Consolidação de dados da fábrica

Otimize a eficiência e reduza os riscos com dados consolidados em tempo real
Os fabricantes de hoje devem entender a eficiência com que todas as suas linhas estão operando em várias fábricas e precisam saber imediatamente quando ocorre um problema, não cinco ou dez minutos após o fato. No entanto, esse também é um dos maiores desafios porque sua capacidade de fazer isso depende do acesso em tempo real a dados de vários locais remotos que podem ter conectividade limitada ou esporádica com a Internet. Para resolver esse problema, precisamos levar o machine learning (ML) e a aquisição de dados para a borda da rede.
Simplifique a tomada de decisões na borda
Podemos configurar a Oracle Data Platform para resolver esse desafio incluindo Oracle Roving Edge Devices (REDs). Cada RED é projetado para capturar, armazenar, executar, gerenciar e obter insights de dados, dando aos fabricantes a capacidade de automatizar o processo de tomada de decisão e o gerenciamento de equipamentos de fabricação na borda. A Oracle Data Platform para manufatura também inclui recursos de detecção de anomalias, que podem ser usados para lidar com interrupções na linha de manufatura e fornecer informações relacionadas à manutenção para melhorar a mitigação e a correção.
A arquitetura a seguir demonstra como a Oracle Data Platform oferece suporte à consolidação de dados da fábrica, implementando análise avançada e machine learing na borda para identificar anomalias, realizar coleta de dados inteligente e fornecer informações operacionais em tempo real.
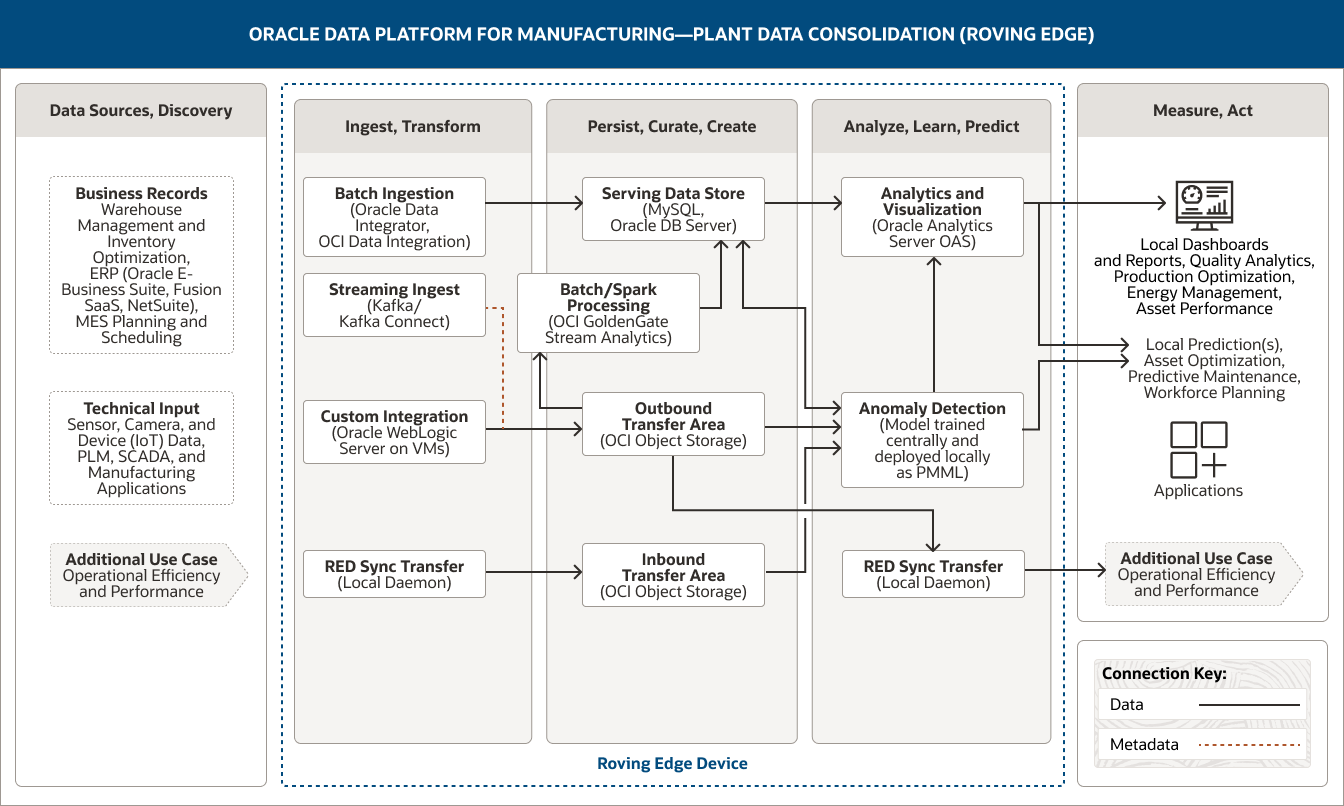
Esta imagem mostra como a Oracle Data Platform para manufatura pode ser usada para consolidar os dados da fábrica. A plataforma inclui os seguintes cinco pilares:
- 1. Fontes de dados, Descoberta
- 2. Ingestão, Transformação
- 3. Persistência, Curadoria, Criação
- 4. Análise, Aprendizado, Predição
- 5. Medição, Ação
O pilar Fontes de Dados, Descoberta inclui duas categorias de dados.
- 1. Os dados de registros de negócios incluem dados de gerenciamento de armazém e otimização de estoque, dados de ERP (Oracle E-Business Suite, Fusion SaaS, NetSuite) e dados de planejamento e programação de MES.
- 2. Os dados de entrada técnicos incluem dados de sensor, câmera e dispositivo (IoT) e dados de PLM, SCADA e aplicações de manufatura.
O pilar Ingestão, Transformação abrange quatro recursos.
- 1. A ingestão em lote usa Oracle Data Integrator e OCI Data Integration.
- 2. A ingestão de streaming usa Kafka Connect.
- 3. A integração personalizada usa Oracle WebLogic Server em VMs.
- 4. A transferência de sincronização do RED usa um daemon local.
A ingestão em lote se conecta unidirecionalmente ao armazenamento de dados de serviço.
A ingestão de streaming e a integração personalizada se conectam unidirecionalmente à área de transferência de saída.
Além disso, a transferência de sincronização do RED se conecta unidirecionalmente à área de transferência de entrada.
O pilar Persistência, Curadoria, Criação abrange quatro recursos.
- 1. O armazenamento de dados de serviço usa o servidor do MySQL e do Oracle DB.
- 2. O processamento em lote/processamento Spark usa OCI GoldenGate Stream Analytics.
- 3. A área de transferência de saída usa OCI Object Storage.
- 4. A área de transferência de entrada usa OCI Object Storage.
Esses recursos estão conectados no pilar. O processamento em lote/Spark é unidirecionalmente conectado ao armazenamento de dados de serviço.
A área de transferência de saída é conectada unidirecionalmente ao processamento em lote/Spark.
Três recursos se conectam ao pilar Análise, Aprendizado, Previsão:
O armazenamento de dados de serviço se conecta unidirecionalmente ao recurso de análise e visualização e bidirecionalmente ao recurso de detecção de anomalias. A área de transferência de saída se conecta unidirecionalmente à detecção de anomalias e aos recursos de transferência de sincronização do RED.
A área de transferência de entrada se conecta unidirecionalmente ao recurso de detecção de anomalias.
O pilar Análise, Aprendizado, Previsão abrange três recursos.
- 1. A análise e a visualização usam Oracle Analytics Server.
- 2. A detecção de anomalias usa um modelo treinado centralmente e implementado localmente como PMML.
- 3. A transferência de sincronização do RED usa um daemon local.
O recurso de detecção de anomalias é conectado unidirecionalmente ao recurso de análise e visualização dentro do pilar.
Três recursos estão conectados ao pilar Medição, Ação. O recurso de análise e visualização é conectado unidirecionalmente a painéis e relatórios locais e também a previsões locais. O recurso de detecção de anomalias é conectado unidirecionalmente a previsões locais, e o recurso de transferência de sincronização do RED é conectado unidirecionalmente a um caso de uso adicional.
O pilar Medição, Ação captura como os dados consolidados da fábrica podem ser usados. Esses usos potenciais são divididos em quatro grupos.
- O primeiro grupo inclui painéis e relatórios locais.
- O segundo grupo inclui previsões locais.
- O terceiro grupo inclui aplicações.
- O quarto grupo contém um caso de uso adicional, que é eficiência operacional e desempenho.
Os três pilares centrais — Ingestão, Transformação; Persistência, Curadoria, Criação; e Análise, Aprendizado, Previsão — são suportados pelo Oracle Roving Edge Device.
Existem quatro maneiras principais de injetar dados em uma arquitetura para permitir que os fabricantes entendam facilmente a eficiência operacional e o desempenho.
- Uma integração personalizada do Oracle Integration Repository nos permite integrar dados — estruturados e não estruturados — de várias fontes, permitindo interações com dispositivos, APIs personalizadas e assim por diante. Os dados podem ser ingeridos a partir de qualquer tipo de desenvolvimento de aplicação (por exemplo, código Java ou Python independente, aplicações baseadas em Oracle WebLogic Server ou em Kubernetes). Os dados serão mantidos no armazenamento de objetos para maior refinamento, para transferência de saída ou para alimentar modelos de IA.
- A sincronização de dados do RED é uma maneira eficiente e simples de transferir modelos de ML de um local central (por exemplo, seu repositório de armazenamento de objetos de modelos treinados na Oracle Cloud Infrastructure (OCI)) para a borda. Nesse caso de uso, a definição de borda teria o RED colocado com outro maquinário dentro da própria fábrica. Novas versões de modelos são armazenadas no formato Predictive Model Markup Language (PMML) “autônomo”. O daemon local executará uma atualização quando um novo modelo for descoberto e o enviará automaticamente para o RED. A sincronização de dados do RED também é uma ótima maneira de transferir todos os dados coletados por diferentes REDs ao longo do dia (por exemplo, anomalias relevantes, sinais e assim por diante) para seu local central, provavelmente para o armazenamento de objetos na OCI. Esses dados serão usados para relatórios operacionais e treinamento de modelos de ML. O volume de dados envolvido nesses processos de sincronização de dados do RED determinará seus requisitos para telecomunicações de borda a data center ou largura de banda de satélite.
- A ingestão em lote usa o Oracle Data Integrator, uma solução abrangente de integração de dados que abrange todos os requisitos, desde carregamentos em lote de alto volume e alto desempenho até processos de integração de fluxo lento e orientados por eventos e serviços de dados habilitados para SOA . Enquanto as necessidades em tempo real estão evoluindo, a extração mais comum de ERP, planejamento, gerenciamento de depósito e sistemas de gerenciamento de transporte é uma ingestão em lote usando um processo de extração, transformação e carregamento ou extração, carregamento e transformação. Essas extrações podem ser frequentes, a cada 10 ou 15 minutos, mas ainda são de natureza volumosa, pois as transações são extraídas e processadas em grupos, e não individualmente. A OCI oferece diferentes serviços para lidar com a ingestão em lotes; isso inclui o serviço OCI Data Integration nativo ou o Oracle Data Integrator em execução em uma instância do OCI Compute. Dependendo dos volumes e tipos de dados, os dados podem ser carregados no armazenamento de objetos ou carregados diretamente em um banco de dados relacional estruturado para armazenamento persistente.
- A análise de dados em tempo real de várias fontes pode ajudar a fornecer às empresas de manufatura informações valiosas sobre sua eficiência operacional e desempenho geral. A Oracle Data Platform usa ingestão de streaming para ingerir fluxos de dados de vários sistemas ISA-95 Nível 2, como sistemas de controle de supervisão e aquisição de dados (SCADA), controles lógicos programáveis e sistemas de automação em lote. Os dados de streaming (eventos) serão ingeridos e algumas transformações/agregações básicas ocorrerão antes que os dados sejam colocados no armazenamento de objetos. A análise de streaming pode ser usada para identificar eventos correlacionados e os padrões identificados podem ser realimentados (manualmente) para um exame dos dados brutos. Enquanto as ferramentas de análise tradicionais extraem informações de dados em repouso, a análise de streaming avalia o valor dos dados em trânsito, ou seja, em tempo real.
A persistência e o processamento de dados são baseados em três componentes.
- No armazenamento de dados de serviço, os dados serão gerenciados pelo Oracle Database Server ou MySQL para processamento. O armazenamento de dados de serviço fornece uma camada relacional persistente frequentemente usada para fornecer dados diretamente aos usuários finais por meio de ferramentas baseadas em SQL. Ele também funciona como a camada de serviço para análises especializadas.
- Todos os dados recuperados de fontes em sua forma bruta (como um arquivo nativo ou extração) são capturados e carregados no armazenamento de objetos para serem usados no treinamento atual ou futuro de modelos de ML. O armazenamento de objetos na nuvem é a camada de persistência de dados mais comum para nossa plataforma de dados e serve como área de transferência de entrada e área de transferência de saída. Pode ser usado para dados estruturados e não estruturados.
- Com o armazenamento de objetos como a camada primária de persistência de dados, o OCI GoldenGate Stream Analytics é o principal mecanismo de processamento. O processamento em lote envolve várias atividades, incluindo tratamento básico de ruído, gerenciamento de dados ausentes e filtragem com base em conjuntos de dados de saída definidos. Os resultados são gravados em várias camadas de armazenamento de objetos ou em um repositório relacional persistente com base no processamento necessário e nos tipos de dados usados.
A capacidade de analisar, aprender e prever é construída em duas tecnologias.
- Os serviços de Análise e visualização oferecem análise descritiva (descreve as tendências atuais com histogramas e gráficos), análise preditiva (prevê eventos futuros, identifica tendências e determina as probabilidades de resultados incertos) e análise prescritiva (propõe ações adequadas , levando a uma tomada de decisão ideal). O Oracle Analytics Server conta com uma funcionalidade para fornecer análises descritivas relacionadas a relatórios operacionais e análises prescritivas. Além disso, os modelos de ML podem ser incorporados diretamente no fluxo de dados do Oracle Analytics Server. O Oracle Analytics Server foi projetado para ser executado on-premises e fornece painéis, relatórios, alertas, preparação de dados de autoatendimento e algoritmos de machine learning orientados ao usuário final. A Oracle Data Platform para manufatura é totalmente aberta e flexível, portanto, se desejar, você pode usar ferramentas de terceiros para isso.
- Juntamente com o uso de análises avançadas, os modelos de ML são desenvolvidos, treinados e implementados para dar suporte à detecção de anomalias. O OCI Anomaly Detection é um serviço de IA que torna mais fácil para os desenvolvedores criar modelos de detecção de anomalias específicos que sinalizam incidentes críticos, acelerando a detecção e a resolução. Esses modelos serão treinados no local central e implementados no formato PMML para serem executados localmente como código Java ou Python.
Automatize a tomada de decisões para aumentar a lucratividade
A Oracle Data Platform permite que os fabricantes obtenham o maior valor de todos os seus dados disponíveis, simplificando e otimizando o acesso e o armazenamento de dados. A capacidade de levar a coleta de dados e a pontuação de ML ao limite por meio dos Oracle Roving Edge Devices ajuda os fabricantes a tomar melhores decisões de negócios, informadas por dados precisos que estão sempre disponíveis quando precisam, permitindo aumentar a eficiência e a produção enquanto reduzem os custos.
Recursos relacionados
-
Caso de uso
Use dados para melhorar a saúde e a segurança no local de trabalho
Saiba como deixar as operações de manufatura mais seguras utilizando uma plataforma de dados que ajuda a melhorar a integridade e a segurança com análises avançadas.
-
Caso de uso
Use dados para melhorar a eficiência e o desempenho operacional da manufatura
Saiba como gerenciar operações de manufatura com mais eficiência utilizando uma plataforma de dados que ajuda a melhorar o desempenho com machine learning.
-
Caso de uso
Use seus dados para passar da manutenção reativa para a preditiva
Saiba como otimizar ativos com uma plataforma de dados que permite manutenção preditiva com machine learning.
Comece agora
Teste mais de 20 serviços de nuvem de uso livre com uma avaliação de 30 dias para ter ainda mais
A Oracle oferece um Modo Gratuito sem limite de tempo para uma variedade de serviços como Autonomous AI Database , Arm Compute e Armazenamento, além de US$ 300 em créditos para você experimentar serviços de nuvem adicionais. Obtenha os detalhes e inscreva-se para uma conta gratuita hoje mesmo.
-
O que está incluído no Modo Gratuito da Oracle Cloud?
- Duas instâncias do Autonomous AI Database, 20 GB cada
- VMs de Arm Compute e AMD
- 200 GB de armazenamento total em blocos
- 10 GB de armazenamento de objetos
- Transferência de dados de saída de 10 TB por mês
- Mais de 10 serviços de uso livre
- US$300 em créditos por 30 dias para ter ainda mais
Aprenda com a orientação passo a passo
Experimente uma ampla gama de serviços da OCI por meio de tutoriais e laboratórios práticos. Se você é desenvolvedor, administrador ou analista, podemos ajudá-lo a ver como a OCI funciona. Muitos laboratórios são executados no modo gratuito da Oracle Cloud ou em um ambiente de laboratório livre fornecido pela Oracle.
-
Comece pelos principais serviços da OCI
Os laboratórios deste workshop abrangem uma introdução aos serviços da Oracle Cloud Infrastructure (OCI), incluindo redes virtuais na nuvem (VCN) e serviços de computação e armazenamento.
Comece o laboratório de serviços básicos da OCI agora mesmo -
Início rápido do Autonomous AI Database
Neste workshop, você acompanhará as etapas para começar a usar o Oracle Autonomous AI Database .
Comece o laboratório do Autonomous AI Database agora mesmo -
Crie uma aplicação com base em uma planilha
Este laboratório orienta você a fazer o upload de uma planilha em uma tabela do Oracle Database e, em seguida, a criar uma aplicação com base nessa nova tabela.
Comece o laboratório agora
Explore mais de 150 projetos de melhores práticas
Veja como nossos arquitetos e outros clientes implementam uma ampla variedade de cargas de trabalho, de aplicações corporativas a HPC, de microsserviços a data lakes. Entenda as práticas recomendadas, ouça outros arquitetos de clientes em nossa série Built & Deployed e até mesmo implemente muitas cargas de trabalho com nosso recurso "clique para implementar" ou faça você mesmo em nosso repositório do GitHub.
Arquiteturas populares
- Apache Tomcat com MySQL Database Service
- Oracle Weblogic no Kubernetes com Jenkins
- Ambientes de machine learning (ML) e IA
- Tomcat no Arm com Oracle Autonomous AI Database
- Análise de log com ELK Stack
- HPC com OpenFOAM
Veja o quanto você pode economizar na OCI
Os preços da Oracle Cloud são simples, com preço baixo consistente em todo o mundo, oferecendo suporte a uma ampla gama de casos de uso. Para estimar a sua taxa, consulte a estimativa de custos e configure os serviços para atender às suas necessidades.
Experimente a diferença:
- 1/4 dos custos de largura de banda de saída
- 3X o custo-benefício de computação
- Mesmo preço em todas as regiões
- Preços baixos sem contratos de longo prazo
Fale com um especialista
Interessado em saber mais sobre a Oracle Cloud Infrastructure? Deixe um de nossos especialistas ajudar.
-
Eles podem responder a perguntas como:
- Quais cargas de trabalho são melhor executadas na OCI?
- Como aproveitar ao máximo meus investimentos gerais na Oracle?
- Como a OCI se compara a outros provedores de computação em nuvem?
- Como a OCI pode oferecer suporte às metas de IaaS e PaaS?