 文章
面向服务的架构
文章
面向服务的架构
通过数据层缓存提高 SOA 性能
作者:Kiran Dattani、Milind Pandit、Markus Zirn
将高性能注入数据服务
Oracle 融合中间件模式文章系列的一部分。
2010 年 2 月发布
下载
![]() Oracle Fusion Middleware
Oracle Fusion Middleware
![]() Oracle Coherence
Oracle Coherence
简介
面向服务的架构 (SOA) 正在改变应用程序开发和集成的理念。Web 服务标准使人们可以更容易地重用现有的业务逻辑,而不必考虑业务逻辑中实现的具体技术。通过组合流程,BPEL 和其他编排标准可以很容易地将这些服务整合在一起。因此,SOA 提供了更容易访问信息和组合信息的方法。
这带来了很大的好处,显著提高了敏捷性并增强了生产效率,所有这一切都归功于跨现有单体应用程序的互操作性得以提高。同时,SOA 还提升了 IT 的水平,因为业务用户有了更高的期望。现在,业务用户非常习惯使用消费型 Internet 应用程序以及由 Google、Yahoo 及其他公司提供的混搭程序,因此他们也要求自己的企业系统能提供类似的功能。SOA 可以帮助实现这些混搭程序。
这一积极进步的不利之处体现在性能方面。性能/可伸缩性问题已经上升为构建 SOA 应用程序时最令人担忧的问题之一。这种担忧并不奇怪。SOA 组合应用程序的结果显示在用户界面中,因此受可接受的响应时间的制约。用户通常认为超出 5 秒钟才显示的结果无法使用。对在线零售业务的调查显示,只要响应时间超过一秒钟,购物者就会放弃。因为 SOA 采用的是详细 XML(可扩展标记语言)格式,因此在调用 Web 服务时就需要转换数据(编组和取消编组),这就会产生开销。这一抽象加重了 SOA 应用程序性能上的负担。
业务流程中的服务越多,业务流程就越脆弱。如果一个业务流程依赖六个数据服务,每个服务的正常运行时间达到 99%,则业务流程本身的停机时间可能高达 6%。这相当于每年多达 525 小时的意外停机时间。问题并非仅仅如此。尽管数据服务设计为集中数据访问,但如果多个业务流程依赖同一组数据服务,就会出现可伸缩性问题。很重要的一点是,如果强制要求 IT 满足严格的 SLA 协议,那么构建可在所有 RASP 级别执行的 SOA 应用程序就变得极为重要。但是,在数据层构建可伸缩的数据访问存储的最好方法是什么呢?使用户应用程序(进而使业务流程)能够快速访问通常存储在数据库中的数据的最好方法是什么呢?
在本文中,我们将讨论中间层缓存策略如何将高性能作为 SOA 的一部分注入数据服务。我们还将介绍一个大型制药公司结合使用 Oracle Coherence 网格解决方案和 Oracle SOA Suite 提高组合应用程序性能的方法。
SOA 缓存策略
任何 SOA 应用程序的性能都与它检索底层数据所需的时间直接相关。SOA 中的数据一般分为两类:
- 服务状态 — 这类数据与业务流程/服务的当前状态有关,即,当前流程实例此时位于何处,哪些流程处于活动状态,哪些流程已关闭,哪些流程被中止,等等。这类数据特别适用于长期运行的业务流程,通常存储在数据库中以实现与计算机故障的隔离。
- 服务结果 — 这类数据是由业务流程/数据服务交付回表示层的。通常,这类数据具有持久性并存储在后端数据库和数据仓库中。
缓存在提高访问服务状态/结果数据的速度方面可发挥非常重要的作用。缓存用于最大限度地减少使用缓存和底层数据提供程序的服务间的数据流量和延迟。与所有缓存解决方案一样,为业务服务设计的缓存方案也必须考虑以下问题:需要多长时间更新一次缓存的数据,数据是特定于用户的还是应用程序级的,使用什么机制来指示缓存需要更新,等等。
可能缓存两种类型的数据:服务状态和服务结果。
- 服务状态缓存允许一个业务流程中的多个服务共享内存中的服务状态数据。
- 服务结果缓存允许您缓存来自经常访问的业务服务或数据服务的结果。
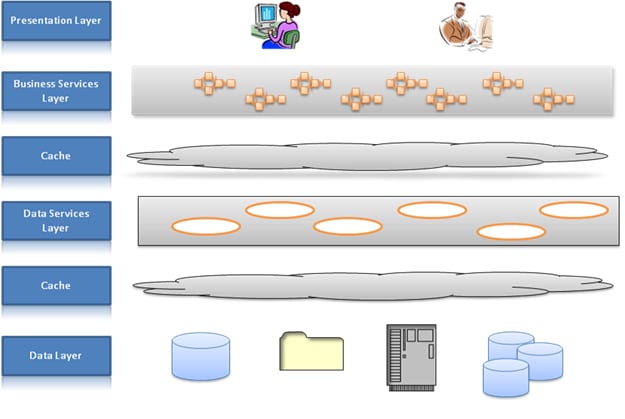
图 2 说明了如何通过实现两层缓存来构建组合 SOA 应用程序以提高性能:
- 上面的缓存层缓存业务服务状态及业务服务结果(即来自数据服务层的结果)
- 下面的缓存层依次缓存数据服务状态(如果需要)以及来自底层数据库和应用程序的应用程序数据。
我们来了解一下数据服务层的工作原理。基本思想是:在访问数据源之前先访问缓存,如果在缓存中找到目标数据,则无需访问数据源,否则,访问数据源,然后添加一个缓存更新。首次调用一个服务时,结果被缓存并送达给使用者。以后再调用时,应用程序逻辑首先查找缓存,如果在缓存中找到目标数据,则直接从缓存中检索数据。这种技术被称为预留缓存 (cache-aside)。
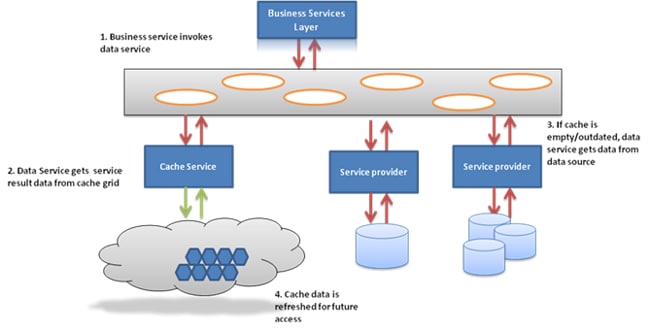
现在数据位于中间层的内存中,数据访问速度比以往快得多,可实现更智能的服务且响应时间更短。基本上来说,以下问题的主要目标是尽可能多地避免会导致性能下降的数据库访问:“这些信息必须是实时的吗?还是近乎实时就足够了?”如果短时间内对一个服务的多次调用可能返回同一结果,则将这一需求放宽为由缓存提供近乎实时的数据将显著增强性能。
预留缓存是一个重要的性能增强策略,专门针对主要从多个不同后端源读取数据的 SOA 应用程序。一个典型用例是汇集一个跨多个数据存储的全方位客户视图。
预留缓存在旅游业中很常用,例如,预订数据近乎实时地存储在缓存中。如果每次浏览酒店床位或机票时都访问数据库,则可能会转化为可伸缩性问题。有时,这甚至需要查找第三方系统,每次查找都会产生费用。因此,大多数情况下都是浏览由缓存提供的近乎实时的旅行数据。您可以使用同样的方法来加快您 SOA 应用程序的速度。
提供全方位的客户视图
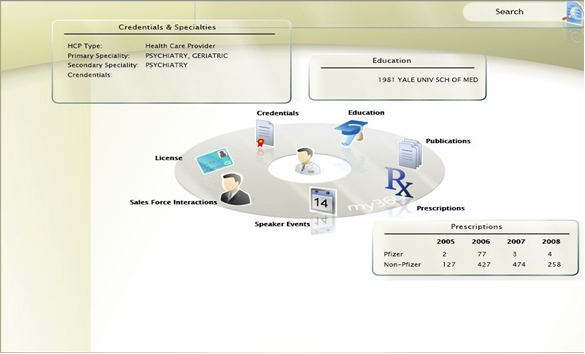
一个非常大型的以研究为基础的制药公司曾经面临着客户信息遍布多个数据存储分布的挑战。业务方面的地域扩张、兼并和收购已经使其添加了额外的后端系统。客户信息位于事务性 CRM 和 ERP 系统、主数据管理存储和业务智能数据仓库中。这种环境很难提供一个反映特定客户以往所有可用交际信息的全方位视图。因此,该公司的销售团队需要为获得有关客户(即医生)的最新信息不断努力。跨多个数据源汇总和筛选任何特定医生的信息列表也构成了巨大挑战。
各地的销售人员都需要实时访问客户信息,这使得问题进一步加剧。试想一名销售代表正在与一名医生交谈,必须根据该医生的专长、研究课题和购买模式推荐新产品。缺少这些信息可能妨碍交流的效果,也可能导致错过追加销售/交叉销售的机会。因此,有必要实现一种依托移动设备为公司的销售团队提供实时体验的新解决方案。
这家制药公司很快意识到,它必须使用基于 SOA 和 Web 2.0 的多渠道解决方案表示层构建一个敏捷的、完全可配置的数据集成解决方案,以便提供一个医疗保健提供程序的全方位视图,从而可以跨医疗保健项目管理 (HCPM)、基层医疗个案管理 (PCCM)、市场营销/活动管理应用程序 (UNICA) 和 CRM (Siebel)、Finance (Oracle e-Business Suite)、主数据管理 (Siperian) 和其他一些数据源成功搜索客户。
结合使用 Oracle SOA Suite 和 Oracle Coherence 的解决方案
这个解决方案的架构支持构建“获取客户活动”的组合应用程序,它将提供以下特性:
- 从多个数据源并发启动数据操作和检索数据
- 根据搜索条件返回一个候选客户列表
- 从候选客户列表中选择一个客户,然后跨多个数据源(Betsy、USDW 和 PubMed)返回特定于该候选客户的一组经过整合和筛选的活动信息
- 选择一个客户活动以查看活动的详细信息并返回特定于该客户的活动信息的细节
- 根据用户的权利限制用户对数据的可见性(活动、渠道和地区范围)
- 以语音方式返回匹配数据。
这家制药公司选择 Oracle SOA Suite 用于流程和数据集成,选择 Microsoft SharePoint 来提供 Web 2.0 层,以便向销售代表提供最终信息。
该公司还决定采用缓存策略来提升 SOA 数据服务的性能。但是,该解决方案必须能够满足以下三个重要缓存需求:
- 该解决方案必须能够承载可轻易超过一个系统的可用内存大小的数据服务缓存大小
- 考虑到会在全球范围逐渐采用的预期,该解决方案必须能够通过向分布式缓存添加服务器进行线性扩展
- 该解决方案必须以尽可能最高效的方式将公司 SOA 中间层中一组现有的商用服务器用于缓存。
总之,公司需要一个可将多台异构服务器上可用的 RAM 内存组合到一个分布式共享内存池中的解决方案。根据这些要求,公司选择了 Oracle Coherence 将服务数据分布在多台异构服务器中,并且跨集群缓存的所有节点对这些数据进行协调。
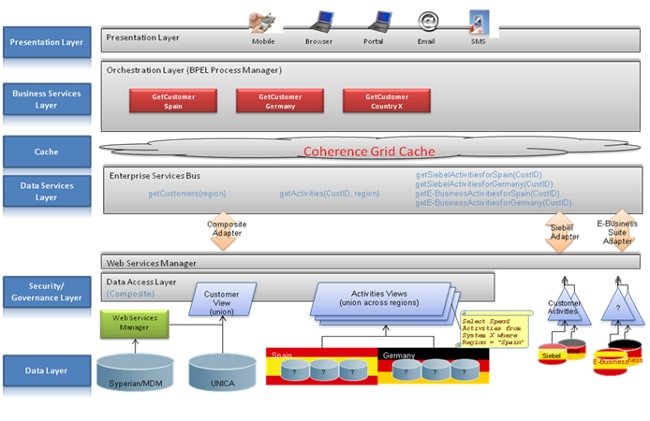
GCA 组合应用程序通过以下流程提供有关特定客户活动的重要信息:
- Oracle BPEL PM 编排业务服务(GetCustomer Spain、GetCustomer Germany 等)
- 这些业务服务调用 Oracle ESB 数据服务(getActivities、按区域的 getCustomers、按应用程序的 getCustomeractivity)
- 数据服务依次从相关的数据源(Siebel、UNICA、Siperian 等)提取所需的数据(通过安全和治理层),然后将数据返回给 Oracle BPEL PM
- 最后,Oracle BPEL PM 在 Sharepoint 门户中将结果显示给销售代表。
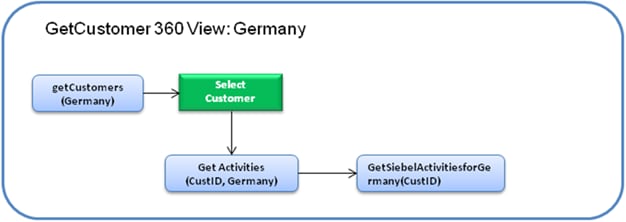
向销售代表的 PDA 传送数据的速度取决于数据服务从底层数据层检索数据的速度。下面,我们来了解一下 Oracle Coherence 在该流程中扮演的角色。
BPEL — Coherence 集成架构
在 GCA 组合应用程序内部,Oracle Coherence 用于缓存数据服务结果数据。因为这些数据不经常变化,因此 Oracle Coherence 从内存而不是通过数据库调用从数据源供应这些数据。
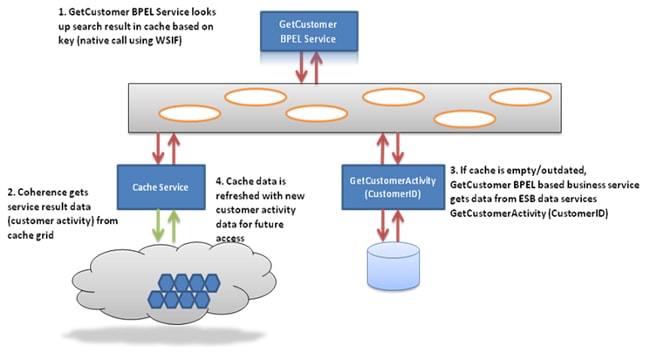
上面的图 6 说明了提取客户活动信息时 BPEL PM、Coherence 和 ESB 之间的顺序流。GetCustomer 是一个基于 BPEL 的业务服务。这种业务服务通常将调用 GetCustomerActivity 数据服务(位于 ESB 层),该数据服务再从底层数据服务提取所需的数据。
不过,由于使用了 Coherence 缓存来自 ESB 数据服务的结果数据,因此该序列稍有不同。首次调用 GetCustomer 服务时,缓存来自 GetCustomerActivity 的结果,同时 将结果送达使用者。以后再调用时,GetCustomer BPEL 服务首先查找缓存,如果在缓存中找到目标数据,则直接从缓存中检索数据。在中间层内存中缓存 CustomerActivity 数据提升了数据访问速度。
到底应该如何从 BPEL 使用 Coherence 这一 SOA 编排语言呢?因为该制药公司使用中间层缓存的目标是实现可伸缩的性能,所以架构不能影响到效率。Oracle Coherence 提供了一个 Java API;通过标准 Web 服务接口实现从 BPEL 到 Coherence 的本机服务调用是首选的方法。调用 Web 服务操作的性能开销比调用本机 Java 类的性能开销要大几个数量级。这是因为编组和取消编组 XML、处理 SOAP 信封等都是开销很大的操作。
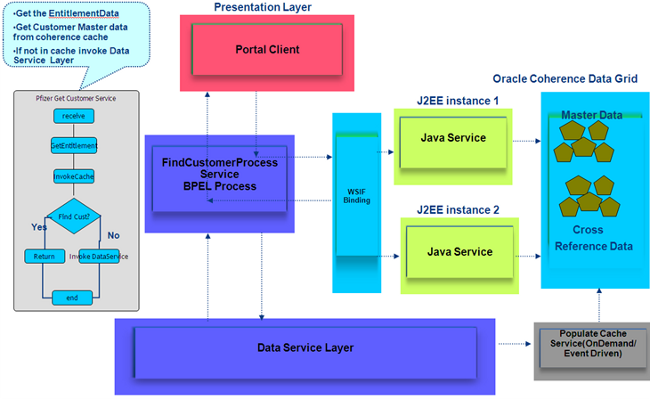
到 Java 资源的本机连接性不是 BPEL 的标准特性,但是 Oracle BPEL Process Manager (PM) 提供了专用于此目的解决方案 — WebServices 调用框架(WSIF) — 无需修改或扩展 BPEL 代码。Oracle BPEL 简明手册中详细介绍了如何结合使用 Oracle BPEL Process Manager 和 WSIF。在测试中,我们已经体验了利用 WSIF 绑定通过标准 Web 服务接口实现到 Oracle Coherence 的连接所带来的数量级的性能提高。
集成 Oracle BPEL PM 和 Oracle Coherence
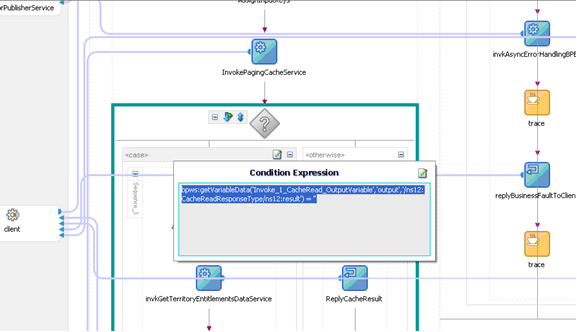
现在,我们快速浏览一下 GetCustomer BPEL 流程。如下面的图 8 所示,该流程首先检查缓存(另请参见图 10 中的条件)。如果缓存为空,该流程调用底层数据服务,否则,从缓存返回结果。
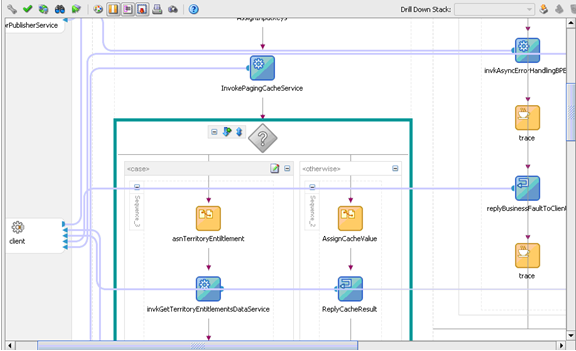
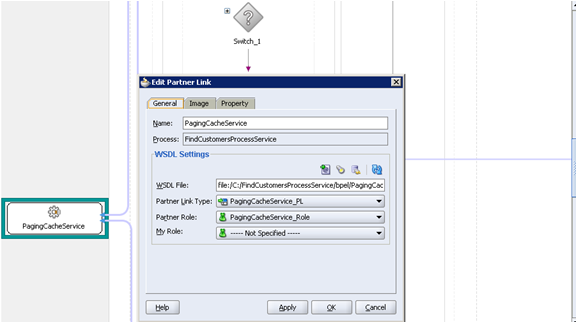
伙伴链接定义不同实体(在本例中为 Coherence Web 服务)如何与 BPEL 流程交互。每个伙伴链接与一个特定的 partnerLinkType 相关,以该 partnerLinkType 为特征。(参见图 9。)
InvokePagingCacheService 内部调用 Coherence WSIF Web 服务。ParnerLinkType 在 WSDL 文件中定义。
下面的图 10 说明了如何根据从 PagingCacheService 检索到的缓存值定义条件表达式。
既然我们已经了解了 BPEL 流程如何调用 Coherence 缓存服务,下面我们看一下如何创建这个缓存服务。简单说,该流程包括创建一个将从缓存读取/写入缓存的 Java 应用程序。然后,我们将这个 Java 应用程序封装为一个从 BPEL 流程调用的 Web 服务。
从实现的角度看,以下步骤是必须的:
- 为请求和响应创建模式并为缓存服务创建 WSDL
- 使用模式创建 Java 对象
- 为缓存服务创建 Java 实现类
- 创建 coherence_config.xml 以配置 coherence
- 将 coherence.jar 和 tangosol.jar 打包到 BPEL Jar 中
- 部署并验证流程
1. 为请求和响应创建模式并为缓存服务创建 WSDL
由于 BPEL 流程与其他 Web 服务通信,因此它在很大程度上依赖于组合 Web 服务所调用的 Web 服务的 WSDL 描述。
根据不同的客户模式,必须准备搜索请求模式和响应模式。例如,一个客户搜索请求将包含名字、姓氏、搜索类型等。响应将包含一个客户列表,其中包括每个客户的地址、订购的产品等。
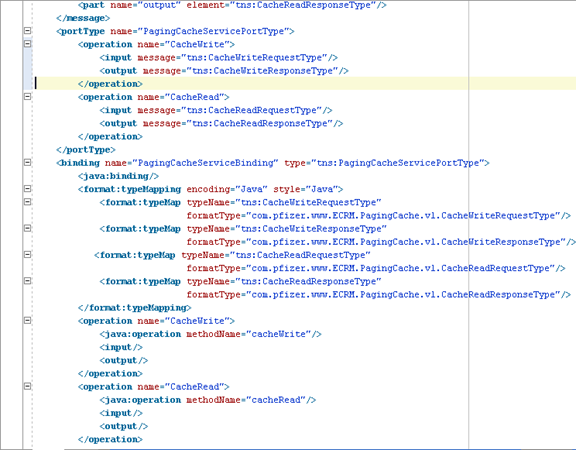
2. 使用模式创建 Java 对象
使用模式(SOA Suite 捆绑的实用程序)创建 Java 类,然后进行编译
3. 创建调用 Coherence 的 Java 实现类
这是 BPEL PM 服务将通过 WSIF 接口调用的 Java 应用程序。下面是读取 Coherence 缓存并向 BPEL PM 服务返回结果所需的 Java 代码的快照。相关的部分高亮显示为黄色。
public class CacheServiceImpl {
static NamedCache _customerQueryResultCache=null;
static {
/** Read coherence configuration file to initialize parameters like cache
expiration, eviction policy **/
System.setProperty("tangosol.coherence.cacheconfig", "coherence_config.xml");
Thread thread = Thread.currentThread();
ClassLoader loaderPrev = thread.getContextClassLoader();
try
{
thread.setContextClassLoader(com.tangosol.net.NamedCache.class.getClassLoader());
/** An instance of a cache is created from the CacheFactory class. This
instance, called CustomerQueryResultCache, is created using the getCache()
method of the CacheFactory class. Cache name GetCustomer.cache is mapped
to a distributed caching scheme.**/
_customerQueryResultCache = CacheFactory.getCache("GetCustomer.cache");
System.out.println("cache: "+_customerQueryResultCache);
}
finally
{
Thread.currentThread().setContextClassLoader(loaderPrev);
}
}
public CacheReadResponseType cacheRead(CacheReadRequestType input) throws
ApplicationFault, SystemFault, BusinessFault
{
String key = input.getInput().getKey();
CacheReadResponseType cacheResponseType = null;
/** A CustomerQueryResultCache is a java.util.Map that holds resources
shared across nodes in a cluster. Use the key (in this case customer id)
to retrieve the cache entry using the get() method) **/
CustomerQueryResultSet customerQueryResultSet =
(CustomerQueryResultSet)_customerQueryResultCache.get(key);
System.out.println(" Requested key Id is : " + key);
System.out.println(" Read from cache is : " + customerQueryResultSet);
cacheResponseType = CacheReadResponseTypeFactory.createFacade();
CacheReadResponse cacheResp =
CacheReadResponseFactory.createFacade();
if (customerQueryResultSet != null)
cacheResp.setCustomerQueryResultSet(customerQueryResultSet);
cacheResponseType.setResult(cacheResp);
return cacheResponseType;
}
}
4. 创建 coherence_config.xml 以配置 coherence
现在,我们设置缓存配置,包括逐出策略和缓存过期。我们将使用过期设置为 0 的分布式缓存,这样缓存数据永不会过期。否则,数据库中的数据变化时我们将更新缓存。
<distributed-scheme>
<scheme-name>default-distributed</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<local-scheme>
<scheme-ref>default-eviction</scheme-ref>
<!-- Eviction policy set to LRU, so that least recently used cache
data is evicted to make room for new cache -->
<eviction-policy>LRU</eviction-policy>
<high-units>0</high-units>
<!--Expiry set to 0, so that the cached data never expires. -->
<expiry-delay>0</expiry-delay>
</local-scheme>
</backing-map-scheme>
</distributed-scheme>
该 coherence_config.xml 文件应放在一个 jar 文件中并添加到项目库。(参见图 9。)
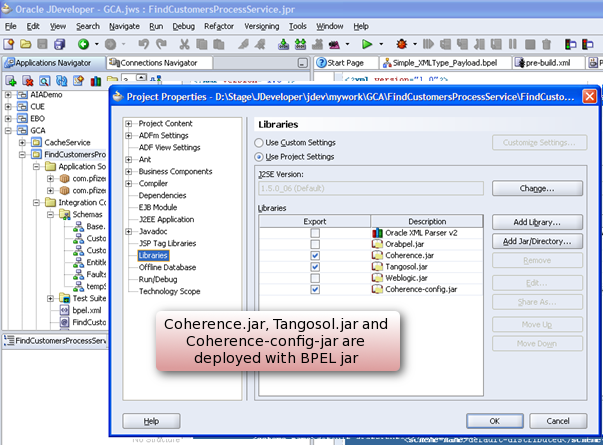
5. 将 coherence.jar 和 tangosol.jar 打包到 BPEL Jar 中
Coherence.jar 和 tangosol.jar 现在已经添加到项目库中,项目库是与 BPEL Jar 一起部署的,因此它位于 BPEL-INF/lib 中。(参见图 12。)
6. 部署并验证流程
流程一旦部署完成并进行了首次调用,流程将创建 cacheserver 并创建缓存 getCustomer.cache。此缓存映射到分布式缓存模式。从这个缓存实例读取/写入数据。
总结
通过使用 Oracle Coherence 实现中间层缓存,我们的组合应用程序获得了巨大的好处:
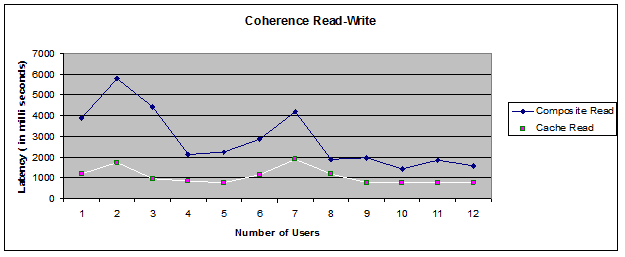
- 内部性能测试(参见图 13)显示来自缓存数据的响应速度提高了 30% 至 50%。此外,由于数据更接近应用服务器,因此容易获得并且免除了对数据库的访问。
- 增加了 GCA 组合应用程序的容错能力。在任何单个计算机或服务器发生故障时,数据始终可用。
- 提高了服务器硬件利用率,从而更高效地使用服务器容量。
- 减少了数据服务调用期间的数据编组/取消编组。
正如本文所演示的,使用复杂的中间层缓存解决方案可以提升 SOA 应用程序的性能。一个设计良好的缓存产品可以将复杂的分布式缓存和集群缓存机制隐藏起来,使 SOA 架构师/开发人员将注意力放在利用缓存上。这将带来额外的好处,包括由缓存冗余带来的可靠性提高,以及由无共享架构带来的线性缓存可伸缩性。
 | Kiran Dattani 是一家大型制药公司架构建设的财务和采购总监,他负责全球架构和企业集成项目。他还是公认的生命科学和制造行业的企业集成和供应链方面的专家,也是一位造诣颇深的演讲者。 |
 | Milind Pandit 是 Oracle Consulting Services 的 SOA 架构师,他负责协助客户部署基于 SOA 的架构。他在企业应用程序集成、J2EE 和面向对象的分析与设计方面的软件设计、开发和实现方面拥有 11 年的经验。 |
 | Markus Zirn 是 Oracle 融合中间件产品管理副总裁。他是《The BPEL Cookbook》的编辑,还撰写了几篇有关 SOA 及相关主题的文章,经常在行业领先的会议和分析师大会上发表演讲。 |