在确定的时间段(默认为 600 秒)后仍在运行,WebLogic 托管服务器将进入 Warning 状态,线程池中的线程将标记为 STUCK。有了相当数量的 STUCK 线程之后,基础架构将被迫停止接受和处理请求。
为了在 Oracle SOA Suite 中保护我们的 SOA 域,对某些参数进行微调以获得适当的行为非常重要。
这些参数中的第一个是 JTA 超时,它指定一个分布式事务允许存在的最长时间(以秒为单位)。超过此时间,事务将自动回滚。通常,这被配置为基础架构中的最长时间。要配置 JTA 超时,您必须导航到:
WebLogic Administration Console > domain > JTA > Timeout seconds(此值单位为毫秒)
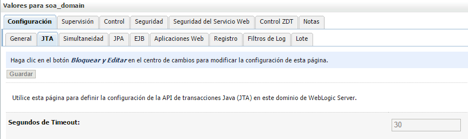
图 10
第二层级是 SOA EJB 超时。必须修改的 EJB 超时包括:
- BPELActivityManagerBean
- BPELDeliveryBean
- BPELDispatcherBean
- BPELEngineBean
- BPELFinderBean
- BPELInstanceManagerBean
- BPELProcessManagerBean
- BPELSensorValuesBean
- BPELServerManagerBean
注:在版本 12c 中,另外还有 4 个 EJB:
- BPELCacheRegistryBean
- BPELCacheStoreBean
- BPELClusterBean
- BPELKeyGeneratorBean
要配置这些超时值,请导航到:
WebLogic Administration Console > domain > Deployments > soa-infra(展开)> EJB(展开)> BPELBean(选择)> Configuration(选项卡)> Transaction Timeout(此值单位为秒)。
图 11
第三个要配置的超时是 SyncMaxWaitTime,即 BPEL 流程在向客户端返回结果之前等待的最长时间。这是一个域级 Oracle BPEL Engine 属性(适用于同一容器上部署的所有 BPEL 流程),仅适用于同步调用。
要配置此超时,请导航到:
Enterprise Manager > Navigation 图标(左侧)> soa-infra(单击,12.2.1 中不允许右键单击)> SOA Infrastructure(下拉菜单)> SOA Administration > BPEL Properties > More BPEL Configuration properties(链接)> SyncMaxWaitTime(此值单位为秒)。
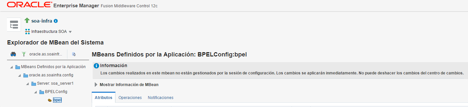
图 12

图 13
配置这些属性后,您可以为组合应用中的 BPEL 流程(绑定)或 Service Bus 项目中的 Business Service 配置具体的超时。
众所周知,Service Bus 项目中的业务服务代表了对外部组件(数据库、JMS、Web 服务及其他应用)的引用。在 Service Bus 中,超时配置是一个图形化活动。您必须导航到您的业务服务并选择 Transport Detail 选项卡,然后配置 Read Timeout 和 Connection Timeout 属性。
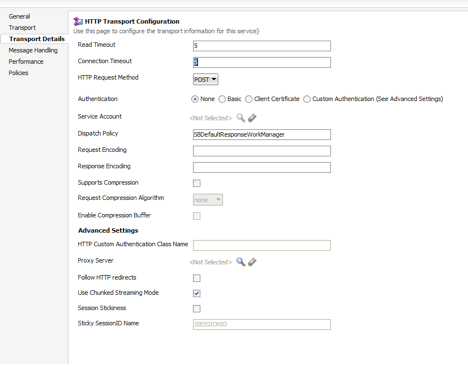
图 14
只需转到 composite.xml 文件中的 reference 部分,在 binding 中添加以下属性:
- oracle.webservices.local.optimization (false)
- oracle.webservices.httpConnTimeout(以毫秒为单位的超时)
- oracle.webservices.httpReadTimeout(以毫秒为单位的超时)
您的组合代码应如下所示:
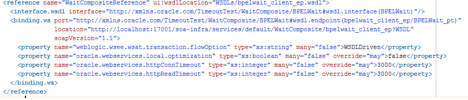
图 15
您必须禁用本地优化,因为超时(读取和连接)属性通过 HTTP 工作。在 Oracle SOA Suite 中,本地优化默认是启用的,这样可以优化同一容器上部署的各 BPEL 流程之间的同步调用。如果我们保持此属性为“true”,则不会考虑 HTTP 超时。
可以为组合应用中的每个绑定配置这些超时。
在 SOA Suite 中配置超时之后,当某个同步调用用时过长时,就可以与客户端通信。然后,客户端可以管理此消息,SOA 基础架构可以中断所有长时间运行的线程,从而避免不必要的资源(线程、内存、处理器)消耗并保护服务器免于产生 STUCK 线程和可能的服务丢失。设置以下场景:
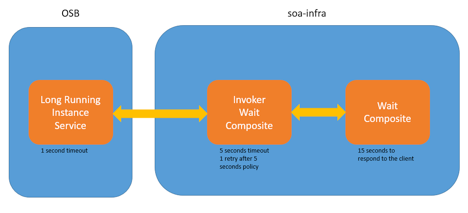
图 16
Wait Composite 是一个 BPEL 流程(服务 A),执行等待活动。它要等待 15 秒才响应服务使用者。
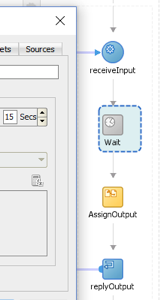
图 17
Invoker Wait Composite 是另一个 BPEL 流程(服务 B),它调用 Wait Composite。此组合配置了超时(读取和连接)属性,每个属性都是 5 秒。我们还配置了本地优化属性 (false),因为两个 BPEL 流程都部署在同一容器内。而且,如果执行失败,此 BPEL 流程将使用故障管理框架重试一次(5 秒钟后)。

图 18
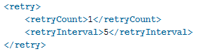
图 19
Long-Running Instance Service 是一个 Service Bus 项目(服务 C)。此服务有一个配置了 1 秒超时的业务服务。业务服务调用 Invoker Wait Composite。
图 20
在此场景中,Wait Composite BPEL(服务 A)需要 15 秒才响应其调用方(服务 B)。服务 A 不会抛出任何错误,只是需要 15 秒才响应。当服务 B 调用服务 A 时,在 5 秒钟(配置的超时)后会生成一个超时异常。因为配置的策略的原因,服务 B 将在 5 秒钟后重试一次,但服务 A 要再等 15 秒才响应。然后,调用方捕获超时异常,发出一条错误消息作为响应。
超时是重要的考虑因素之一。如果调用者未配置超时参数,怎么办?如果调用者没有 catch 块来管理错误消息,怎么办?
此外,我们还有服务 C 调用服务 B。服务 B 需要 10 秒才响应其客户端(5 秒是配置的超时,另外 5 秒是重试间隔时间)。如果业务服务未设置超时属性,服务 C 会一直等待,直至服务 B 响应。
现在,假设这个场景的响应时间大约为 10、15 或 20 分钟。还假设有许多对服务 C 的请求。这导致 SOA 基础架构(托管服务器、SOA 和 OSB)内出现大量 STUCK 线程。
使用超时保护 SOA 基础架构是一种简单但非常有效的方式。在相应的组件中使用这些属性,就不会产生可能损坏 WebLogic 服务器性能或状态的级联效应。
冗余
在这组避免故障的策略中,这似乎是很明显的一个。在整个 SOA/Service Bus 实现中经常采用此策略,不仅仅是 Oracle,各种供应商都是如此。
我们在此介绍它,是因为它有时并不被看作一个优点和策略。有时,我们不能容忍双节点集群中有一个节点关闭。但为什么?这不正是冗余的目的吗?其目标不正是容错策略吗?
《Oracle SOA Suite 12c 企业部署指南》说明了此类部署用于实现集群和冗余目的:
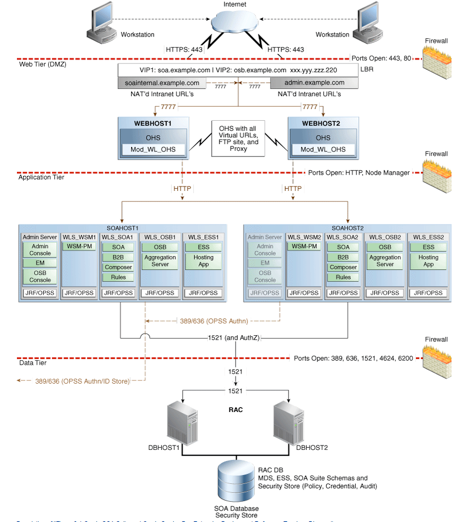
图 21
(图片来自《Oracle SOA Suite 融合中间件企业部署指南》)
我们可以看到,OSB、SOA 和 OWSM 在两台服务器上冗余配置。甚至信息库(数据库)也是以 Oracle RAC 模式部署。在中间件层,此部署利用了 WebLogic 集群功能。
在我们的集成管道和服务上,这种部署本身就提供了冗余性。假设一个节点停机,另一个节点将在第一点节点不可用时为负载服务。事实如此。如果您有这种类型的架构,那就放心好了。您可以信任这种部署提供的集群功能。虽然我们希望平台尽可能的稳定,可以避免任何类型的停机时间,但如果我们因为一个节点故障而不得不使用另一个节点时,就听其自然并恢复损坏的节点吧。不要惊慌:这个架构就是为这种情况打造的。
关于此策略,首先要强调的是:信任 WebLogic + SOA Suite 的集群/冗余能力。它们会为您的服务提供冗余。假设您有大量客户在事务密集型的环境中使用您的服务。突然一个节点停机了:底层除了点儿问题,操作系统有问题,已决定重新启动。客户访问负载平衡器,后者识别出一个节点停机,于是将所有调用重定向到仍然可用的节点。服务在两个节点中均已准备好;甚至“脱水”的组合也可以在可用节点中继续执行。Oracle SOA Suite 的冗余/集群功能会保护您。
Oracle SOA Suite + WebLogic + Coherence 提供了不同的方式来提高冗余性。下面来分析其中一些:
- Oracle Coherence:自 11g 版起,Coherence 已纳入 OSB 中,用于在 OSB 中为代理服务启用数据缓存。假设有一个 Customer 服务;其操作之一是获取指定客户的基本数据。各种各样的使用者通过移动、Web、内部应用等不同渠道使用此服务。通过 OSB 集群的所有节点甚至通过更多计算机(如果您的架构允许的话)提供缓存。在这种情况下,服务是冗余的,Coherence 也为数据访问提供了冗余。在这种情况下,您采用了双重冗余策略,不仅针对服务,还针对数据访问。
- JMS 分布式队列:如果您的服务依赖于 JMS 队列/主题,WebLogic 可以在整个 WebLogic 集群中分配这些资源。一个节点出现故障并不会危及消息。相反,消息会在集群中分配,因此始终可用。如果您将此办法与基于数据库表的持久性存储混用,则不仅队列具有冗余性,这些消息的存储也具有容错性。
- 指向多个端点的业务服务:OSB 提供了此功能;可以配置一个指向一组不同端点的服务。
- 组合也提供了类似的功能。但在本例中,仅当第一个端点发生故障时,它才起效。假设 composite.xml 中有以下条目:
<code> <reference name="Customer" ui:wsdlLocation="Customer.wsdl"> <interface.wsdl interface="http://www.spsolutions.com.mx/Customer/ First/BPELProcess1#wsdl.interface(BPELProcess1)"/> <binding.ws port="http://www.spsolutions.com.mx/Customer/Second/ BPELProcess1#wsdl.endpoint(bpelprocess1_client_ep/BPELProcess1_pt)" location="http://10.10.10.10:8001/soa-infra/services/default/ First/customerprocess1_client_ep?WSDL"> <property name="endpointURI">http://10.10.10.10:8001/soa-infra/ services/default/Second/customerprocess1_client_ep</property> </binding.ws> </reference> </code>
第一个端点是默认的,在本例中为:
http://10.10.10.10:8001/soa-infra/services/default/First/customerprocess1_client_ep?WSDL
所有请求都将到达此端点,直到发生故障。如果此端点发生故障,将使用第二个端点:
http://10.10.10.10:8001/soa-infra/services/default/Second/customerprocess1_client_ep在此,我们就为该特定服务 (Customer) 准备了一个冗余端点。它可以部署在不同基础架构、不同域等等上面。重要的是保护我们的服务避免故障,保持组织的业务连续性。
- Coherence 联合缓存:与此列表中的第一点类似,我们可以利用 Oracle Coherence 特性实现联合缓存。OSB 中使用 Oracle Coherence 的服务可从此特性中受益。假设 Coherence 缓存分布在两个相距很远的不同站点上:
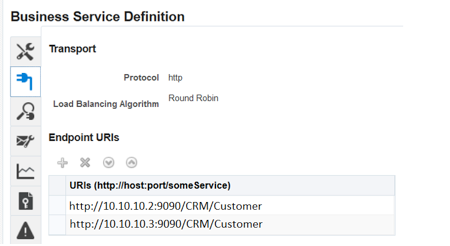
图 22
在本例中,我们在端点级别实现了冗余。发生故障时,可以对此端点应用特定规则。例如:如果一个端点停止响应,可以将它标记为非活动状态。
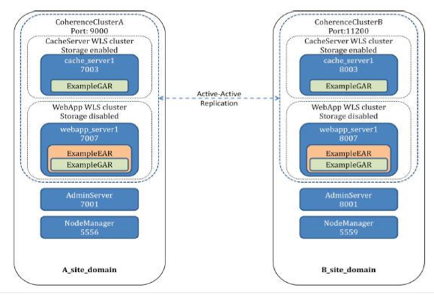
图 23
服务将兼具上述列表项中所述的冗余性和不同站点/域上的联合缓存。这不是一个可以提供尽可能高的可用性的基础架构吗?即使发生灾难,我们的服务和集成管道仍然有足够的冗余来继续执行。
总结
我们介绍了避免故障的四种主要策略:
- 断路器
- 隔板
- 超时
- 冗余
我们可以混用这些策略,事实上,我们也鼓励您这样做。对于某些情况,有些策略比其他策略更适合。不要试图用一种方法应对所有情况 — 这会给您带来麻烦。
尽量减少“SOA/OSB 共谋”的概念。当故障发生时,我们不想成为共犯和/或受害者。我们需要在故障发生时始终做好准备,主动应对。设计和部署做地越好,您的周末时间就越多,烦恼就越少。与家人共度美好时光,而不必挂念报告 OSB 崩溃的电话,这样不是很好吗?
要让您的基础架构团队相信您需要更多基础架构来部署一个“坚不可摧的”部署,有足够的隔板来隔离故障。不要犹豫。这对整个组织都有好处。
请尝试始终用简单的方式解释架构的工作原理 — 服务恢复时会给您节省不少时间。如果您的队友了解集群、超时之类的工作原理,他们就会了解故障情况。
Oracle SOA Suite 12c 提供了一套很好的工具来实施这些策略。使用它们、依赖它们,毫不犹豫地实施。
信任 Oracle 提供的技术;如果您有集群,就使用它吧。如果一个节点需要停机,没问题。请尝试恢复损坏的节点,但不必惊慌。之所以部署集群,就是为了容许故障,因此必要时请使用集群。
始终将 SLA 与平台的其余部分一起安排。不要承担超时或超长响应时间的责任。如果您办不到这一点,那就等着监控团队的大量电话报告吧:“OSB 超时严重。”事实上,OSB 与往常一样正常工作,但平台的响应时间很长。这会影响 OSB,让它成为 IT 部门最喜欢的同谋。
关于作者
Oracle ACE Rolando Carrasco 是墨西哥和拉美 S&P Solutions 团队的 SOA 架构师和联合创始人。他从 2003/2004 年起就在使用 Oracle SOA,其职业生涯主要关注集成领域。Rolando 是墨西哥 Oracle 用户组 (ORAMEX) 的联席董事之一,他还是 SOA MythBusters 博客的联合创始人。
Leonardo Gonzalez 是 S&P Solutions 的一位 SOA 架构师,参与了 IT 项目的整个部署周期,从事企业架构的分析、设计和开发工作。