コーソルOracleスペシャリストがチェック!Oracle Database 12c R2新機能
Oracle Database 12c R2には非常に多くの新機能があります。これまでに存在しなかった純粋な意味での新機能もありますし、従来から存在している機能を改善した位置づけの新機能もあります。これらの新機能すべてをチェックすることは非常に大変な作業です。本連載では、Oracle Databaseを日々愛用(≒酷使!)するコーソルのOracleスペシャリストがチェックし、特に有用と思われる12c R2新機能をご紹介します。
是非本連載の記事をご覧いただき、現場で活用できそうな機能がありましたら、ぜひその新機能を使っていただきたいと思います。
本連載が、みなさまのお役にたてば幸いです。
第1回 Oracle Database 12c R2新機能でSQL Plan Managementを"賢く"使い倒せ!

株式会社コーソル 村田 智千帆(むらた さちほ)
2013年にコーソルへ新卒で入社。
Oracle Databaseの製品サポート業務を担当した後、Exadata構築支援業務を経験。現在はOracle製品の構築・運用支援に日々奮闘中。
お客様からも同僚からも「一緒に仕事をしたい」と思ってもらえる存在になることが目標。

[会社紹介] 株式会社コーソル
Oracleを中心にデータベースの設計、導入・構築、運用管理、保守・サポート、コンサルティング等、「Oracle Database技術」の強みを活かしたビジネスを展開。エンジニア社員の「ORACLE MASTER」の保有率は98%に及び、その内の約40%はORACLE MASTER Platinumを取得している。技術者を数多く育成した企業に贈られる「Oracle Certification Award」を5年連続で受賞。2016年現在、企業別ORACLE MASTER 11g/12c Platinum取得者数ランキングで国内No.1。「CO - Solutions=共に解決する」の理念のもと、「データベース技術」×「サービス」を軸とし、高いDB技術をもとにお客様へ"心あるサービス"を提供し続けることにこだわっている。
Oracle Database 11g R1から実装されているSQL Plan Managementがこの度Oracle Database 12c R2(以下12c R2)で機能強化され、より導入しやすくなりました。本記事ではSPMの使い方を基本から振り返りつつ、新リリースで実装された新機能の使い方を検証します!
1. SPMとは
SQL Plan Management(以下、SPM)とは、繰り返し実行されるSQLの処理性能を安定させることを目的とした機能です。実行計画を固定化するだけではなく、よりよい実行計画が見つかった場合に、性能を事前に検証することもできます。
1. 1. SPMのアーキテクチャ
SPM関連の初期化パラメータを有効にすると、SQLの計画ベースライン(※)が自動で取得されます。また、過去に実行したSQLの実行計画を計画ベースラインとして手動追加することも可能です。取得された計画ベースラインは、SYSAUX表領域にあるSQL Management Baseの計画履歴(Plan History)内で保持されます(図1)。 (※)計画ベースライン…実行計画を固定化するために使用される内部的なヒントの集合
■図1:計画ベースラインの格納先
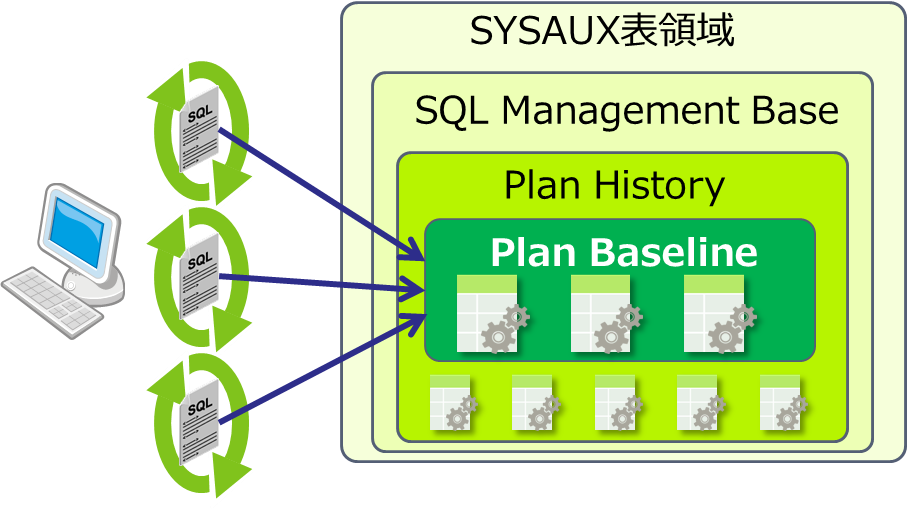
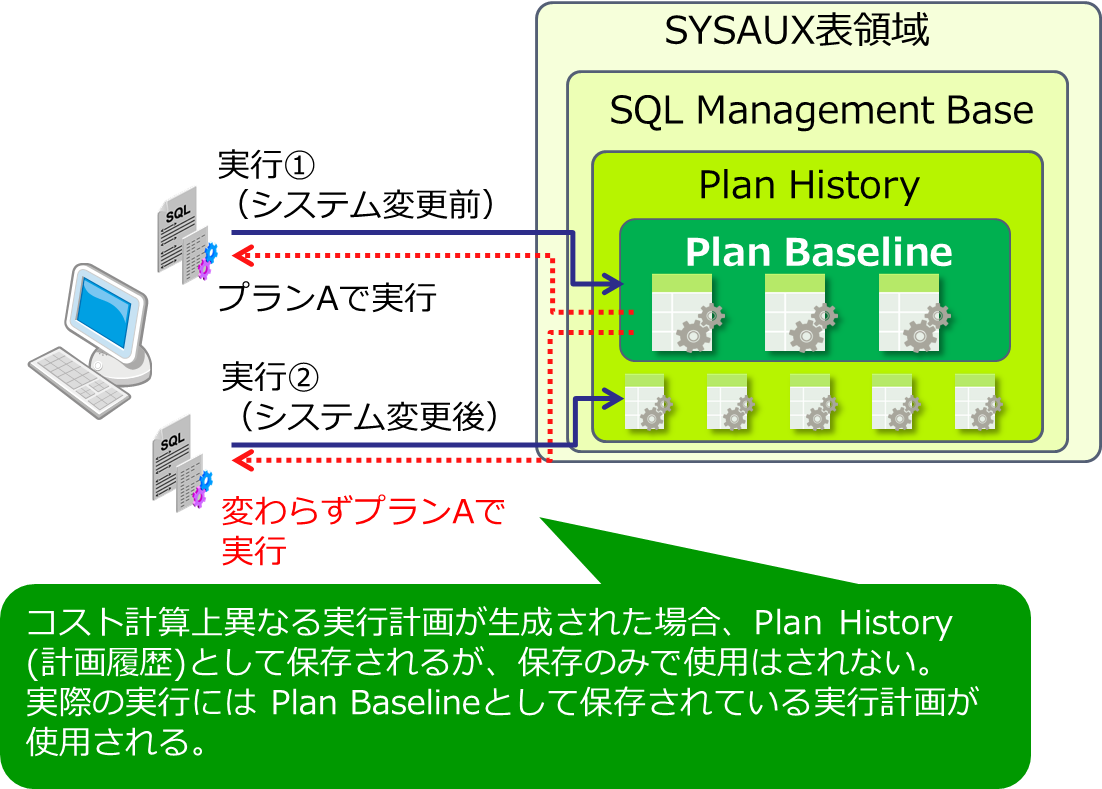
計画ベースラインの使用が有効化されたSQLは、統計情報などの変化に左右されることなく同一の実行計画が使われるようになります(図2)。
■図2:計画ベースラインが使用される際の流れ(※イメージ図)
1. 2. SPMの利用が想定されるケースは大きく2つ
SPMの恩恵を受けやすい、あるいはSPMの効果が発揮されやすいケースとして、以下2点が考えられます。
① 性能劣化の予防:
SPMで特定処理の実行計画を固定化し、オプティマイザ統計の変動やアップグレード等に起因する性能劣化を未然に防ぐ効果を期待することが出来ます。
ただし、「すべてのシステムにおいて、実行計画固定化が一番!」と主張するつもりはありません。Oracle DatabaseのCBOや自動最適化機能も年々進化していますし、実行計画を固定化することが最善策では無い場合もあります。ただし業務上どうしても性能劣化が許されない処理があったり、アップグレード前の性能を担保してデータベース移行をしなければいけなかったり、という場面でSPMは有効な手段となると考えています。
② アプリケーションの改修を不要にする:
SPMを利用するとアプリケーションで実行するSQL文へ変更を加えることなく、実行計画のみを変更できます。例えば、あるSQLにインデックス・ヒントを付与すれば問い合わせ速度が向上することが分かったものの、アプリの仕組み上SQLに直接ヒント句を埋め込む対処ができない場合、SPMでその索引を使う実行計画を指定し、固定化させることができます。
上記に合致するような場面に実際に遭遇する方は、ぜひSPMの使用を検討してみてはいかがでしょうか。次章以降では、SPMの基本的な操作方法について、そして最新バージョンで拡張された機能について紹介していきますので、そちらの情報もご活用ください。
2. SPMの使用法おさらい
12c R2から新たに拡張された機能の説明に入る前に、まずはSPMの基本的な使用方法を確認しておきましょう。 従来のリリースでのSPMは既に使用している方、また基本的な使用法は知っているという方は「4. 12c R2でのSPM新機能」からお読みください。
2. 1. 事前準備
※本パートで紹介する手順に新リリースの新機能は含みませんのでコマンド例などは従来のリリースでも同様に実行可能です。ただし、実行結果の内容など細かな箇所は従来のリリースとは異なる場合があります。
※R12.2.0.1 Enterprise Edition シングル・コンテナ(1CDB-1PDB)の環境で検証しています。
※事前にSPM1,SPM2というDBユーザをPDB上にそれぞれ作成しています
$ sqlplus / as sysdba
SQL> alter session set container=PDB1;
SQL> show con_name
CON_NAME
------------------------------
PDB1
SQL> -- テーブル準備
SQL> create table spm1.tbl_a (a_no number, a_char varchar2(1), a_date date) tablespace users;
SQL> create table spm1.tbl_b (b_no number, b_char varchar2(1), b_date date) tablespace users;
SQL> create table spm2.tbl_c (c_no number, c_char varchar2(1), c_date date) tablespace users;
SQL> begin
2 for i in 1..100 loop
3 insert into spm1.tbl_a(a_no,a_char,a_date) values(i,'A',sysdate);
4 insert into spm1.tbl_b(b_no,b_char,b_date) values(i,'B',sysdate);
5 insert into spm2.tbl_c(c_no,c_char,c_date) values(i,'C',sysdate);
6 end loop;
7 commit;
8 end;
9 / 2. 2. ベースライン自動取得設定
ここでは、計画ベースラインをデータベースに自動で取得させる方法を用いてSPMの動作を確認していきます。まずはSPM関連の初期化パラメータを確認します。
SQL> -- SPM関連の初期化パラメータを確認
SQL> select name,value from v$parameter where name like '%sql_plan%';
NAME VALUE
-------------------------------------------------- ------------------------------
optimizer_capture_sql_plan_baselines FALSE
optimizer_use_sql_plan_baselines TRUE デフォルトでは「optimizer_capture_sql_plan_baselines」パラメータがFALSEであり、計画ベースラインの自動取得は行われない設定になっています。一方、計画ベースラインを使用するかどうかを制御するパラメータである「optimizer_use_sql_plan_baselines」はデフォルトでTRUEであり、有効な計画ベースラインがあれば、それを使用して実行計画を固定化する設定になっています。
計画ベースラインの取得を自動で行うためにパラメータを変更します。
SQL> -- SQLベースラインの自動取得をON
SQL> alter session set optimizer_capture_sql_plan_baselines = TRUE;
セッションが変更されました。
SQL> select name,value from v$parameter where name like '%sql_plan%';
NAME VALUE
-------------------------------------------------- ------------------------------
optimizer_capture_sql_plan_baselines TRUE
optimizer_use_sql_plan_baselines TRUE alter system文で永続的な設定変更を行うことも可能ですが、意図せず大量のSQL計画ベースラインが取得された場合、SYSAUX表領域の肥大化をもたらす可能性がある点に注意してください。なぜならば、「optimizer_capture_sql_plan_baselines」がTRUEになっている間は複数回実行されたSQLの”全て”が計画ベースラインの取得対象となり、取得された計画ベースラインはSYSAUX表領域内のSQL Management Base領域に格納されていく為です。 試験的な利用であれば上記例のようにalter session文を用いたセッションレベルでの設定変更に留め、同一セッション内でベースラインを取得させたいSQLを流すと良いでしょう。
2. 3. SQLを複数回実行してベースラインを取得
「optimizer_capture_sql_plan_baselines」パラメータがTRUEに設定された状態で2回以上実行された(厳密には初回実行でハードパースされ、その後再実行された)SQLがあると計画ベースラインが自動で取得されます。
取得された計画ベースラインの一覧を確認するには「dba_sql_plan_baselines」ビューを問い合わせます。
SQL> -- まだ計画ベースラインには何も取得されていない
SQL> select sql_handle,sql_text, plan_name from dba_sql_plan_baselines;
レコードが選択されませんでした。
SQL> -- SQLを複数回実行
SQL> select count(a_no) from spm1.tbl_a;
SQL> select count(a_no) from spm1.tbl_a;
SQL> select count(c_no) from spm2.tbl_c;
SQL> select count(c_no) from spm2.tbl_c;再度「dba_sql_plan_baselines」ビューを問い合わせると、直前に実行したSQLの情報が追加されています。SQL_HANDLEは各SQLを一意に識別するためにOracleが付与する識別子で、PLAN_NAMEは計画ベースライン情報に対する識別子です。
SQL> -- ベースラインが作成されているかを確認
SQL> select sql_handle,sql_text, plan_name from dba_sql_plan_baselines;
SQL_HANDLE SQL_TEXT PLAN_NAME
----------------------------------- -------------------------------------------------------------------------------- --------------------------------------------------
SQL_4c450ecc66bd156c select sql_handle,sql_text, plan_name from dba_sql_plan_base SQL_PLAN_4sj8ftjmbu5bc1a511bed
lines
SQL_61cc827487943171 select name,value from v$parameter where name like '%sql_pla SQL_PLAN_63m42fk3t8cbjdaee80ec
n%'
SQL_824ce805cb9efd2e select count(c_no) from spm2.tbl_c SQL_PLAN_84m780r5txz9f5bee716c SQL_d8f3f345667a3835 select count(a_no) from spm1.tbl_a SQL_PLAN_djwzm8pm7nf1pb767d7ea 後ほど確認しますが、同一のSQL_HANDLEに対して複数のPLAN_NAMEが登録されることがあります。
※統計情報の変化や索引の有無などにより、同じSQLを実行してもOracleのオプティマイザが異なる実行計画を生成する場合があるからです。
2. 4. 取得されたベースラインの詳細を確認
「dba_sql_plan_baselines」ビューでは計画ベースラインの取得状況を確認することが出来ますが、そのベースラインで具体的にどのような実行計画が生成されるのか、ということは確認出来ません。そこで、「dbms_xplan.display_sql_plan_baseline」ファンクションを使用して実行計画の内容を表示します。先ほど確認したPLAN_NAMEの情報を渡して実行してみます。
SQL> -- ベースラインの実行計画を確認
SQL> -- select count(a_no) from spm1.tbl_a; の実行で取得された(ベースライン)
SQL> select * from table(
2 dbms_xplan.display_sql_plan_baseline(
plan_name=>'SQL_PLAN_djwzm8pm7nf1pb767d7ea',
format=>'basic'));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
SQL handle: SQL_d8f3f345667a3835
SQL text: select count(a_no) from spm1.tbl_a
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Plan name: SQL_PLAN_djwzm8pm7nf1pb767d7ea Plan id: 3077036010
Enabled: YES Fixed: NO Accepted: YES Origin: AUTO-CAPTURE
Plan rows: From dictionary
--------------------------------------------------------------------------------
Plan hash value: 849991529
------------------------------------
| Id | Operation | Name |
------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | SORT AGGREGATE | |
| 2 | TABLE ACCESS FULL| TBL_A |
------------------------------------ “select count(a_no) from spm1.tbl_a;”の実行時に生成された実行計画が表示されました。索引も無い簡単なテストテーブルですので、当然TABLE ACCESS FULLが選択されています。
2. 5. 実行計画が変わるとベースラインが再取得される
それでは、ここでわざと先ほどのテストテーブルに索引を追加します。選択される実行計画が変わりますので、select count実行時に計画ベースラインが再取得されます。 ここではあえて実行計画を変動させたいので、既に取得されているベースラインが使われないよう「optimizer_use_sql_plan_baselines」はFALSEにしておきます。
SQL> -- ベースラインの使用をOFFにする
SQL> alter session set optimizer_use_sql_plan_baselines=FALSE;
セッションが変更されました。
SQL> select name,value from v$parameter where name like'%sql_plan%';
NAME VALUE
--------------------------------------------- --------------------
optimizer_capture_sql_plan_baselines TRUE
optimizer_use_sql_plan_baselines FALSE
SQL> -- tbl_a 表に索引を作成し、再度select countを実行
SQL> create index spm1.ind_tbl_a on spm1.tbl_a(a_no) tablespace users;
索引が作成されました。
SQL>
SQL> select count(a_no) from spm1.tbl_a;
SQL> select count(a_no) from spm1.tbl_a;
SQL> -- ベースラインが新たに取得されているか確認
SQL> select sql_handle,sql_text, plan_name from dba_sql_plan_baselines where sql_text like '%tbl_a%';
SQL_HANDLE SQL_TEXT PLAN_NAME
----------------------------------- -------------------------------------------------------------------------------- --------------------------------------------------
SQL_d8f3f345667a3835 select count(a_no) from spm1.tbl_a SQL_PLAN_djwzm8pm7nf1pb767d7ea
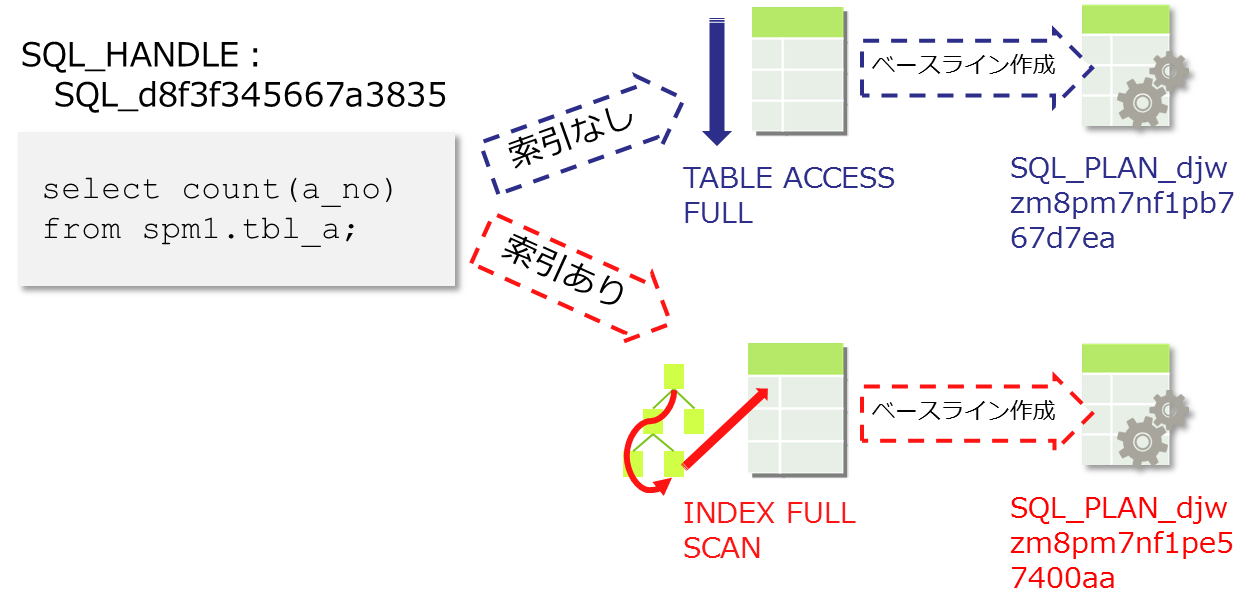
SQL_d8f3f345667a3835 select count(a_no) from spm1.tbl_a SQL_PLAN_djwzm8pm7nf1pe57400aa ★<-- 同一SQLに対して新たなベースラインが取得されている 同一SQL(SQL_HANDLEで識別)に異なるPLAN_NAMEが紐づいている状態が確認出来ました。追加されたPLAN_NAMEの実行計画を「dbms_xplan.display_sql_plan_baseline」で確認するとINDEX FULL SCANとあり、先ほどのTABLE ACCESS FULLとは異なり索引へアクセスする方法が選択されたことが分かります(図3)。
SQL> -- 新たに取得されたベースラインの実行計画を確認
SQL> select * from table(
2 dbms_xplan.display_sql_plan_baseline(
plan_name=>'SQL_PLAN_djwzm8pm7nf1pe57400aa',
format=>'basic'));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
SQL handle: SQL_d8f3f345667a3835
SQL text: select count(a_no) from spm1.tbl_a
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Plan name: SQL_PLAN_djwzm8pm7nf1pe57400aa Plan id: 3849584810
Enabled: YES Fixed: NO Accepted: NO Origin: AUTO-CAPTURE
Plan rows: From dictionary
--------------------------------------------------------------------------------
Plan hash value: 204355710
--------------------------------------
| Id | Operation | Name |
--------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | SORT AGGREGATE | |
| 2 | INDEX FULL SCAN| IND_TBL_A | ★<-- 作成した索引が使用されている
--------------------------------------
21行が選択されました。 ■図3:同一SQL_HANDLEに複数PLAN_NAME(計画ベースライン情報)が登録される(※イメージ図)
2. 6. ベースラインの検証と承認
前述の通り、同一SQL(SQL_HANDLEで識別)に対して複数パターンの実行計画が生成された場合、異なる実行計画の情報それぞれが計画履歴として格納されます。ただし、使用可能となっているのは最初に格納された計画ベースラインのみで、2番目以降に自動収集された計画履歴は使用可能な状態(「dba_sql_plan_baselines」ビューでACCEPTED列=’YES’)になっていません。
SQL> -- 2番目に取得されたplanは使用が承認されていない
select sql_handle, sql_text, plan_name, accepted from dba_sql_plan_baselines where sql_text like '%tbl_a%';
SQL_HANDLE SQL_TEXT
--------------------- -----------------------------------------------
PLAN_NAME ACC
------------------------------- -----------
SQL_d8f3f345667a3835 select count(a_no) from spm1.tbl_a
SQL_PLAN_djwzm8pm7nf1pb767d7ea YES
SQL_d8f3f345667a3835 select count(a_no) from spm1.tbl_a
SQL_PLAN_djwzm8pm7nf1pe57400aa NOこの場合、ACCEPTED列がNOになっているplanの方が、性能が良い可能性があります。しかし、現在使用されている計画ベースラインを変更(対象となる計画履歴を手動で承認)しない限りは初めに格納された計画ベースラインが使われ続けます。
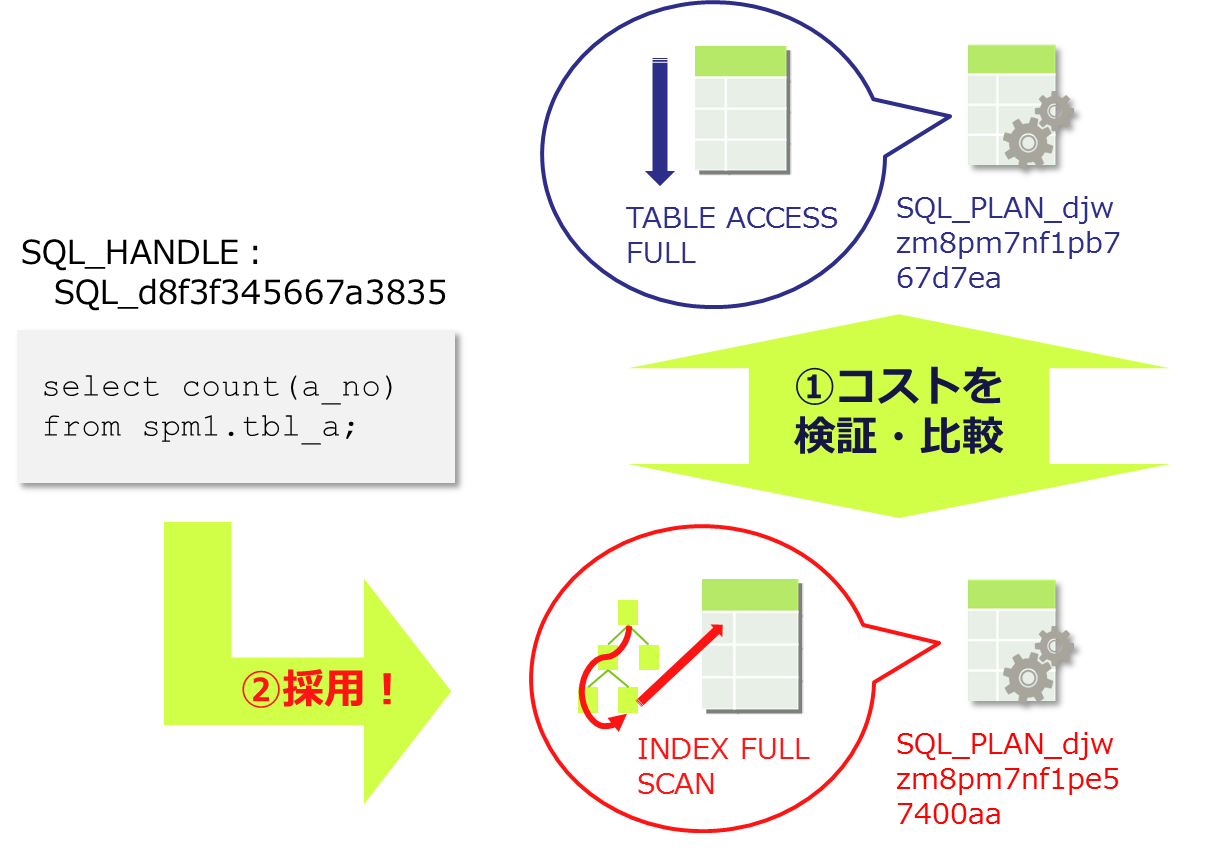
計画ベースラインを変更することなく(実行計画を固定化し続けて)運用することは、性能劣化のリスク抑制になります。しかし同時に、(統計情報や対照表のデータ傾向などが変わって)オプティマイザがより性能の良い実行計画を生成しようとした場合もその実行計画は採用されず、性能劣化もしない代わりに性能改善も行うことが出来ませんので、定期的に計画ベースラインの見直しを行うのが望ましいです。そこで、以下ではdbms_spm.evolve_sql_plan_baselineファンクションを使う例をご紹介します。DB内部で複数のplanを比較評価し、最も性能が良い実行計画を生成するplanを承認させます(図4)。
SQL> set serveroutput on
SQL> DECLARE
report clob;
BEGIN
report := DBMS_SPM.EVOLVE_SQL_PLAN_BASELINE(
sql_handle => 'SQL_d8f3f345667a3835');
DBMS_OUTPUT.PUT_LINE(report);
END;
/
GENERAL INFORMATION SECTION
---------------------------------------------------------------------------------------------
~~~ 中略 ~~~
Findings (2):
-----------------------------
1. 計画は0.01600秒で検証されました。検証されたパフォーマンスが、ベースライン計画のパフォーマンスを7.00000倍上回ったため、利点基準に達しました。 2. 計画は自動的に承認されました。
Recommendation:
-----------------------------
Consider accepting the plan.
EXPLAIN PLANS
SECTION
---------------------------------------------------------------------------------------------
Baseline Plan
-----------------------------
Plan Id : 1
Plan Hash Value : 3077036010
----------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost | Time |
----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 | 3 | 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 3 | | |
| 2 | TABLE ACCESS FULL | TBL_A | 100 | 300 | 3 | 00:00:01 |
----------------------------------------------------------------------
Test Plan
-----------------------------
Plan Id : 2
Plan Hash Value : 3849584810
------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost | Time |
------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 | 1 | 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 3 | | |
| 2 | INDEX FULL SCAN | IND_TBL_A | 100 | 300 | 1 | 00:00:01 |
------------------------------------------------------------------------
---------------------------------------------------------------------------------------------
PL/SQLプロシージャが正常に完了しました。 図4:dbms_spm.evolve_sql_plan_baselineで複数のPLAN_NAMEを検証・比較可能(※イメージ図)
2. 7. 不要なベースラインを削除
検証の結果、索引を使う実行計画の方がパフォーマンスが良いことが明らかになりましたので、TABLE ACCESS FULLの実行計画を生成する計画ベースラインは削除し、今後利用されないようにします。計画ベースラインの削除にはdbms_spm.drop_sql_plan_baselineファンクションを使用します。
SQL> -- 不要なベースラインを削除
SQL> declare
2 drop_plan PLS_INTEGER;
BEGIN
drop_plan :=dbms_spm.drop_sql_plan_baseline(sql_handle=>'SQL_d8f3f345667a3835',plan_name=>'SQL_PLAN_djwzm8pm7nf1pb767d7ea');
END;
/
PL/SQLプロシージャが正常に完了しました。
SQL> select sql_handle,sql_text, plan_name from dba_sql_plan_baselines where sql_text like '%tbl_a%';
SQL_HANDLE SQL_TEXT PLAN_NAME
----------------------------------- -------------------------------------------------------------------------------- --------------------------------------------------
SQL_d8f3f345667a3835 select count(a_no) from spm1.tbl_a SQL_PLAN_djwzm8pm7nf1pe57400aaベースラインの自動取得を使った実行計画の確認、検証、ベースラインの変更はこのような流れで行います。 パフォーマンスに問題のあるSQLが特定出来ている場合は、同様の流れで性能改善および実行計画の固定化へのアプローチを実現出来ます。
3. 12cR1までのSPMの課題
ここまでにSPMの機能として計画ベースラインを自動で取得させる方法をご紹介してきましたが、従来のリリースでは以下のような難点があり、便利な一方で、導入するには敷居が高い点があることも確かでした。
① 初回実行でハードパースされた後、再度実行されたSQLしかベースラインの自動取得がされない
…特に本番環境などは極力ハードパースさせない設計にしているDBが多く、任意のタイミングで計画ベースラインを得るには自動取得機能は不向きでした。
② 自動取得対象が大量だと管理面に難がある
…特に従来のリリースでは取得対象の絞り込みが出来ず、自動取得を仕掛けたまま放置した状態で大量のSQLが流れるとSYSAUXが肥大化する懸念がありました。また、自動取得したベースラインを定期的に見直す運用としたくても、取得されるSQLが多すぎて「承認」の管理プロセスを回すのが非常に大変になってしまうのが現実でした。
これらの課題について12c R2のSPMでは以下のような解決策が用意されています。
① の課題に対して:
手動ロードを行うことが可能です。従来のリリースでも本機能は存在しましたが、12c R2からはロード対象にAWRスナップショットが追加されました。
② の課題に対して:
12c R2から自動取得で有効に出来るフィルタ機能が追加されました。
次章では、新たに拡張されたSPM新機能について、使用例を交えてご紹介します。
4. 12c R2でのSPM新機能
SPMに関する 2つの新機能をご紹介します。
4. 1. SPM新機能① AWRからプランをキャプチャ :
<機能概要>
DBMS_SPM.LOAD_PLANS_FROM_AWRというPL/SQLプロシージャを使用して、AWRスナップショットに保存されている実行計画の情報をSPMが管理するベースラインとして手動追加します。
<計画ベースラインの手動ロードについて、旧リリースとの違い>
・従来のリリース(~12cR1)でも使用可能:
- カーソル・キャッシュからロード (DBMS_SPM.LOAD_PLANS_FROM_CURSOR_CACHE)
- SQLチューニング・セット(STS)からロード (DBMS_SPM.LOAD_PLANS_FROM_SQLSET)
・12c R2で追加された機能:
- AWRからロード (DBMS_SPM.LOAD_PLANS_FROM_AWR) ※使用可能な引数は(表1)参照
以下に、AWRスナップショット取得からベースライン取得手順の例を紹介します。
$ sqlplus / as sysdba
SQL> alter session set container=PDB1;
SQL> show con_name
CON_NAME
------------------------------
PDB1
SQL> -- ベースラインの自動取得がOFFであることを確認
SQL> select name,value from v$parameter where name like '%sql_plan%';
NAME VALUE
--------------------------------------- -------------------------
optimizer_capture_sql_plan_baselines FALSE
optimizer_use_sql_plan_baselines TRUE
SQL> -- AWRスナップショットを作成
SQL> EXEC DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();
PL/SQL procedure successfully completed.
SQL> -- 対象のSQLを実行
SQL> select count(b_no) from spm1.tbl_b;
SQL> -- AWRスナップショットを作成
SQL> EXEC DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();
PL/SQL procedure successfully completed.
$ sqlplus / as sysdba
SQL> alter session set container=PDB1;
SQL> show con_name
CON_NAME
------------------------------
PDB1
SQL> -- ベースラインの自動取得がOFFであることを確認
SQL> select name,value from v$parameter where name like '%sql_plan%';
NAME VALUE
--------------------------------------- -------------------------
optimizer_capture_sql_plan_baselines FALSE
optimizer_use_sql_plan_baselines TRUE
SQL> -- AWRスナップショットを作成
SQL> EXEC DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();
PL/SQL procedure successfully completed.
SQL> -- 対象のSQLを実行
SQL> select count(b_no) from spm1.tbl_b;
SQL> -- AWRスナップショットを作成
SQL> EXEC DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();
PL/SQL procedure successfully completed.
SQL> -- AWRスナップショットが作成されていることを確認
SQL> select snap_id,begin_interval_time,dbid from cdb_hist_snapshot order by snap_id;
SNAP_ID BEGIN_INTERVAL_TIME DBID
---------- ------------------------- ----------
1 10-FEB-17 01.14.37.000 PM 2885383322
2 10-FEB-17 03.58.27.693 PM 2885383322
3 10-FEB-17 04.40.04.483 PM 2885383322
4 10-FEB-17 04.40.20.882 PM 2885383322
5 13-FEB-17 11.30.41.032 AM 2885383322
6 13-FEB-17 11.30.58.779 AM 2885383322
7 13-FEB-17 11.32.41.593 AM 2885383322
7 rows selected.
SQL> -- AWRから手動ロード
SQL> VARIABLE cnt NUMBER
SQL> EXEC :cnt := DBMS_SPM.LOAD_PLANS_FROM_AWR(begin_snap=>6, end_snap=>7, basic_filter=>'sql_text like ''%tbl_b%''', dbid=>2885383322)
PL/SQL procedure successfully completed.
SQL> -- ベースラインが新たに取得されているか確認
SQL> select sql_handle,sql_text, plan_name from dba_sql_plan_baselines;
SQL_HANDLE SQL_TEXT PLAN_NAME
------------------------------ -------------------------------------------------- ------------------------------
SQL_3b549c0a70503a2a select count(b_no) from spm1.tbl_b SQL_PLAN_3qp4w19s50fjab63df4ab 表1:DBMS_SPM.LOAD_PLANS_FROM_AWRで使用する引数
| 引数 | 説明 |
|---|---|
| begin_snap, end_snap | AWRスナップショットの対象範囲をsnap_idで指定 |
| basic_filter | ロード対象のSQL_TEXTの絞り込み条件を追加 (where句と同じ要領で記載。like検索可能)デフォルトのNULLにするとスナップショットに記録されている全SQLの情報がロードされる |
| fixed | フィルタに指定した条件を元に自動取得の対象に含めるか(TRUE)除外するか(FALSE)を指定。NULLは検索条件を無視。 |
| dbid | (CDB$ROOTでなく)PDBで取得したAWRからロードする場合は、本引数にPDBのdbidを指定 |
4. 2. SPM新機能② ベースライン自動取得時のフィルタ機能
<機能概要>
SPM計画ベースラインをデータベースに自動で取得させる際に、取得対象に関してフィルタリングを行うことが出来るようになりました(図5)。
<ベースラインの自動取得について、旧リリースとの違い>
・従来のリリース(~12cR1)でも使用可能
- 複数回実行されたSQLすべてを対象に自動取得する
→ オーバーヘッド大、SYSAUX表領域の使用量大
- SYSAUX表領域の上限10%(デフォルト)まで使用する
- 53週間(デフォルト)保持される
・12c R2で追加された機能:
- 指定された条件に従いフィルタを作成、特定SQLのみ自動取得することが可能
→ オーバーヘッド最小化、SYSAUX表領域の使用量抑制
- フィルタ条件に使用できる要素(DBMS_SPM.CONFIGUREで設定)※(表2)参照
・SQLが解析(実行)されたスキーマ
・SQLを発行したプログラムのMODULE名
・SQLを発行したプログラムのACTION名
・発行されたSQL文字列( LIKE条件が適用される)
■図5:計画ベースライン自動取得時のフィルタ機能(12c R2~)
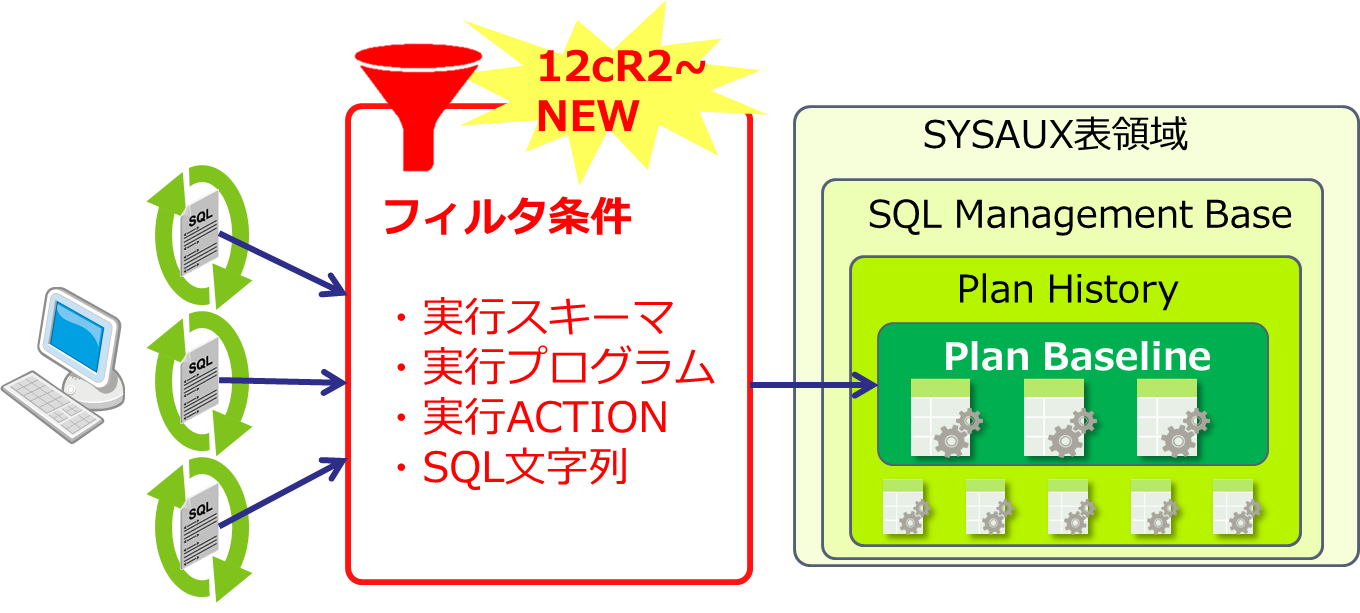
表2:DBMS_SPM.CONFIGUREで使用する引数
| 引数 | 説明 | 指定可能な値 |
|---|---|---|
| parameter_name | 自動取得用のフィルタの種類を指定。SQL文、スキーマ、モジュール、アクションに対して条件指定が可能。 | AUTO_CAPTURE_SQL_TEXT |
| AUTO_CAPTURE_PARSING_SCHEMA_NAME | ||
| AUTO_CAPTURE_MODULE | ||
| AUTO_CAPTURE_ACTION | ||
| parameter_value | 自動取得用のフィルタ検索条件を指定。 | フィルタの検索条件にSQL文を指定する場合、LIKE (when enable=>true)あるいは、NOT LIKE (when enable=>false)。その他は = (when enable=>true)あるいは、<> (when enable=>false)。 |
| enable | フィルタに指定した条件を元に自動取得の対象に含めるか(TRUE)除外するか(FALSE)を指定。NULLは検索条件を無視。 | TRUE |
| False | ||
| Null |
以下、フィルタ設定から実際にフィルタが機能していることを確認するまでの手順例を紹介します。
【例】実行スキーマ名でフィルタリングした場合①(SPM1ユーザのフィルタをTRUE)
SQL> -- スキーマ名でフィルタ
SQL> EXEC DBMS_SPM.CONFIGURE('AUTO_CAPTURE_PARSING_SCHEMA_NAME','spm1',true);
PL/SQL procedure successfully completed.
SQL> -- フィルタリング設定値の確認
SQL> SELECT PARAMETER_NAME, PARAMETER_VALUE FROM DBA_SQL_MANAGEMENT_CONFIG WHERE PARAMETER_NAME LIKE '%AUTO%';
PARAMETER_NAME PARAMETER_VALUE
----------------------------------- -----------------------------------
AUTO_CAPTURE_PARSING_SCHEMA_NAME parsing_schema IN (SPM1)
AUTO_CAPTURE_MODULE
AUTO_CAPTURE_ACTION
AUTO_CAPTURE_SQL_TEXT
SQL> -- ベースライン自動取得設定
SQL> alter system set optimizer_capture_sql_plan_baselines = TRUE;
SQL> select name,value from v$parameter where name like'%sql_plan%';
NAME
--------------------------------------------------------------------------------
VALUE
--------------------------------------------------------------------------------
optimizer_capture_sql_plan_baselines
TRUE
optimizer_use_sql_plan_baselines
TRUE
SQL> -- spm1 ユーザで実行(ベースラインが取得される)
SQL> conn spm1/test@pdb1
SQL> select count(a_no) from spm1.tbl_a;
SQL> select count(a_no) from spm1.tbl_a;
SQL> -- spm2 ユーザで実行(ベースラインは取得されない)
SQL> conn spm2/test@pdb1
SQL> select count(c_no) from spm2.tbl_c;
SQL> select count(c_no) from spm2.tbl_c;
SQL> select sql_handle,sql_text, plan_name from dba_sql_plan_baselines;
SQL_HANDLE
------------------------------
SQL_TEXT
--------------------------------------------------------------------------------
PLAN_NAME
--------------------------------------------------------------------------------
SQL_2bdf77bedbcdea50
SELECT CHAR_VALUE FROM SYSTEM.PRODUCT_PRIVS WHERE (UPPER('SQL*Plus') LIKE UPPE
SQL_PLAN_2rrvrrvdwvukhed88afee
SQL_bff897b9dbcabe27
SELECT ATTRIBUTE,SCOPE,NUMERIC_VALUE,CHAR_VALUE,DATE_VALUE FROM SYSTEM.PRODUCT_P
SQL_PLAN_bzy4rr7dwpgj7ed88afee
SQL_d8f3f345667a3835 select count(a_no) from spm1.tbl_a SQL_PLAN_djwzm8pm7nf1pb767d7ea 【例】実行スキーマ名でフィルタリングした場合②(SPM1ユーザのフィルタをFALSE) ※流れは①と同様。フィルタ設定でFALSEを設定。
SQL> -- スキーマ名でフィルタ
SQL> EXEC DBMS_SPM.CONFIGURE('AUTO_CAPTURE_PARSING_SCHEMA_NAME','spm1',false);
PL/SQL procedure successfully completed.
SQL> SELECT PARAMETER_NAME, PARAMETER_VALUE FROM DBA_SQL_MANAGEMENT_CONFIG WHERE PARAMETER_NAME LIKE '%AUTO%';
PARAMETER_NAME PARAMETER_VALUE
----------------------------------- -----------------------------------
AUTO_CAPTURE_PARSING_SCHEMA_NAME parsing_schema NOT IN (SPM1)
AUTO_CAPTURE_MODULE
AUTO_CAPTURE_ACTION
AUTO_CAPTURE_SQL_TEXT
SQL> -- spm1 ユーザで実行(ベースラインは取得されない)
SQL> conn spm1/test@pdb1
SQL> select count(a_no) from spm1.tbl_a;
SQL> select count(a_no) from spm1.tbl_a;
SQL> -- spm2 ユーザで実行(ベースラインが取得される)
SQL> conn spm2/test@pdb1
SQL> select count(c_no) from spm2.tbl_c;
SQL> select count(c_no) from spm2.tbl_c;
SQL> select sql_handle,sql_text, plan_name from dba_sql_plan_baselines;
SQL_HANDLE
------------------------------
SQL_TEXT
--------------------------------------------------------------------------------
PLAN_NAME
--------------------------------------------------------------------------------
SQL_824ce805cb9efd2e select count(c_no) from spm2.tbl_c SQL_PLAN_84m780r5txz9f5bee716c 次のパートではこのフィルタ機能の応用方法を模索し、より実用的な活用法をご紹介します。
5. 新たに実装されたフィルタ機能を使い倒す!
フィルタ機能の基本的な使い方を抑えたところで、実際にどのような活用が出来るのかをイメージできないとなかなか実運用には踏み切れないのが現実かと思います。 そこで以下2通りの活用方法をご提案します。
5. 1. 活用方法①:フィルタの組み合わせで特定のアプリ(プログラム)から実行されたSQLの実行計画だけを管理する
例えばOLTP処理の性能を管理する為、業務アプリケーションで発行されているSQLのみの計画ベースラインを収集しておきたいケースを想定します。
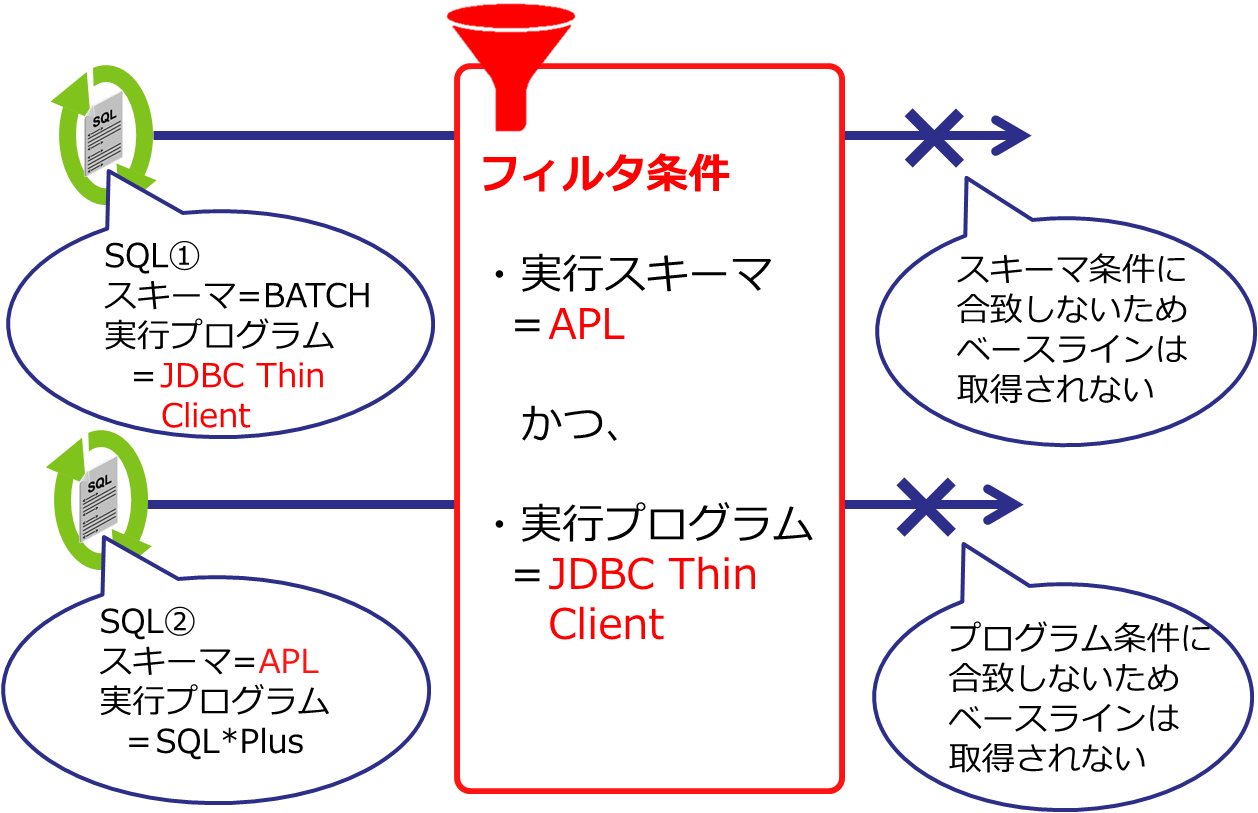
アプリケーションからの問い合わせに特定のユーザを使用(バッチ処理やメンテナンス業務は他のユーザでDBに接続)しているのであれば、以下のようにスキーマとモジュールを指定することで特定のアプリ(プログラム)で実行されたSQLのみが計画ベースラインの取得対象になります。条件を完全に満たさないSQLは対象外とされるので、クリティカルな業務処理だけを絞り込んで管理することが可能です(図6)。
SQL> EXEC DBMS_SPM.CONFIGURE('AUTO_CAPTURE_PARSING_SCHEMA_NAME','apl',true);
SQL> EXEC DBMS_SPM.CONFIGURE('AUTO_CAPTURE_MODULE','JDBC Thin Client',true);
SQL> SELECT PARAMETER_NAME, PARAMETER_VALUE FROM DBA_SQL_MANAGEMENT_CONFIG WHERE PARAMETER_NAME LIKE '%AUTO%';
PARAMETER_NAME PARAMETER_VALUE
----------------------------------- -----------------------------------
AUTO_CAPTURE_PARSING_SCHEMA_NAME parsing_schema IN (APL)
AUTO_CAPTURE_MODULE module IN (JDBC Thin Client)
AUTO_CAPTURE_ACTION
AUTO_CAPTURE_SQL_TEXT図6:複数条件を組み合わせた場合のフィルタ機能(※イメージ図)
5. 2. 活用方法②:性能を絶対死守したいクリティカルな処理だけ「キーワード」を追加して賢く運用
スキーマやモジュールなどの指定ではお目当てのSQLを絞り込めないケースも多々あるかと思います。そのような場合は「フィルタリング用に任意のキーワードをSQLのコメントとして追加する」という運用を検討すると良いのではないでしょうか。
SQL> EXEC DBMS_SPM.CONFIGURE('AUTO_CAPTURE_SQL_TEXT','%spm_target%',true);
PL/SQL procedure successfully completed.
SQL> SELECT PARAMETER_NAME, PARAMETER_VALUE FROM DBA_SQL_MANAGEMENT_CONFIG WHERE PARAMETER_NAME LIKE '%AUTO%';
PARAMETER_NAME PARAMETER_VALUE
----------------------------------- -----------------------------------
AUTO_CAPTURE_PARSING_SCHEMA_NAME
AUTO_CAPTURE_MODULE
AUTO_CAPTURE_ACTION
AUTO_CAPTURE_SQL_TEXT (sql_text LIKE %spm_target%)
SQL> conn spm1/test@pdb2
SQL> select /* spm_target */ count(a_no) from spm1.tbl_a; ★<-- コメント部分にキーワードを包含
SQL> select /* spm_target */ count(a_no) from spm1.tbl_a;
SQL> select count(b_no) from spm1.tbl_b; ★<-- キーワードが無いのでベースライン取得対象外
SQL> select count(b_no) from spm1.tbl_b;
SQL> conn spm2/test@pdb2
SQL> select count(c_no) from spm2.tbl_c; ★<-- キーワードが無いのでベースライン取得対象外
SQL> select count(c_no) from spm2.tbl_c;
SQL> select sql_handle,sql_text, plan_name from dba_sql_plan_baselines;
SQL_HANDLE
------------------------------
SQL_TEXT
--------------------------------------------------------------------------------
PLAN_NAME
--------------------------------------------------------------------------------
SQL_62b907ecdda6fd56 select /* spm_target */ count(a_no) from spm1.tbl_a SQL_PLAN_65f87xmfudzaqb767d7ea 処理が遅いSQLが判明している場合、対象のSQLにのみキーワードを付ければ他のSQLが取得対象になることはありませんので、SYSAUXの使用領域節約になり管理面でも楽になります。 また「性能劣化が起きてからSPMで実行計画を固定」という使い方だけでなく、フィルタ機能があれば「性能劣化の予防策としてSPMを活用」することができます。アプリケーションリリースや改修のタイミングに合わせて性能低下は全力で避けたいクリティカルなSQLにフィルタ用キーワードを追加することが可能であれば、計画ベースラインを使用して実行計画を固定化し、加えて定期的に計画履歴に蓄積されたプランを検証するという運用も実現可能です。
6. まとめ
SQLを個別にチューニングする手段として、以前から有効な手段の一つであったSPMですが、使用方法を熟知していないと大量に登録されたベースラインにより運用が困難になるなど、思わぬ落とし穴にはまる危険性もありました。今回12c R2で機能強化されたことにより、弱点が改善されて、より導入しやすくなったと感じます。
現在、SPMにはなかなか手を出せていなかったというデータベース管理者の皆さまも12c R2ではパフォーマンス問題やシステム移行時のお悩み解決の一助として、SPMを“賢く”使い倒しましょう!