 系统管理员和开发人员
上机操作
系统管理员和开发人员
上机操作
如何使用 Oracle Solaris 搭建 Hadoop 集群
作者:Orgad Kimchi

如何使用 Oracle Solaris 区域、ZFS 和网络虚拟化技术搭建 Hadoop 集群。
2013 年 10 月发布
|
上机操作简介
前提条件
系统要求
上机操作练习概述
Hadoop 案例
练习 1:安装 Hadoop
练习 2:编辑 Hadoop 配置文件
练习 3:配置网络时间协议
练习 4:创建虚拟网络接口
练习 5:创建 NameNode 和辅助 NameNode 区域
练习 6:设置 DataNode 区域
练习 7:配置 NameNode
练习 8:设置 SSH
练习 9:从 NameNode 格式化 HDFS
练习 10:启动 Hadoop 集群
练习 11:运行 MapReduce 作业
练习 12:使用 ZFS 加密
练习 13:使用 Oracle Solaris DTrace 监视性能
总结
另请参见
关于作者
预计时长:180 分钟
上机操作简介
本上机操作所示练习演示如何使用 Oracle Solaris 区域、ZFS 和网络虚拟化等 Oracle Solaris 11 技术搭建 Apache Hadoop 集群。重要主题包括 Hadoop 分布式文件系统 (HDFS) 和 Hadoop MapReduce 编程模型。
我们还将介绍 Hadoop 安装过程和集群构建块:NameNode、辅助 NameNode 和 DataNode。此外,您还将看到如何结合使用 Oracle Solaris 11 技术以提高可扩展性和数据安全性,您还将了解如何将数据加载到 Hadoop 集群中和运行 MapReduce 作业。
前提条件
本上机操作适用于要在生产或开发环境中搭建或维护 Hadoop 集群的系统管理员。您必须具有基本的 Linux 或 Oracle Solaris 系统管理经验。无需事先了解 Hadoop。
系统要求
本上机操作在 Oracle VM VirtualBox 中的 Oracle Solaris 11 上运行。本上机操作是独立的。您所需的都在 Oracle VM VirtualBox 实例中。
对于参加甲骨文全球大会上机操作的读者,您的笔记本电脑上已经预加载了正确的 Oracle VM VirtualBox 映像。
如果您想在甲骨文全球大会之外尝试本上机操作,您将需要一个 Oracle Solaris 11 系统。执行以下操作设置计算机:
- 如果您没有 Oracle Solaris 11,请从这里下载。
- 下载 Oracle Solaris 11.1 VirtualBox 模板(文件大小 1.7GB)。
- 按照这里的说明安装模板。(注:在练习 2 第 4 步安装模板时,将 RAM 大小设置为 4 GB 可提高性能。)
甲骨文全球大会参会注意事项
- 每位参会者需自带笔记本电脑参加上机操作。
- 本上机操作的登录名和密码在“单页”中提供。
- Oracle Solaris 11 使用 GNOME 桌面。如果您用过 Linux 或其他 UNIX 操作系统桌面,应该熟悉本界面。如果您是初次接触本界面,以下是一些简要的基本知识。
- 要在 GNOME 桌面系统中打开终端窗口,请右键单击桌面背景,并在弹出菜单中选择 Open Terminal。
- 上机操作计算机上提供了以下源代码编辑器:vi(在终端窗口中键入
vi)和 emacs(在终端窗口中键入emacs)。
上机操作练习概述
本上机操作由 13 个练习组成,涵盖各种 Oracle Solaris 和 Apache Hadoop 技术:
- 安装 Hadoop。
- 编辑 Hadoop 配置文件。
- 配置网络时间协议。
- 创建虚拟网络接口 (VNIC)。
- 创建 NameNode 和辅助 NameNode 区域。
- 设置 DataNode 区域。
- 配置 NameNode。
- 设置 SSH。
- 从 NameNode 格式化 HDFS。
- 启动 Hadoop 集群。
- 运行 MapReduce 作业。
- 使用 ZFS 加密保护处于静止状态的数据。
- 使用 Oracle Solaris DTrace 监视性能。
Hadoop 案例
Apache Hadoop 软件是一个框架,允许使用简单编程模型分布式处理多个计算机集群上的大数据集。
为存储数据,Hadoop 使用了 Hadoop 分布式文件系统 (HDFS),它提供高吞吐量的应用数据访问,适合具有大数据集的应用。
有关 Hadoop 和 HDFS 的更多信息,请参见 http://hadoop.apache.org/。
Hadoop 集群构建块如下所示:
- NameNode:它是 HDFS 的核心组成部分,存储文件系统元数据,指示从属 DataNode 后台程序执行低级 I/O 任务,还运行 JobTracker 进程。
- 辅助 NameNode:对 NameNode 事务日志执行内部检查。
- DataNode:将数据存储到 HDFS 中的节点,又称从属节点,运行 TaskTracker 进程。
在本上机操作所示示例中,将使用 Oracle Solaris 区域、ZFS 和网络虚拟化技术安装所有 Hadoop 集群构建块。图 1 显示了架构:
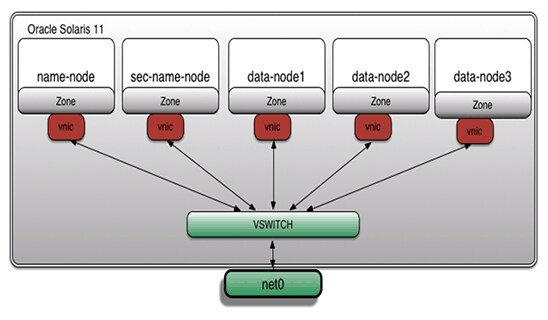
图 1
练习 1:安装 Hadoop
- 在 Oracle VM VirtualBox 中,在主机和来宾之间启用一个双向“共享剪贴板”,以便从此文件复制和粘贴文本。
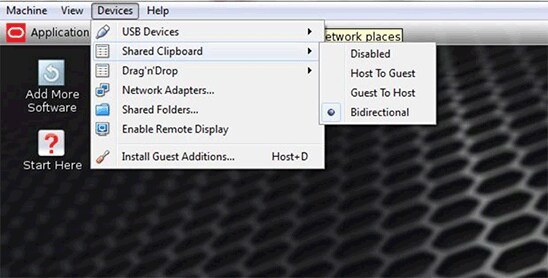
图 2
- 右键单击桌面背景中任一点,并在弹出菜单中选择 Open Terminal 打开终端窗口。
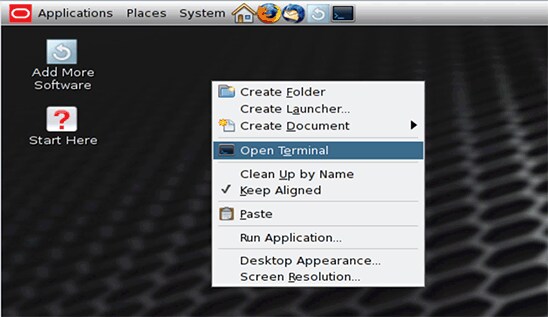
图 3
- 接下来,使用以下命令切换到
root用户。
注:对于甲骨文全球大会的参会者,本上机操作的单页中已经提供了 root 密码。对于在甲骨文全球大会之外运行本上机操作的读者,请输入您在“系统要求”一节中输入的 root 密码。
root@global_zone:~# su - Password: Oracle Corporation SunOS 5.11 11.1 September 2012
- 设置虚拟网络接口卡 (VNIC),以便从非全局区域启用对全局区域的网络访问。
注:甲骨文全球大会的参会者可以跳过此步骤(因为预加载的 Oracle VM VirtualBox 映像已经提供配置好的 VNIC),直接转到第 16 步“浏览上机操作补充资料”。
root@global_zone:~# dladm create-vnic -l net0 vnic0 root@global_zone:~# ipadm create-ip vnic0 root@global_zone:~# ipadm create-addr -T static -a local=192.168.1.100/24 vnic0/addr
- 验证 VNIC 创建:
root@global_zone:~# ipadm show-addr vnic0 ADDROBJ TYPE STATE ADDR vnic0/addr static ok 192.168.1.100/24
- 创建
hadoophol目录;我们将使用它存储与本上机操作相关的上机操作补充资料,如脚本和输入文件。
root@global_zone:~# mkdir -p /usr/local/hadoophol
- 创建
Bin目录;我们将在此处存放 Hadoop 二进制文件。
root@global_zone:~# mkdir /usr/local/hadoophol/Bin
- 在本上机操作中,我们将使用 Apache Hadoop“2013 年 7 月 23 日发布的 2013:1.2.1 版”。您可以使用 Web 浏览器下载 Hadoop 二进制文件。从桌面打开 Firefox web 浏览器并下载文件。
图 4
- 将 Hadoop tarball 复制到
/usr/local/hadoophol/Bin。
root@global_zone:~# cp /export/home/oracle/Downloads/hadoop-1.2.1.tar.gz /usr/local/hadoophol/Bin/
注:默认情况下,该文件将下载到用户的
Downloads目录中。 - 接下来,我们将创建上机操作脚本,为此创建一个目录:
root@global_zone:~# mkdir /usr/local/hadoophol/Scripts
- 使用您喜爱的编辑器创建
createzone脚本,如清单 1 所示。我们将使用此脚本设置 Oracle Solaris 区域。
root@global_zone:~# vi /usr/local/hadoophol/Scripts/createzone
清单 1#!/bin/ksh # FILENAME: createzone # Create a zone with a VNIC # Usage: # createzone <zone name> <VNIC> if [ $# != 2 ] then echo "Usage: createzone <zone name> <VNIC>" exit 1 fi ZONENAME=$1 VNICNAME=$2 zonecfg -z $ZONENAME > /dev/null 2>&1 << EOF create set autoboot=true set limitpriv=default,dtrace_proc,dtrace_user,sys_time set zonepath=/zones/$ZONENAME add fs set dir=/usr/local set special=/usr/local set type=lofs set options=[ro,nodevices] end add net set physical=$VNICNAME end verify exit EOF if [ $? == 0 ] ; then echo "Successfully created the $ZONENAME zone" else echo "Error: unable to create the $ZONENAME zone" exit 1 fi - 使用您喜爱的编辑器创建
verifycluster脚本,如清单 2 所示。我们将使用此脚本验证 Hadoop 集群设置。
root@global_zone:~# vi /usr/local/hadoophol/Scripts/verifycluster
清单 2#!/bin/ksh # FILENAME: verifycluster # Verify the hadoop cluster configuration # Usage: # verifycluster RET=1 for transaction in _; do for i in name-node sec-name-node data-node1 data-node2 data-node3 do cmd="zlogin $i ls /usr/local > /dev/null 2>&1 " eval $cmd || break 2 done for i in name-node sec-name-node data-node1 data-node2 data-node3 do cmd="zlogin $i ping name-node > /dev/null 2>&1" eval $cmd || break 2 done for i in name-node sec-name-node data-node1 data-node2 data-node3 do cmd="zlogin $i ping sec-name-node > /dev/null 2>&1" eval $cmd || break 2 done for i in name-node sec-name-node data-node1 data-node2 data-node3 do cmd="zlogin $i ping data-node1 > /dev/null 2>&1" eval $cmd || break 2 done for i in name-node sec-name-node data-node1 data-node2 data-node3 do cmd="zlogin $i ping data-node2 > /dev/null 2>&1" eval $cmd || break 2 done for i in name-node sec-name-node data-node1 data-node2 data-node3 do cmd="zlogin $i ping data-node3 > /dev/null 2>&1" eval $cmd || break 2 done RET=0 done if [ $RET == 0 ] ; then echo "The cluster is verified" else echo "Error: unable to verify the cluster" fi exit $RET - 创建
Doc目录;我们将在此处保存 Hadoop 输入文件。
root@global_zone:~# mkdir /usr/local/hadoophol/Doc
- 从 Project Gutenberg 下载使用 UTF-8 编码的纯文本文件形式的以下电子书:《The Outline of Science》,第 1 卷(共 4 卷),作者:Arthur Thomson。
- 将下载的文件 (
pg20417.txt) 复制到/usr/local/hadoophol/Doc目录。
root@global_zone:~# cp ~oracle/Downloads/pg20417.txt /usr/local/hadoophol/Doc/
- 通过在命令行键入以下命令,浏览上机操作补充资料:
root@global_zone:~# cd /usr/local/hadoophol
- 在命令行上键入
ls -l以查看目录内容:
root@global_zone:~# ls -l total 9 drwxr-xr-x 2 root root 2 Jul 8 15:11 Bin drwxr-xr-x 2 root root 2 Jul 8 15:11 Doc drwxr-xr-x 2 root root 2 Jul 8 15:12 Scripts
您将看到以下目录结构:
Bin— Hadoop 二进制文件位置Doc— Hadoop 输入文件Scripts— 上机操作脚本
- 在本上机操作中,我们将使用 Apache Hadoop“2013 年 7 月 23 日发布的 2013:1.2.1 版”。将 Hadoop tarball 复制到
/usr/local:
root@global_zone:~# cp /usr/local/hadoophol/Bin/hadoop-1.2.1.tar.gz /usr/local
- 解压缩 tarball:
root@global_zone:~# cd /usr/local root@global_zone:~# tar -xvfz /usr/local/hadoop-1.2.1.tar.gz
- 创建
hadoop组:
root@global_zone:~# groupadd hadoop
- 添加
hadoop用户:
root@global_zone:~# useradd -m -g hadoop hadoop
- 设置用户的 Hadoop 密码。您可以使用任何密码,但一定要记住自己的密码。
root@global_zone:~# passwd hadoop
- 为 Hadoop 二进制文件创建符号链接:
root@global_zone:~# ln -s /usr/local/hadoop-1.2.1 /usr/local/hadoop
- 授予
hadoop用户所有权:
root@global_zone:~# chown -R hadoop:hadoop /usr/local/hadoop*
- 更改权限:
root@global_zone:~# chmod -R 755 /usr/local/hadoop*
练习 2:编辑 Hadoop 配置文件
在本练习中,我们将编辑 Hadoop 配置文件,如表 1 所示:
表 1.Hadoop 配置文件| 文件名 | 说明 |
|---|---|
hadoop-env.sh | 指定 Hadoop 使用的环境变量设置。 |
core-site.xml | 指定所有 Hadoop 后台进程和客户端的相关参数。 |
mapred-site.xml | 指定 MapReduce 后台进程和客户端使用的参数。 |
masters | 包含运行辅助 NameNode 的计算机列表。 |
slaves | 包含运行 DataNode 和 TaskTracker 后台进程对的计算机名称列表。 |
要详细了解这些配置文件如何控制 Hadoop 框架,请参见 http://hadoop.apache.org/docs/r1.2.1/api/org/apache/hadoop/conf/Configuration.html。
- 运行以下命令,切换到
conf目录:
root@global_zone:~# cd /usr/local/hadoop/conf
- 运行以下命令,更改
hadoop-env.sh脚本:
注:集群配置将跨区域以只读文件系统的形式共享 Hadoop 目录结构 (
/usr/local/hadoop)。每个 Hadoop 集群节点都需要能够将其日志写入各自目录。/var/log/hadoop目录是适合每个 Oracle Solaris 区域的优秀实践目录。root@global_zone:~# echo "export JAVA_HOME=/usr/java" >> hadoop-env.sh root@global_zone:~# echo "export HADOOP_LOG_DIR=/var/log/hadoop" >> hadoop-env.sh
- 编辑
masters文件,用清单 3 所示代码行替换localhost条目:
root@global_zone:~# vi masters
清单 3sec-name-node
- 编辑
slaves文件,用清单 4 所示代码行替换localhost条目:
root@global_zone:~# vi slaves
清单 4data-node1 data-node2 data-node3
- 编辑
core-site.xml文件,应如清单 5 所示:
root@global_zone:~# vi core-site.xml
注:
清单 5fs.default.name是描述集群 NameNode 地址(协议指定符、主机名和端口)的 URI。每个 DataNode 实例均在此 NameNode 上注册,并通过它提供数据。此外,DataNode 还向 NameNode 发送心跳检测,以确认每个 DataNode 正在运行且其托管的块副本可用。<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://name-node</value> </property> </configuration> - 编辑
hdfs-site.xml文件,应如清单 6 所示:
root@global_zone:~# vi hdfs-site.xml
注:
dfs.data.dir是 DataNode 实例在本地文件系统上存储数据的路径。dfs.name.dir是 NameNode 实例在本地文件系统上存储 NameNode 元数据的路径。它仅供 NameNode 实例查找信息使用。dfs.replication是文件系统中每个数据块的默认复制因子。(对于生产集群,此因子通常应保留其默认值 3。)
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.data.dir</name> <value>/hdfs/data/</value> </property> <property> <name>dfs.name.dir</name> <value>/hdfs/name/</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration> - 编辑
mapred-site.xml文件,应如清单 7 所示:
root@global_zone:~# vi mapred-site.xml
注:
清单 7mapred.job.tracker是一个指定 JobTracker 的 RPC 地址的“主机:端口”字符串。<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapred.job.tracker</name> <value>name-node:8021</value> </property> </configuration>
练习 3:配置网络时间协议
我们应确保使用网络时间协议 (NTP) 同步 Hadoop 区域上的系统时钟。
注:建议选择可以作为专用时间同步源的 NTP 服务器,这样在关闭计算机进行计划维护时不会对其他服务产生负面影响。
在以下示例中,全局区域配置为 NTP 服务器。
- 配置 NTP 服务器:
root@global_zone:~# cd /etc/inet root@global_zone:~# cp ntp.server ntp.conf root@global_zone:~# chmod +w /etc/inet/ntp.conf root@global_zone:~# touch /var/ntp/ntp.drift
- 编辑 NTP 服务器配置文件,如清单 8 所示:
root@global_zone:~# vi /etc/inet/ntp.conf
清单 8server 127.127.1.0 prefer broadcast 224.0.1.1 ttl 4 enable auth monitor driftfile /var/ntp/ntp.drift statsdir /var/ntp/ntpstats/ filegen peerstats file peerstats type day enable filegen loopstats file loopstats type day enable filegen clockstats file clockstats type day enable keys /etc/inet/ntp.keys trustedkey 0 requestkey 0 controlkey 0
- 启用 NTP 服务器服务:
root@global_zone:~# svcadm enable ntp
- 使用以下命令验证 NTP 服务器是否在线:
root@global_zone:~# svcs -a | grep ntp online 16:04:15 svc:/network/ntp:default
练习 4:创建虚拟网络接口
概念突破:Oracle Solaris 11 网络虚拟化技术
为满足数据中心实施日益增长的需求,Oracle Solaris 提供了一种可靠、安全、可扩展的基础架构。其功能强大的网络架构(也叫做 Crossbow 项目)提供了以下功能。
- 通过虚拟 NIC (VNIC) 和虚拟交换实现的网络虚拟化
- 与 Oracle Solaris 区域和 Oracle Solaris 10 区域紧密集成
- 网络资源管理可以轻松高效地管理集成的 QoS,从而对 VNIC 和通信流强制执行带宽限制
- 优化的网络体系可对网络负载级别做出反应
- 能够构建“数据中心系统”
比如,与 1 Gb 的物理网络连接相比,同一系统上的 Oracle Solaris 区域可受益于极高的网络 I/O 吞吐容量(高达四倍速度)和极低的延迟。对于 Hadoop 集群,这意味着 DataNode 可大大提高 HDFS 块的复制速度。
有关网络虚拟化基准测试的详细信息,请参见“如何控制应用的网络带宽”。
- 为不同区域创建一系列虚拟网络接口 (VNIC):
root@global_zone:~# dladm create-vnic -l net0 name_node1 root@global_zone:~# dladm create-vnic -l net0 secondary_name1 root@global_zone:~# dladm create-vnic -l net0 data_node1 root@global_zone:~# dladm create-vnic -l net0 data_node2 root@global_zone:~# dladm create-vnic -l net0 data_node3
- 验证 VNIC 创建:
root@global_zone:~# dladm show-vnic LINK OVER SPEED MACADDRESS MACADDRTYPE VID name_node1 net0 1000 2:8:20:c6:3e:f1 random 0 secondary_name1 net0 1000 2:8:20:b9:80:45 random 0 data_node1 net0 1000 2:8:20:30:1c:3a random 0 data_node2 net0 1000 2:8:20:a8:b1:16 random 0 data_node3 net0 1000 2:8:20:df:89:81 random 0
我们可以看到现在有 5 个 VNIC。图 5 显示了架构布局:
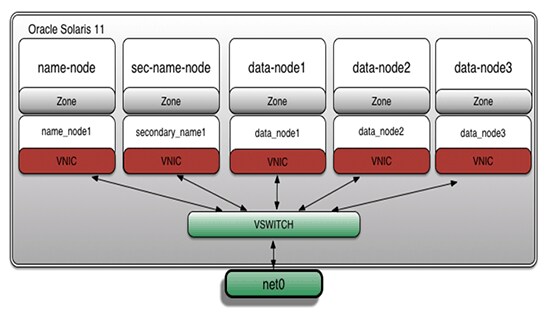
图 5
练习 5:创建 NameNode 和辅助 NameNode 区域
概念突破:Oracle Solaris 区域
Oracle Solaris 区域让您可以将一个应用与同一操作系统上的其他应用相隔离,从而允许您创建一个隔离环境,用户可登录该环境并从 Oracle Solaris 区域内部执行所需的操作,而不影响该区域外部的任何程序。此外,Oracle Solaris 区域还可以不受外部攻击和内部恶意程序的影响。每个 Oracle Solaris 区域都包含一个完整的资源受控环境,允许您分配 CPU、内存、网络和存储等资源。
如果您是系统管理员,可以选择严格管理所有 Oracle Solaris 区域,也可以将权限分配给特定 Oracle Solaris 区域的其他管理员。这种灵活性允许您对整个计算环境进行量身定制以满足特定应用的需要,全部在同一操作系统内实现。
有关 Oracle Solaris 区域的更多信息,请参见“如何开始在 Oracle Solaris 11 中创建 Oracle Solaris 区域”。
本上机操作中的所有 Hadoop 节点将使用 Oracle Solaris 区域安装。
- 如果 NameNode 和辅助 NameNode 区域还没有文件系统,请执行以下命令:
root@global_zone:~# zfs create -o mountpoint=/zones rpool/zones
- 验证是否创建了 ZFS 文件系统:
root@global_zone:~# zfs list rpool/zones NAME USED AVAIL REFER MOUNTPOINT rpool/zones 31K 51.4G 31K /zones
- 创建
name-node区域:
root@global_zone:~# zonecfg -z name-node Use 'create' to begin configuring a new zone. Zonecfg:name-node> create create: Using system default template 'SYSdefault' zonecfg:name-node> set autoboot=true zonecfg:name-node> set limitpriv=default,dtrace_proc,dtrace_user,sys_time zonecfg:name-node> set zonepath=/zones/name-node zonecfg:name-node> add fs zonecfg:name-node:fs> set dir=/usr/local zonecfg:name-node:fs> set special=/usr/local zonecfg:name-node:fs> set type=lofs zonecfg:name-node:fs> set options=[ro,nodevices] zonecfg:name-node:fs> end zonecfg:name-node> add net zonecfg:name-node:net> set physical=name_node1 zonecfg:name-node:net> end zonecfg:name-node> verify zonecfg:name-node> exit
(可选)您可以使用以下脚本创建
name-node区域,该脚本将创建区域配置文件。该脚本需要区域名称和 VNIC 名称作为参数,例如:createzone <区域名称> <VNIC 名称>。root@global_zone:~# /usr/local/hadoophol/Scripts/createzone name-node name_node1
- 创建
sec-name-node区域:
root@global_zone:~# zonecfg -z sec-name-node Use 'create' to begin configuring a new zone. Zonecfg:sec-name-node> create create: Using system default template 'SYSdefault' zonecfg:sec-name-node> set autoboot=true zonecfg:sec-name-node> set limitpriv=default,dtrace_proc,dtrace_user,sys_time zonecfg:sec-name-node> set zonepath=/zones/sec-name-node zonecfg:sec-name-node> add fs zonecfg:sec-name-node:fs> set dir=/usr/local zonecfg:sec-name-node:fs> set special=/usr/local zonecfg:sec-name-node:fs> set type=lofs zonecfg:sec-name-node:fs> set options=[ro,nodevices] zonecfg:sec-name-node:fs> end zonecfg:sec-name-node> add net zonecfg:sec-name-node:net> set physical=secondary_name1 zonecfg:sec-name-node:net> end zonecfg:sec-name-node> verify zonecfg:sec-name-node> exit
(可选)您可以使用以下脚本创建
sec-name-node区域,该脚本将创建区域配置文件。该脚本需要区域名称和 VNIC 名称作为参数,例如:createzone <区域名称> <VNIC 名称>。root@global_zone:~: /usr/local/hadoophol/Scripts/createzone sec-name-node secondary_name1
练习 6:设置 DataNode 区域
在本练习中,我们将利用 Oracle Solaris 区域虚拟化技术与 Oracle Solaris 中内置的 ZFS 文件系统的集成。
表 2 显示了我们将创建的 Hadoop 区域配置汇总:
表 2.区域汇总| 功能 | 区域名称 | ZFS 挂载点 | VNIC 名称 | IP 地址 |
|---|---|---|---|---|
| NameNode | name-node | /zones/name-node | name_node1 | 192.168.1.1 |
| 辅助 NameNode | sec-name-node | /zones/sec-name-node | secondary_name1 | 192.168.1.2 |
| DataNode | data-node1 | /zones/data-node1 | data_node1 | 192.168.1.3 |
| DataNode | data-node2 | /zones/data-node2 | data_node2 | 192.168.1.4 |
| DataNode | data-node3 | /zones/data-node3 | data_node3 | 192.168.1.5 |
- 创建
data-node1区域:
root@global_zone:~# zonecfg -z data-node1 Use 'create' to begin configuring a new zone. zonecfg:data-node1> create create: Using system default template 'SYSdefault' zonecfg:data-node1> set autoboot=true zonecfg:data-node1> set limitpriv=default,dtrace_proc,dtrace_user,sys_time zonecfg:data-node1> set zonepath=/zones/data-node1 zonecfg:data-node1> add fs zonecfg:data-node1:fs> set dir=/usr/local zonecfg:data-node1:fs> set special=/usr/local zonecfg:data-node1:fs> set type=lofs zonecfg:data-node1:fs> set options=[ro,nodevices] zonecfg:data-node1:fs> end zonecfg:data-node1> add net zonecfg:data-node1:net> set physical=data_node1 zonecfg:data-node1:net> end zonecfg:data-node1> verify zonecfg:data-node1> commit zonecfg:data-node1> exit
(可选)您可以使用以下脚本创建
data-node1区域:root@global_zone:~# /usr/local/hadoophol/Scripts/createzone data-node1 data_node1
- 创建
data-node2区域:
root@global_zone:~# zonecfg -z data-node2 Use 'create' to begin configuring a new zone. zonecfg:data-node2> create create: Using system default template 'SYSdefault' zonecfg:data-node2> set autoboot=true zonecfg:data-node2> set limitpriv=default,dtrace_proc,dtrace_user,sys_time zonecfg:data-node2> set zonepath=/zones/data-node2 zonecfg:data-node2> add fs zonecfg:data-node2:fs> set dir=/usr/local zonecfg:data-node2:fs> set special=/usr/local zonecfg:data-node2:fs> set type=lofs zonecfg:data-node2:fs> set options=[ro,nodevices] zonecfg:data-node2:fs> end zonecfg:data-node2> add net zonecfg:data-node2:net> set physical=data_node2 zonecfg:data-node2:net> end zonecfg:data-node2> verify zonecfg:data-node2> commit zonecfg:data-node2> exit
(可选)您可以使用以下脚本创建
data-node2区域:root@global_zone:~# /usr/local/hadoophol/Scripts/createzone data-node2 data_node2
- 创建
data-node3区域:
root@global_zone:~# zonecfg -z data-node3 Use 'create' to begin configuring a new zone. zonecfg:data-node3> create create: Using system default template 'SYSdefault' zonecfg:data-node3> set autoboot=true zonecfg:data-node3> set limitpriv=default,dtrace_proc,dtrace_user,sys_time zonecfg:data-node3> set zonepath=/zones/data-node3 zonecfg:data-node3> add fs zonecfg:data-node3:fs> set dir=/usr/local zonecfg:data-node3:fs> set special=/usr/local zonecfg:data-node3:fs> set type=lofs zonecfg:data-node3:fs> set options=[ro,nodevices] zonecfg:data-node3:fs> end zonecfg:data-node3> add net zonecfg:data-node3:net> set physical=data_node3 zonecfg:data-node3:net> end zonecfg:data-node3> verify zonecfg:data-node3> commit zonecfg:data-node3> exit
(可选)您可以使用以下脚本创建
data-node3区域:root@global_zone:~# /usr/local/hadoophol/Scripts/createzone data-node3 data_node3
练习 7:配置 NameNode
- 现在安装
name-node区域;稍后我们将克隆此区域,以提高区域的创建速度。
root@global_zone:~# zoneadm -z name-node install The following ZFS file system(s) have been created: rpool/zones/name-node Progress being logged to /var/log/zones/zoneadm.20130106T134835Z.name-node.install Image: Preparing at /zones/name-node/root. - 启动
name-node区域:
root@global_zone:~# zoneadm -z name-node boot
- 查看我们创建的区域的状态:
root@global_zone:~# zoneadm list -cv ID NAME STATUS PATH BRAND IP 0 global running / solaris shared 1 name-node running /zones/name-node solaris excl - sec-name-node configured /zones/sec-name-node solaris excl - data-node1 configured /zones/data-node1 solaris excl - data-node2 configured /zones/data-node2 solaris excl - data-node3 configured /zones/data-node3 solaris excl - 登录
name-node区域:
root@global_zone:~# zlogin -C name-node
- 使用
name-node区域的以下配置提供区域的主机信息:
- 主机名使用
name-node。 - 选择手动网络配置。
- 确保网络接口
name_node1的 IP 地址是 192.168.1.1,子网掩码是 255.255.255.0。 - 确保名称服务基于您的网络配置。在本上机操作中,我们将使用
/etc/hosts作名称解析,因此不会设置 DNS 进行主机名称解析。选择 Do not configure DNS。 - 对于 Alternate Name Service,选择 None。
- 对于 Time Zone Region,选择 Americas。
- 对于 Time Zone Location,选择 United States。
- 对于 Time Zone,选择 Pacific Time。
- 输入 root 密码。
- 主机名使用
- 完成区域设置之后,将出现登录提示。以
root用户身份登录区域。
name-node console login: root Password:
- Hadoop 开发需要 Java 编程环境。可以使用以下命令安装 Java Development Kit (JDK) 6:
root@name-node:~# pkg install jdk-6
- 验证 Java 安装:
root@name-node:~# which java /usr/bin/java root@name-node:~# java -version java version "1.6.0_35" Java(TM) SE Runtime Environment (build 1.6.0_35-b10) Java HotSpot(TM) Client VM (build 20.10-b01, mixed mode)
- 在
name-node区域内创建一个 Hadoop 用户:
root@name-node:~# groupadd hadoop root@name-node:~# useradd -m -g hadoop hadoop root@name-node:~# passwd hadoop
注:密码应与您在练习 1 第 22 步中设置用户的 Hadoop 密码时输入的密码相同。
- 创建 Hadoop 日志文件目录:
root@name-node:~# mkdir /var/log/hadoop root@name-node:~# chown hadoop:hadoop /var/log/hadoop
- 配置 NTP 客户端,如以下示例所示:
- 安装 NTP 软件包:
root@name-node:~# pkg install ntp
- 创建 NTP 客户端配置文件:
root@name-node:~# cd /etc/inet root@name-node:~# cp ntp.client ntp.conf root@name-node:~# chmod +w /etc/inet/ntp.conf root@name-node:~# touch /var/ntp/ntp.drift
- 编辑 NTP 客户端配置文件,如清单 9 所示:
root@name-node:~# vi /etc/inet/ntp.conf
注:在本上机操作中,我们将使用全局区域作为时间服务器,因此将其名称(例如
清单 9global-zone)添加到/etc/inet/ntp.conf。server global-zone prefer driftfile /var/ntp/ntp.drift statsdir /var/ntp/ntpstats/ filegen peerstats file peerstats type day enable filegen loopstats file loopstats type day enable
- 安装 NTP 软件包:
- 在
/etc/hosts中添加 Hadoop 集群成员的主机名和 IP 地址,如清单 10 所示:
root@name-node:~# vi /etc/hosts
清单 10::1 localhost 127.0.0.1 localhost loghost 192.168.1.1 name-node 192.168.1.2 sec-name-node 192.168.1.3 data-node1 192.168.1.4 data-node2 192.168.1.5 data-node3 192.168.1.100 global-zone
- 启用 NTP 客户端服务:
root@name-node:~# svcadm enable ntp
- 验证 NTP 客户端状态:
root@name-node:~# svcs ntp STATE STIME FMRI online 11:15:59 svc:/network/ntp:default
- 检查 NTP 客户端的时钟能否与 NTP 服务器同步:
root@name-node:~# ntpq -p
练习 8:设置 SSH
- 在
name-node区域上为 Hadoop 用户设置基于 SSH 密钥的身份验证,以便实现无密码登录辅助 DataNode 和 DataNode:
root@name-node:~# su - hadoop hadoop@name-node $ ssh-keygen -t dsa -P "" -f ~/.ssh/id_dsa hadoop@name-node $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
- 编辑
$HOME/.profile,在该文件的末尾添加如清单 11 所示的以下代码行:
hadoop@name-node $ vi $HOME/.profile
清单 11# Set JAVA_HOME export JAVA_HOME=/usr/java # Add Hadoop bin/ directory to PATH export PATH=$PATH:/usr/local/hadoop/bin
然后运行以下命令:
hadoop@name-node $ source $HOME/.profile
- 键入以下命令检查 Hadoop 是否运行:
hadoop@name-node:~$ hadoop version Hadoop 1.2.1 Subversion https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1503152 Compiled by mattf on Mon Jul 22 15:23:09 PDT 2013 From source with checksum 6923c86528809c4e7e6f493b6b413a9a
注:按
~.退出name-node控制台并返回全局区域。可以使用
zonename命令验证是否在全局区域中:root@global_zone:~# zonename global
- 在全局区域运行以下命令创建
sec-name-node区域,作为name-node的克隆:
root@global_zone:~# zoneadm -z name-node shutdown root@global_zone:~# zoneadm -z sec-name-node clone name-node
- 启动
sec-name-node区域:
root@global_zone:~# zoneadm -z sec-name-node boot root@global_zone:~# zlogin -C sec-name-node
- 与前面一样,系统配置工具启动(参见图 6),然后执行
sec-name-node区域的最终配置:
注:所有区域的时区配置和 root 密码都必须相同。
图 6
- 主机名使用
sec-name-node。 - 选择手动网络配置,网络接口使用
secondary_name1。 - 使用 IP 地址 192.168.1.2 和子网掩码 255.255.255.0。
- 在 DNS 名称服务窗口中选择 Do not configure DNS。
- 确保 Alternate Name Service 设置为 none。
- 对于 Time Zone Region,选择 Americas。
- 对于 Time Zone Location,选择 United States。
- 对于 Time Zone,选择 Pacific Time。
- 输入 root 密码。
注:按
~.退出sec-name-node控制台并返回全局区域。
- 主机名使用
- 对
data-node1、data-node2和data-node3执行类似步骤:
- 对
data-node1执行以下操作:
root@global_zone:~# zoneadm -z data-node1 clone name-node root@global_zone:~# zoneadm -z data-node1 boot root@global_zone:~# zlogin -C data-node1
- 主机名使用
data-node1。 - 选择手动网络配置,网络接口使用
data_node1。 - 使用 IP 地址 192.168.1.3 和子网掩码 255.255.255.0。
- 在 DNS 名称服务窗口中选择 Do not configure DNS。
- 确保 Alternate Name Service 设置为 none。
- 对于 Time Zone Region,选择 Americas。
- 对于 Time Zone Location,选择 United States。
- 对于 Time Zone,选择 Pacific Time。
- 输入 root 密码。
- 主机名使用
- 对
data-node2执行以下操作:
root@global_zone:~# zoneadm -z data-node2 clone name-node root@global_zone:~# zoneadm -z data-node2 boot root@global_zone:~# zlogin -C data-node2
- 主机名使用
data-node2。 - 网络接口使用
data_node2。 - 使用 IP 地址 192.168.1.4 和子网掩码 255.255.255.0。
- 在 DNS 名称服务窗口中选择 Do not configure DNS。
- 确保 Alternate Name Service 设置为 none。
- 对于 Time Zone Region,选择 Americas。
- 对于 Time Zone Location,选择 United States。
- 对于 Time Zone,选择 Pacific Time。
- 输入 root 密码。
- 主机名使用
- 对
data-node3执行以下操作:
root@global_zone:~# zoneadm -z data-node3 clone name-node root@global_zone:~# zoneadm -z data-node3 boot root@global_zone:~# zlogin -C data-node3
- 主机名使用
data-node3。 - 网络接口使用
data_node3。 - 使用 IP 地址 192.168.1.5 和子网掩码 255.255.255.0。
- 在 DNS 名称服务窗口中选择 Do not configure DNS。
- 确保 Alternate Name Service 设置为 none。
- 对于 Time Zone Region,选择 Americas。
- 对于 Time Zone Location,选择 United States。
- 对于 Time Zone,选择 Pacific Time。
- 输入 root 密码。
- 主机名使用
- 对
- 启动
name_node区域:
root@global_zone:~# zoneadm -z name-node boot
- 验证所有区域是否启动和运行:
root@global_zone:~# zoneadm list -cv ID NAME STATUS PATH BRAND IP 0 global running / solaris shared 10 sec-name-node running /zones/sec-name-node solaris excl 12 data-node1 running /zones/data-node1 solaris excl 14 data-node2 running /zones/data-node2 solaris excl 16 data-node3 running /zones/data-node3 solaris excl 17 name-node running /zones/name-node solaris excl
- 要在不使用 Hadoop 用户密码的情况下验证 SSH 访问,请执行以下操作:
- 从
name_node通过 SSH 登录name-node(即登录到自己):
root@global_zone:~# zlogin name-node root@name-node:~# su - hadoop hadoop@name-node $ ssh name-node The authenticity of host 'name-node (192.168.1.1)' can't be established. RSA key fingerprint is 04:93:a9:e0:b7:8c:d7:8b:51:b8:42:d7:9f:e1:80:ca. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'name-node,192.168.1.1' (RSA) to the list of known hosts.
- 现在尝试登录到
sec-name-node和 DataNode(data-node1、data-node2和data-node3)。 - 使用 SSH 再次尝试登录主机。应该就不会提示您将主机添加到已知密钥列表了。
- 从
- 编辑
sec-name-node和 DataNode 内的/etc/hosts文件,添加name-node条目:
root@global_zone:~# zlogin sec-name-node 'echo "192.168.1.1 name-node" >> /etc/hosts' root@global_zone:~# zlogin data-node1 'echo "192.168.1.1 name-node" >> /etc/hosts' root@global_zone:~# zlogin data-node2 'echo "192.168.1.1 name-node" >> /etc/hosts' root@global_zone:~# zlogin data-node3 'echo "192.168.1.1 name-node" >> /etc/hosts'
- 验证名称解析,确保全局区域和所有 Hadoop 区域的
/etc/hosts文件中均包含如清单 12 所示的主机条目:
# cat /etc/hosts
清单 12::1 localhost 127.0.0.1 localhost loghost 192.168.1.1 name-node 192.168.1.2 sec-name-node 192.168.1.3 data-node1 192.168.1.4 data-node2 192.168.1.5 data-node3 192.168.1.100 global-zone
注:如果您使用全局区域作为 NTP 服务器,还必须将其主机名和 IP 地址添加到
/etc/hosts。 - 使用
verifycluster脚本验证集群:
root@global_zone:~# /usr/local/hadoophol/Scripts/verifycluster
如果集群设置正确,您将收到一条
cluster is verified消息。注:如果
verifycluster脚本失败并显示错误消息,请检查每个区域中的/etc/hosts文件,看看是否包含所有区域名称,如第 12 步所述,然后再次运行verifiability脚本。
练习 9:从 NameNode 格式化 HDFS
概念突破:Hadoop 分布式文件系统 (HDFS)
HDFS 是一种分布式、可扩展的文件系统。HDFS 将元数据存储在 NameNode 上。应用数据存储在 DataNode 上,每个 DataNode 使用 HDFS 特定的块协议通过网络提供数据块。文件系统使用 TCP/IP 层通信。客户端使用远程过程调用 (RPC) 相互通信。
DataNode 并不依赖于数据保护机制(如 RAID)来确保数据持久性。而是将文件内容复制到多个 DataNode 上以提高可靠性。
使用 hdfs-site.xml 文件中设置的默认复制值 (3),数据将存储在三个节点上。DataNode 可以相互通信,以便重新平衡数据、到处移动副本以及保持较多的数据副本。在图 7 中,我们可以看到每个数据块根据复制值在三个数据节点之间复制。
使用 HDFS 的一个好处是 JobTracker 和 TaskTracker 之间的数据感知。JobTracker 将映射或归约作业安排给 TaskTracker,同时可以感知数据位置。例如,如果节点 A 包含数据 (x,y,z),节点 B 包含数据 (a,b,c)。然后 JobTracker 将安排节点 B 对 (a,b,c) 执行映射或归约任务,安排节点 A 对 (x,y,z) 执行映射或归约任务。这减少了网络上的流量,并防止不必要的数据传输。这种数据感知可以对作业完成时间产生重大影响,运行数据密集型作业时已经体现出来。
有关 Hadoop HDFS 的更多信息,请参见 https://en.wikipedia.org/wiki/Hadoop。
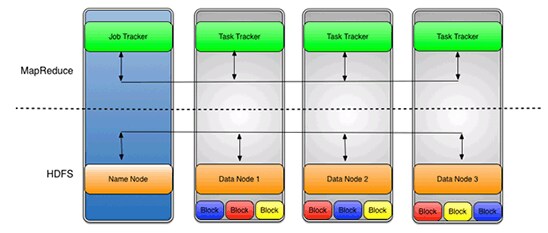
图 7
- 要格式化 HDFS,请运行以下命令并在提示符下回答 Y:
root@global_zone:~# zlogin name-node root@name-node:~# mkdir -p /hdfs/name root@name-node:~# chown -R hadoop:hadoop /hdfs root@name-node:~# su - hadoop hadoop@name-node:$ /usr/local/hadoop/bin/hadoop namenode -format 13/10/13 09:10:52 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = name-node/192.168.1.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 1.2.1 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1503152; compiled by 'mattf' on Mon Jul 22 15:23:09 PDT 2013 STARTUP_MSG: java = 1.6.0_35 ************************************************************/ hadoop@name-node:$ Re-format filesystem in /hdfs/name ? (Y or N) Y
- 在每个 DataNode(
data-node1、data-node2和data-node3)上,创建一个 Hadoop 数据目录来存储 HDFS 块:
root@global_zone:~# zlogin data-node1 root@data-node1:~# mkdir -p /hdfs/data root@data-node1:~# chown -R hadoop:hadoop /hdfs root@global_zone:~# zlogin data-node2 root@data-node2:~# mkdir -p /hdfs/data root@data-node2:~# chown -R hadoop:hadoop /hdfs root@global_zone:~# zlogin data-node3 root@data-node3:~# mkdir -p /hdfs/data root@data-node3:~# chown -R hadoop:hadoop /hdfs
练习 10:启动 Hadoop 集群
表 3 描述了启动脚本。
表 3.启动脚本| 文件名 | 说明 |
|---|---|
start-dfs.sh | 启动 HDFS 后台进程、NameNode 和 DataNode。此脚本要在 start-mapred.sh 之前使用。 |
stop-dfs.sh | 停止 Hadoop DFS 后台进程。 |
start-mapred.sh | 启动 Hadoop MapReduce 后台进程、JobTracker 和 TaskTracker。 |
stop-mapred.sh | 停止 Hadoop MapReduce 后台进程。 |
- 在
name-node区域中,使用以下命令启动 Hadoop DFS 后台进程、NameNode 和 DataNode。
root@global_zone:~# zlogin name-node root@name-node:~# su - hadoop hadoop@name-node:$ start-dfs.sh starting namenode, logging to /var/log/hadoop/hadoop--namenode-name-node.out data-node2: starting datanode, logging to /var/log/hadoop/hadoop-hadoop-datanode-data-node2.out data-node1: starting datanode, logging to /var/log/hadoop/hadoop-hadoop-datanode-data-node1.out data-node3: starting datanode, logging to /var/log/hadoop/hadoop-hadoop-datanode-data-node3.out sec-name-node: starting secondarynamenode, logging to /var/log/hadoop/hadoop-hadoop-secondarynamenode-sec-name-node.out
- 使用以下命令启动 Hadoop Map/Reduce 后台进程、JobTracker 和 TaskTracker:
hadoop@name-node:$ start-mapred.sh starting jobtracker, logging to /var/log/hadoop/hadoop--jobtracker-name-node.out data-node1: starting tasktracker, logging to /var/log/hadoop/hadoop-hadoop-tasktracker-data-node1.out data-node3: starting tasktracker, logging to /var/log/hadoop/hadoop-hadoop-tasktracker-data-node3.out data-node2: starting tasktracker, logging to /var/log/hadoop/hadoop-hadoop-tasktracker-data-node2.out
- 要查看全面的状态报告,请执行以下命令查看集群状态。该命令将输出有关集群运行状况的基本统计信息,如 NameNode 详细信息、每个 DataNode 的状态以及磁盘容量。
hadoop@name-node:$ hadoop dfsadmin -report Configured Capacity: 171455269888 (159.68 GB) Present Capacity: 169711053357 (158.06 GB) DFS Remaining: 169711028736 (158.06 GB) DFS Used: 24621 (24.04 KB) DFS Used%: 0% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 ------------------------------------------------- Datanodes available: 3 (3 total, 0 dead) ...
您将看到三个可用的 DataNode。
注:您可以在地址为
http://<NameNode IP 地址>:50070/dfshealth.jsp的 NameNode web 状态页面(如图 8 所示)上找到同样的信息。名称节点 IP 地址为 192.168.1.1。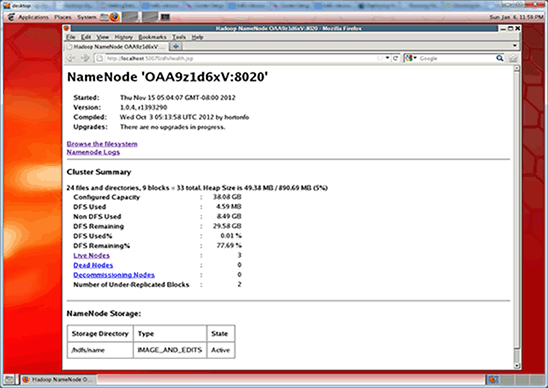
图 8
练习 11:运行 MapReduce 作业
概念突破:MapReduce
MapReduce 是一个使用计算机集群针对大规模数据集处理可并行问题的框架。
MapReduce 的基本思想是使用两个函数从源提取数据:使用 Map() 函数,然后使用 Reduce() 函数处理计算机集群中的数据。具体来说,Map() 将对数据集中的所有成员应用一个函数并发布结果集,然后由 Reduce() 整理并解析该结果集。
Map() 和 Reduce() 可以跨多个系统并行运行。
有关 MapReduce 的更多信息,请参见 http://en.wikipedia.org/wiki/MapReduce。
我们将使用 WordCount 示例,该示例读取文本文件并计算用词频率。输入和输出均由文本文件组成,其中每行包含一个单词以及该词使用的次数,使用制表符分隔。有关 WordCount 的更多信息,请参见 http://wiki.apache.org/hadoop/WordCount。
- 创建输入数据目录;我们将在此处放置输入文件。
hadoop@name-node:$ hadoop fs -mkdir /input-data
- 验证是否创建了目录:
hadoop@name-node:$ hadoop dfs -ls / Found 1 items drwxr-xr-x - hadoop supergroup 0 2013-10-13 23:45 /input-data
- 使用以下命令将先前下载的
pg20417.txt文件复制到 HDFS:
注:甲骨文全球大会的参会者可以在
/usr/local/hadoophol/Doc目录中找到pg20417.txt文件。hadoop@name-node:$ hadoop dfs -copyFromLocal /usr/local/hadoophol/Doc/pg20417.txt /input-data
- 验证文件位于 HDFS 上:
hadoop@name-node:$ hadoop dfs -ls /input-data Found 1 items -rw-r--r-- 3 hadoop supergroup 674570 2013-10-13 10:20 /input-data/pg20417.txt
- 创建输出目录;MapReduce 作业将在此目录中放置输出:
hadoop@name-node:$ hadoop fs -mkdir /output-data
- 使用以下命令启动 MapReduce 作业:
hadoop@name-node:$ hadoop jar /usr/local/hadoop/hadoop-examples-1.2.1.jar wordcount /input-data/pg20417.txt /output-data/output1 13/10/13 10:23:08 INFO input.FileInputFormat: Total input paths to process : 1 13/10/13 10:23:08 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 13/10/13 10:23:08 WARN snappy.LoadSnappy: Snappy native library not loaded 13/10/13 10:23:09 INFO mapred.JobClient: Running job: job_201310130918_0010 13/10/13 10:23:10 INFO mapred.JobClient: map 0% reduce 0% 13/10/13 10:23:19 INFO mapred.JobClient: map 100% reduce 0% 13/10/13 10:23:29 INFO mapred.JobClient: map 100% reduce 33% 13/10/13 10:23:31 INFO mapred.JobClient: map 100% reduce 100% 13/10/13 10:23:34 INFO mapred.JobClient: Job complete: job_201310130918_0010 13/10/13 10:23:34 INFO mapred.JobClient: Counters: 26
该程序在集群上执行用时约 60 秒。
读取输入目录(以上所示命令行中的
input-data)中的所有文件,并将输入中的字数写入输出目录(名为output-data/output1)。 - 验证输出数据:
hadoop@name-node:$ hadoop dfs -ls /output-data/output1 Found 3 items -rw-r--r-- 3 hadoop supergroup 0 2013-10-13 10:30 /output-data/output1/_SUCCESS drwxr-xr-x - hadoop supergroup 0 2013-10-13 10:30 /output-data/output1/_logs -rw-r--r-- 3 hadoop supergroup 196192 2013-10-13 10:30 /output-data/output1/part-r-00000
练习 12:使用 ZFS 加密
概念突破:ZFS 加密
Oracle Solaris 11 为 ZFS 添加了透明数据加密功能。所有数据和文件系统元数据(如所有权、访问控制列表、配额信息等等)永久存储在 ZFS 池中时均经过加密。
ZFS 池可以同时支持加密和非加密的 ZFS 数据集(文件系统和 ZVOL)。数据加密对应用和其他 Oracle Solaris 文件服务(如 NFS 或 CIFS)完全透明。由于加密是 ZFS 的优秀特性,我们可以同时支持压缩、加密和重复数据消除。加密数据集的加密密钥管理可以委托给用户和/或 Oracle Solaris 区域。具有 ZFS 加密功能的 Oracle Solaris 提供了一个非常灵活的系统来保护处于静止状态的数据,不需要任何应用更改或资格。
有关 ZFS 加密的更多信息,请参见“如何管理 ZFS 数据加密”。
输出数据可能包含敏感信息,因此请使用 ZFS 加密保护输出数据。
- 创建加密 ZFS 数据集:
注:您需要提供密码短语;密码短语至少包括 8 个字符。
root@name-node:~# zfs create -o encryption=on rpool/export/output Enter passphrase for 'rpool/export/output': Enter again:
- 验证 ZFS 数据集是否加密:
root@name-node:~# zfs get all rpool/export/output | grep encry rpool/export/output encryption on local
- 更改所有权:
root@name-node:~# chown hadoop:hadoop /export/output
- 将输出文件从 HDFS 复制到 ZFS:
root@name-node:~# su - hadoop Oracle Corporation SunOS 5.11 11.1 September 2012 hadoop@name-node:$ hadoop dfs -getmerge /output-data/output1 /export/output
- 分析输出文本文件。每行包含一个单词以及该词使用的次数,使用制表符分隔。
hadoop@name-node:$ head /export/output/output1 "A 2 "Alpha 1 "Alpha," 1 "An 2 "And 1 "BOILING" 2 "Batesian" 1 "Beta 2
- 通过卸载 ZFS 数据集保护输出文本文件,然后使用以下命令卸载加密数据集的封装密钥:
root@name-node:~# zfs key -u rpool/export/output
如果命令成功,该数据集不可访问,并将卸载。
- 如果要挂载该 ZFS 文件系统,需要提供密码短语:
root@name-node:~# zfs mount rpool/export/output Enter passphrase for 'rpool/export/output':
通过使用密码短语,可确保只有知道密码短语的人才能查看输出文件。
练习 13:使用 Oracle Solaris DTrace 监视性能
概念突破:Oracle Solaris DTrace
Oracle Solaris DTrace 是一个全面的高级跟踪工具,用于对系统性问题进行实时故障排除。管理员、集成商和开发人员可以使用 DTrace 动态、安全地观察实时生产系统中(包括应用和操作系统本身)的性能问题。
DTrace 可帮助您了解系统的工作方式、跟踪众多软件层中的问题以及确定异常行为的原因。无论是内存消耗或 CPU 时间这种高级别全局概览,还是正在进行的具体函数调用这种更细粒度的信息,DTrace 均可通过以下功能为数据中心提供长久以来一直缺少的业务运营洞察:
- 插入涵盖操作系统方方方面的 80000 多个探测点。
- 插装用户和系统级软件。
- 使用强大、易于使用的脚本语言和命令行界面。
有关 DTrace 的更多信息,请参见 http://www.oracle.com/technetwork/cn/server-storage/solaris11/technologies/dtrace-1930301-zhs.html。
- 打开另一个终端窗口并以
hadoop用户身份登录name-node。 - 运行以下 MapReduce 作业:
hadoop@name-node:$ hadoop jar /usr/local/hadoop/hadoop-examples-1.2.1.jar wordcount /input-data/pg20417.txt /output-data/output2
- Hadoop 作业运行时,确定在 NameNode 上执行哪些进程。
在终端窗口中,运行以下 DTrace 命令:
root@global-zone:~# dtrace -n 'proc:::exec-success/strstr(zonename,"name-node")>0/ { trace(curpsinfo->pr_psargs); }' dtrace: description 'proc:::exec-success' matched 1 probe CPU ID FUNCTION:NAME 0 4473 exec_common:exec-success /usr/bin/env bash /usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/hadoop-exa 0 4473 exec_common:exec-success bash /usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/hadoop-examples-1.1.2.j 0 4473 exec_common:exec-success dirname /usr/local/hadoop-1.1.2/libexec/-- 0 4473 exec_common:exec-success dirname /usr/local/hadoop-1.1.2/libexec/-- 0 4473 exec_common:exec-success sed -e s/ /_/g 1 4473 exec_common:exec-success dirname /usr/local/hadoop/bin/hadoop 1 4473 exec_common:exec-success dirname -- /usr/local/hadoop/bin/../libexec/hadoop-config.sh 1 4473 exec_common:exec-success basename -- /usr/local/hadoop/bin/../libexec/hadoop-config.sh 1 4473 exec_common:exec-success basename /usr/local/hadoop-1.1.2/libexec/-- 1 4473 exec_common:exec-success uname 1 4473 exec_common:exec-success /usr/java/bin/java -Xmx32m org.apache.hadoop.util.PlatformName 1 4473 exec_common:exec-success /usr/java/bin/java -Xmx32m org.apache.hadoop.util.PlatformName 0 4473 exec_common:exec-success /usr/java/bin/java -Dproc_jar -Xmx1000m -Dhadoop.log.dir=/var/log/hadoop -Dhado 0 4473 exec_common:exec-success /usr/java/bin/java -Dproc_jar -Xmx1000m -Dhadoop.log.dir=/var/log/hadoop -Dhado ^C
注:按 Ctrl-c 可查看 DTrace 输出。
- Hadoop 作业运行时,确定将哪些文件写入 NameNode。
注:如果 MapReduce 作业完成,您可以使用不同输出目录运行其他作业(例如
/output-data/output3)。例如:
hadoop@name-node:$ hadoop jar /usr/local/hadoop/hadoop-examples-1.2.1.jar wordcount /input-data/pg20417.txt /output-data/output3
root@global-zone:~# dtrace -n 'syscall::write:entry/strstr(zonename,"name-node")>0/ {@write[fds[arg0].fi_pathname]=count();}' dtrace: description 'syscall::write:entry' matched 1 probe ^C /zones/name-node/root/tmp/hadoop-hadoop/mapred/local/jobTracker/.job_201307181457_0007.xml.crc 1 /zones/name-node/root/var/log/hadoop/history/.job_201307181457_0007_conf.xml.crc 1 /zones/name-node/root/dev/pts/3 5 /zones/name-node/root/var/log/hadoop/job_201307181457_0007_conf.xml 6 /zones/name-node/root/tmp/hadoop-hadoop/mapred/local/jobTracker/job_201307181457_0007.xml 8 /zones/name-node/root/var/log/hadoop/history/job_201307181457_0007_conf.xml 11 /zones/name-node/root/var/log/hadoop/hadoop--jobtracker-name-node.log 13 /zones/name-node/root/hdfs/name/current/edits.new 25 /zones/name-node/root/var/log/hadoop/hadoop--namenode-name-node.log 45 /zones/name-node/root/dev/poll 207 <unknown> 3131655
注:按 Ctrl-c 可查看 DTrace 输出。
- Hadoop 作业运行时,确定在 DataNode 上执行哪些进程:
root@global-zone:~# dtrace -n 'proc:::exec-success/strstr(zonename,"data-node1")>0/ { trace(curpsinfo->pr_psargs); }' dtrace: description 'proc:::exec-success' matched 1 probe CPU ID FUNCTION:NAME 0 8833 exec_common:exec-success dirname /usr/local/hadoop/bin/hadoop 0 8833 exec_common:exec-success dirname /usr/local/hadoop/libexec/-- 0 8833 exec_common:exec-success sed -e s/ /_/g 1 8833 exec_common:exec-success dirname -- /usr/local/hadoop/bin/../libexec/hadoop-config.sh 2 8833 exec_common:exec-success basename /usr/local/hadoop/libexec/-- 2 8833 exec_common:exec-success /usr/java/bin/java -Xmx32m org.apache.hadoop.util.PlatformName 2 8833 exec_common:exec-success /usr/java/bin/java -Xmx32m org.apache.hadoop.util.PlatformName 3 8833 exec_common:exec-success /usr/bin/env bash /usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/hadoop-exa 3 8833 exec_common:exec-success bash /usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/hadoop-examples-1.0.4.j 3 8833 exec_common:exec-success basename -- /usr/local/hadoop/bin/../libexec/hadoop-config.sh 3 8833 exec_common:exec-success dirname /usr/local/hadoop/libexec/-- 3 8833 exec_common:exec-success uname 3 8833 exec_common:exec-success /usr/java/bin/java -Dproc_jar -Xmx1000m -Dhadoop.log.dir=/var/log/hadoop -Dhado 3 8833 exec_common:exec-success /usr/java/bin/java -Dproc_jar -Xmx1000m -Dhadoop.log.dir=/var/log/hadoop -Dhado ^C - Hadoop 作业运行时,确定将哪些文件写入 DataNode:
(输出有 222 行,为便于阅读已有删节。)
root@global-zone:~# dtrace -n 'syscall::write:entry/strstr(zonename,"data-node1")>0/ {@write[fds[arg0].fi_pathname]=count();}' dtrace: description 'syscall::write:entry' matched 1 probe ^C /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_-5404946161781239203 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_-5404946161781239203_1103.meta 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_-6136035696057459536 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_-6136035696057459536_1102.meta 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_-8420966433041064066 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_-8420966433041064066_1105.meta 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_1792925233420187481 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_1792925233420187481_1101.meta 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_4108435250688953064 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_4108435250688953064_1106.meta 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_8503732348705847964 - 确定写到 DataNode 的 HDFS 数据总量:
root@global-zone:~# dtrace -n 'syscall::write:entry / ( strstr(zonename,"data-node1")!=0 || strstr(zonename,"data-node2")!=0 || strstr(zonename,"data-node3")!=0 ) && strstr(fds[arg0].fi_pathname,"hdfs")!=0 && strstr(fds[arg0].fi_pathname,"blocksBeingWritten")>0/ { @write[fds[arg0].fi_pathname]=sum(arg2); }' ^C
总结
在本上机操作中,我们了解了如何使用 Oracle Solaris 区域、ZFS 和网络虚拟化和 DTrace 等 Oracle Solaris 11 技术搭建 Hadoop 集群。
另请参见
- Hadoop 和 HDFS
- Hadoop 框架
- “如何控制应用的网络带宽”
- “如何开始在 Oracle Solaris 11 中创建 Oracle Solaris 区域”
- “如何使用 Oracle Solaris 区域搭建 Hadoop 集群”
- “如何为 Oracle Solaris 11 构建本地 Hadoop 库”
- MapReduce
- WordCount
- “如何管理 ZFS 数据加密”
- DTrace
关于作者
Orgad Kimchi 是 Oracle(之前任职于 Sun Microsystems)ISV 工程小组的首席软件工程师。6 年来,他一直专注于虚拟化、大数据和云计算技术。
| 修订版 1.0,2013 年 10 月 21 日 |