 Artigos
Enterprise Management
Artigos
Enterprise Management
Lendo métricas dos Storage Servers a partir de um Database Server em um Oracle Exadata
Por Fernando Simon (OCE) e Deiby Gómez
Postado em Maio 2015
Revisado por Marcelo Pivovar - Solution Architect
Atualmente existem inúmeras soluções Oracle Exadata em uso nas mais diversas áreas e os seus administradores tem diversas ferramentas para monitorar o desempenho e verificar o que está acontecendo nos Storage Servers, Database Servers e rede de intercomunicação. De qualquer forma, existem inúmeras métricas do Exadata Software presente nos Storage Servers com informações sobre o ambiente e que geralmente não são utilizadas e muitas nem são bem compreendidas.
Nós podemos utilizar estas métricas dos Storage Servers para entender a carga de trabalho sobre o ambiente, mas infelizmente você tem que logar em cada um dos Storage Servers para ver as métricas (nem o Cloud Control entrega todas elas). Se você tem um Exadata Full Rack terá 14 Storage Servers para fazer o login, é bastante trabalho! Neste artigo vamos mostrar como ler estas métricas sem precisar fazer login em cada um dos Storage Server, após seguir os passos deste artigo você conseguirá consultar as métricas através de simples comandos SQL.
Basicamente os passos que iremos abordar seguem o seguinte fluxo:
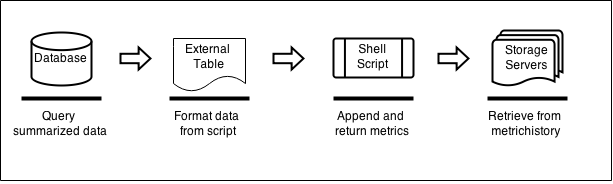
A partir de um SELECT em um Database Server, a instância utilizará uma external table para chamar um script que irá extrair as informações das métricas de cada um dos Storage Servers.
O que veremos:
Passo 1 – Criação do Script
Passo 2 – Testando o Script
Passo 3 – External Table
Passo 4 – Ajuste de dados
Passo 5 – Lendo os dados
Passo 1 – Criação do Script
A ideia que usei aqui é a mesma que Christo Kutrovsky usou nesse artigo http://www.pythian.com/blog/whats-in-your-exadata-smart-flash-cache/ para descobrir o que está armazenado no Flash Cache.
Será criado um script que será utilizado por uma external table e irá consultar e retornar as métricas cada Storage Server. O script utilizado está disponível no fim do artigo e tem o nome de “metric-his-US.sh” e pode ser modificado para os seus requisitos. Este script deve ser colocado no Database Server que tem a instância que você estará conectado e rodará as suas consultas (se você não sabe, coloque em todos). No modo padrão o script retorna a última hora de métricas de cada um dos seus Storage Server e de todos os que estão no arquivo cellip.ora.
Se você abrir o script verá que existem três variáveis que podem ser ajustadas:
lTxtWindow: esta variável define qual o valor do tempo utilizado na janela de consulta sobre as métricas.
lTxtWindowType: esta variável define a unidade de medida de tempo utilizada na janela de consulta, pode ser hora, dias ou minutos. O valor padrão é hora.
lTxtTMZ: variável utilizada para definir o timezone do momento da consulta. No meu caso eu uso “-03:00”.
Notas Importantes
- O script utiliza “ssh” para logar em cada Storage Server. Dessa forma, como pré-requisito, é necessário ter o ssh configurado com chaves de autenticação em cada Database Server. Geralmente estas chaves são geradas automaticamente e você só precisa copiar elas entre os usuários e servidores através do Linux manualmente ou com ferramentas como “ssh-copy-id”. Para ter certeza você pode tentar fazer login a partir do Database Server que você está usando como por exemplo “ssh celladmin@<IP_or_Hostname>”, se tudo estiver certo você conseguirá fazer o login sem senha no Storage Server.
- Se você quiser chamar este script de qualquer instância você terá que configurar o script em cada Database Server, basicamente executar os passos acima em cada um deles. Lembre-se que se você está usando role separation no seus usuário de sistema operacional ter configurar as chaves de ssh e o script no passo 2 com o usuário grid. O usuário a ser utilizado para ssh nos storage servers é o celladmin.
Dependendo da sua política de segurança de seu banco de dados terá que modificar e adicionar as permissões para o diretório que o script está. Neste artigo para simplificar o script ficou na pasta “/tmp”.
Passo 2 – Testando o Script
Depois de completar do passo 1 você terá o script no diretório “/tmp” e pronto para ser executado. Para testar basta chamar ele do terminal e o resultado deve ser como o demonstrado abaixo:
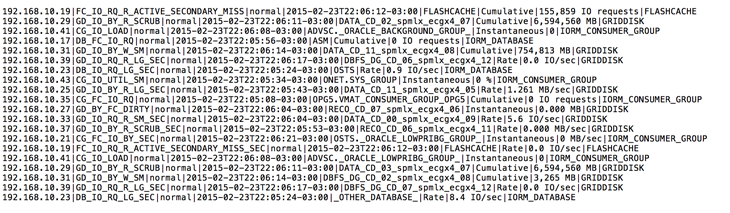
Como pode ser visto acima, a saída de cada métrica do Exadata Sofware é retornada em uma única linha separada pelo delimitador “|”. Verifique que ele será utilizado no passo 3.
Passo 3 – External Table
Depois de confirmar que o script traz os resultados esperados no passo 2 o próximo passo é configurar a external table. Ela deverá ser criada no banco de dados que você quer utilizar para a external table, lembre-se que se você quiser rodar isso de qualquer instância você terá que ter configurado o script e as chaves ssh em todos os nós. A external table está baseada em um Oracle Directory (o mesmo que o script está localizado):
create directory metric_cell as '/tmp';
Depois do directory criado o próximo passo é a external table em si tendo como base o parâmetro PREPROCESSOR. A ordem das colunas retornadas é a mesma presente nas métricas do Oracle Exadata e note que todas estão definidas como “varchar2” (deliberadamente para simplificar o script):
create table metric_cell_hist (
node varchar(150),
nameMetric varchar(150),
alertState varchar(150),
collectionTime varchar(150),
metricObjectName varchar(150),
metricType varchar(150),
metricValue varchar(150),
objectType varchar(150)
)
ORGANIZATION EXTERNAL
(
TYPE ORACLE_LOADER
DEFAULT DIRECTORY metric_cell
ACCESS PARAMETERS
(
RECORDS DELIMITED BY NEWLINE
PREPROCESSOR metric_cell: 'metric-hist-US.sh'
nologfile
nobadfile
FIELDS TERMINATED BY '|'
)
LOCATION ('.')
)
REJECT LIMIT UNLIMITED;
Fazendo qualquer consulta sobre esta external table ela irá chamar o script e retornará todas as métricas de cada Storage Server.
Passo 4 – Ajuste de dados
Bom, já podemos retornar as métricas e ler todos os dados (mesmo que sejam todos varchar2), mas toda a vez que a external table é chamada o script é executado e isso pode ser moroso. Para ganharmos mais agilidade nas consultas sobre as métricas alguns ajustes são interessantes.
A primeira é criar uma tabela normal (chamada aqui de tabMetricHist_1hr) em uma tablespace para armazenar os dados da external table. A consulta abaixo faz isso e algumas coisas a mais, como conversões de dados. A primeira conversão visível é com a coluna “collectiontime” para torná-la do tipo “DATE” e a segunda é com a coluna “metricvalue” para separar o valor da unidade de medida.
CREATE TABLE tabMetricHist_1hr TABLESPACE DTITBS AS select mch.node AS cellServer , mch.namemetric AS metric , mch.alertstate AS metricState , TO_DATE(SUBSTR(mch.collectiontime, 0, 19), 'RRRR-MM-DD"T"HH24:MI:SS') as collectionMoment , mch.collectiontime , mch.metricobjectname AS objectName , mch.metrictype AS metricType , CASE WHEN INSTR(mch.metricvalue, ' ') != 0 THEN SUBSTR(mch.metricvalue, 0, INSTR(mch.metricvalue, ' ')) ELSE mch.metricvalue END AS collectedValue , mch.metricvalue , CASE WHEN INSTR(mch.metricvalue, ' ') != 0 THEN SUBSTR(mch.metricvalue, INSTR(mch.metricvalue, ' ') + 1, 50) ELSE 'N/A' END AS metricUnit , mch.objecttype AS objectType from metric_cell_hist mch;
Antes de seguir com o artigo e passos uma explicação, você tem que estar ciente que algumas métricas do Oracle Exadata são “cumulativas”. Isso quer dizer que se você coletar as métricas as 15:00 e já tiver feito 100.000 IOPS a métrica irá retornar 100.000. Se fizer uma nova consulta as 15:10 e tiver feito mais 10.000 IOPS a métrica irá reportar 110.000 IOPS ao invés de somente 10.000 porque é “cumulativa”. Se você quiser o valor real da última hora precisará de alguns ajustes adicionais para evitar surpresas com valores fora da curva.
Com a tabela adicional você poderá fazer mais coisas que a external table, você pode criar índices para aumentar o desempenho das consultas por exemplo. Outro detalhe é que se preferir (ou precisar) poderá trocar/remover/ajustar o digito separador de unidades. Os próximos dois comandos adicionam duas colunas na tabela para ajudar na conversão de valores “varchar2” para “number”:
ALTER TABLE tabMetricHist_1hr ADD collectedValue_num DECIMAL(32, 8);
ALTER TABLE tabMetricHist_1hr ADD collectedValue_fixed DECIMAL(32, 8);
Os próximos dois comandos fazem a conversão de dados (no meu caso removem o separador “,” também). O terceiro comando não copia os valores das métricas “cumulativas”. Se você não quiser isso no último comando basta remover a restrição do WHERE; se quiser corrigir e equalizar as métricas “cumulativas” utilize o script “fixCumulativeMetric.sql“.
UPDATE tabMetricHist_1hr mh SET collectedValue_num = TO_NUMBER(REPLACE(mh.collectedValue, ','));
UPDATE tabMetricHist_1hr tmh SET tmh.collectedValue_fixed = 0 WHERE tmh.collectedValue_num = 0;
UPDATE tabMetricHist_1hr mh SET collectedValue_fixed = collectedValue_num WHERE tipometrica != 'Cumulative';
Lembre-se que estes ajustes foram feitos pois eu queria remover/ajustar o separador de casas decimais e converter os valores para número. Todos os comandos de criação de colunas e suas conversões numéricas poderiam ter sido feitos durante a criação da nova tabela, escolhi fazer separadamente para explicar detalhadamente o que estava acontecendo. Se você utilizar isso em um processo automatizado, recomendo realizar tudo em um único comando.
Passo 5 – Lendo os dados
Após a criação do script, da external table, da tabela e ajuste de dados você pode fazer as consultas que desejar. Como falei antes, o padrão do script é retornar a última hora das métricas do software, mas pode chegar a mais (no máximo de 7 dias). Como as métricas do Exadata Software são coletadas a cada minuto as suas consultas tem que levar isso em consideração. Recomendo ler os manuais do Exadata Sotware, como o user guide, para entender mais sobre as métricas e como utilizá-las.
Por exemplo, você pode fazer a consulta abaixo para retornar a quantidade de IOPS na FlashCache para cada banco de dados. Aqui, agrupei por banco (independe do Storage Node) todo o IO executado as 14:45 do dia 02/09/2015 usando a métrica DB_FC_IO_RQ_SEC:
select tmh.metric
, ROUND(SUM(tmh.collectedValue_fixed), 0) as value
, tmh.metricUnit
, tmh.objectName
, to_char(tmh.collectionMoment, 'DD/MM/RRRR HH24:MI') as moment
FROM tabMetricHist_1hr tmh
WHERE tmh.metric = 'DB_FC_IO_RQ_SEC'
and tmh.collectionMoment between to_date('09/02/2015 14:45:00', 'dd/mm/rrrr hh24:mi:ss')
and to_date('09/02/2015 14:45:58', 'dd/mm/rrrr hh24:mi:ss')
group by tmh.metric
, tmh.metricUnit
, to_char(tmh.collectionMoment, 'DD/MM/RRRR HH24:MI')
, tmh.objectName
order by tmh.metric
, tmh.objectName
/
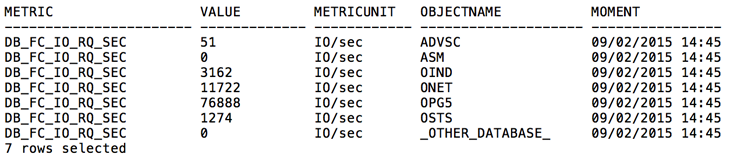
Você pode fazer a mesma coisa, retornando o consumo de CPU de cada Storage Node para o mesmo horário com a seguinte consulta:
select tmh.metric
, ROUND(SUM(tmh.collectedValue_fixed), 0) as value
, tmh.metricUnit
, tmh.objectName
, to_char(tmh.collectionMoment, 'DD/MM/RRRR HH24:MI') as moment
FROM tabMetricHist_1hr tmh
WHERE tmh.metric = 'CL_CPUT'
and tmh.collectionMoment between to_date('09/02/2015 14:45:00', 'dd/mm/rrrr hh24:mi:ss')
and to_date('09/02/2015 14:45:58', 'dd/mm/rrrr hh24:mi:ss')
group by tmh.metric
, tmh.metricUnit
, to_char(tmh.collectionMoment, 'DD/MM/RRRR HH24:MI')
, tmh.objectName
order by tmh.metric
, tmh.objectName
/ 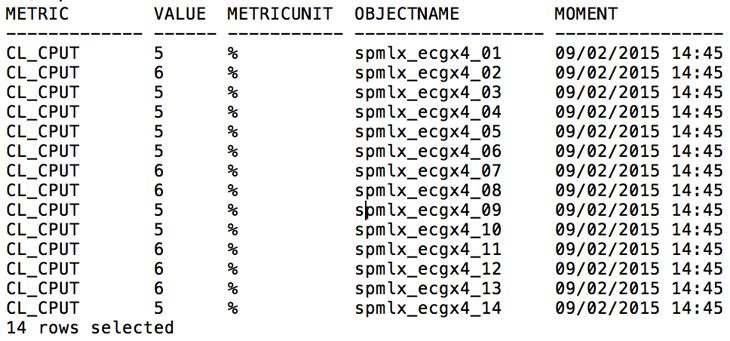
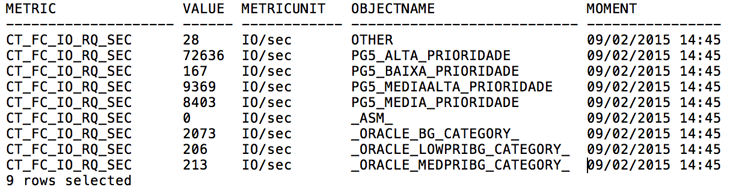
Se você estiver usando IORM, pode fazer dividir em categorias:
select tmh.metric
, ROUND(SUM(tmh.collectedValue_fixed), 0) as value
, tmh.metricUnit
, tmh.objectName
, to_char(tmh.collectionMoment, 'DD/MM/RRRR HH24:MI') as moment
FROM tabMetricHist_1hr tmh
WHERE tmh.metric = 'CL_CPUT'
and tmh.collectionMoment between to_date('09/02/2015 14:45:00', 'dd/mm/rrrr hh24:mi:ss')
and to_date('09/02/2015 14:45:58', 'dd/mm/rrrr hh24:mi:ss')
group by tmh.metric
, tmh.metricUnit
, to_char(tmh.collectionMoment, 'DD/MM/RRRR HH24:MI')
, tmh.objectName
order by tmh.metric
, tmh.objectName
/
Conclusão
O script foi criado para permitir a leitura dos valores das métricas do Exadata Software diretamente de um banco de dados. Se você quiser, pode ajustar diversos pontos, como a janela de consulta para retornar mais dados. Os exemplos de consultas e passos que demonstrei aqui no artigo são simples e serão detalhados em outros artigos, mas você pode brincar com as consultas, external table e tabelas para extrair a informação que desejar. Você pode utilizar o que demonstrei aqui para criar relatórios detalhados, jobs ou relatórios BI diretamente do Cloud Control.
Script 1: metric-hist-US.sh
Scritp 2: fixCumulativeMetric.sql
Fernando Simon DBA do Tribunal de Justiça de Santa Catarina. Trabalha como DBA a diversos anos, desde o Oracle 9i até o Oracle 12c. Tem experiência prática com Oracle Exadata (do V2 ao X4) e soluções que dependem de High Availability como Data Guard, Oracle RAC e replicações diversas. Também atua como palestrante em eventos Oracle no Brasil. Blog: http://www.fernandosimon.com/blog
Deiby Gómez é considerado o Oracle ACE mais jovem do mundo, o primeiro da Guatemala (seu país de origem), tudo isso aos 23 anos de idade. DBA focado e motivado em bancos de dados Oracle, é o OCM 11g mais jovem da América Latina (24 anos). É membro do OraWorld Team, presidente do grupo de usuários Oracle da Guatemala e trabalha hoje na Pythian. Blog: www.oraclefromguatemala - twitter: @hdeiby
Este artigo foi revisto pela equipe de produtos Oracle e está em conformidade com as normas e práticas para o uso de produtos Oracle.
Entre em Contato Conosco
- Vendas: 0800-891-4433
- Contatos Globais
- Diretório de Suporte