
Pick Upテクノロジー
シバタツ流! DWHチューニングの極意
第4回 SQL書き換えテクニック
一度に処理する行数の多いデータウェアハウスにおけるバッチでは、少しやり方を変えることで大幅に性能が向上することがよくあります。今回はバッチでよく使われるSQLをどのように書き換えて、なぜそれによって速くなるのかについてご紹介しましょう。
大量行を処理する場合、まずはダイレクト・パスについて意識しましょう。第2回でダイレクト・パス・ロードについて簡単に触れましたが、このダイレクト・パスについてもう少し詳しく説明します。
まず、通常のSELECTはどのように行われているかのおさらいです。SELECT対象のデータ・ブロックがデータベース・バッファ・キャッシュになかった場合、データ・ブロックはストレージから読まれ、データベース・バッファ・キャッシュに書き込んでからクライアントに返されます。一方、ダイレクト・パス読取りでは、データ・ブロックはストレージから読まれた後、データベース・バッファ・キャッシュに書き込まずに直接クライアントに返されます。このようなキャッシュを使わない処理をダイレクト・パスと呼びます。
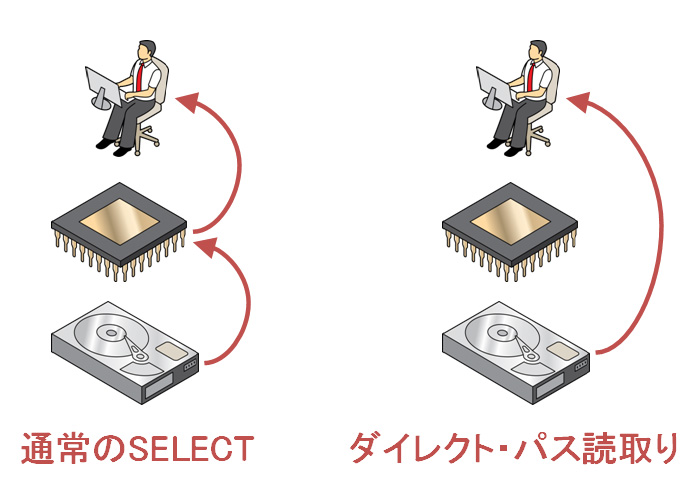
一般的なデータウェアハウスでは、データ量に比べてデータベース・バッファ・キャッシュが小さいのでキャッシュ・ヒット率が悪くなります。そのため大量のデータをSELECTする場合にはキャッシュによる性能向上は期待できず、通常のSELECTよりもキャッシュ管理のコストが省けるダイレクト・パス読取りしたほうが速くなることが多いです。
■UPDATE文
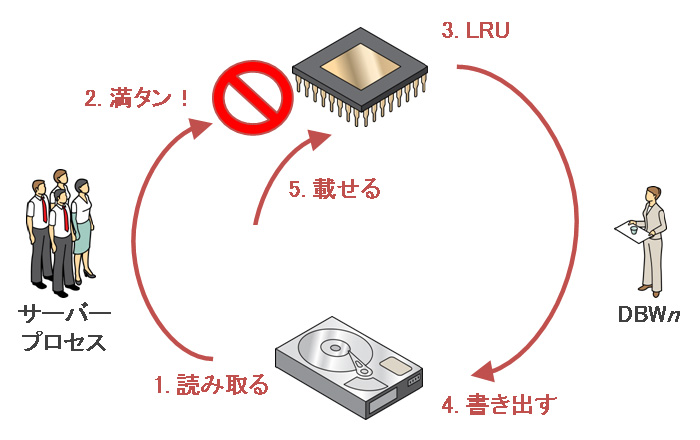
それではデータウェアハウス上でUPDATE文を実行するときのデータベース・バッファ・キャッシュの動きについて考えてみましょう。たとえば1GBのキャッシュがある環境で100GBの表を全件UPDATEするとき、1GB分のデータが更新された後は、ストレージから次のデータ・ブロック読み取る→キャッシュが満タン!→LRUアルゴリズムによって書出し対象のデータ・ブロックを決める→DBWnプロセスがストレージに書き出す→更新したデータ・ブロックをキャッシュに載せる→ストレージから次のデータ・ブロック読み取る......という処理が残り99GB分で延々と行われます。なんだかとても効率が悪いですね。
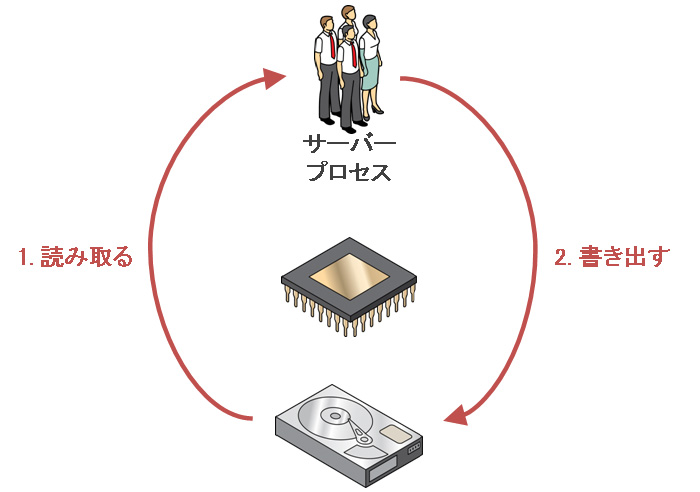
そこでこのUPDATE文をダイレクト・パス読取りしてダイレクト・パス・インサートするINSERT SELECT文に書き換えることで、ストレージからデータ・ブロック読み取る→ストレージに新しいデータ・ブロックを書き出すというだけの処理にすることができます。
以下のようなUPDATE文を考えてみましょう。
UPDATE seles_ledger
SET tax_rate = 9.9
WHERE
sales_date = '2009-01-01'
AND tax_rate = 9.3
;
これを以下のように書き換えることで、同じことがダイレクト・パスだけで行えます。更新する行が(正確に言うと更新するブロック数が)全体の多くを占めれば占めるほど、このように書き換えたほうが高速になります。
CREATE TABLE sales_ledger_new
NOLOGGING
PARALLEL
AS
SELECT
.......,
CASE
WHEN
sales_date = '2009-01-01'
AND tax_rate = 9.3
THEN 9.9
ELSE tax_rate
END tax_rate,
.......
FROM sales_ladger
;
RENAME sales_ledger TO sales_ledger_old;
RENAME sales_ledger_new TO sales_ledger;
DROP TABLE sales_ledger_old;
上記の例ではパラレル句のついた表を CREATE TABLEしているので、必ずダイレクト・パスになります。INSERT /*+ APPNED */ INTO sales_ledger_new SELECT ... 文を使用しても良いでしょう。また、UPDATE文ではNOLOGGINGにすることができませんが、CREATE TABLE AS SELECT文はNOLOGGINGを指定できますので、必要なければREDOログの出力をなくすことでより高速にすることができます。
ただし、RENAME文は1秒程度で終わるものの、SALES_LEDGER表が存在しない瞬間が1秒程度は発生しますので、同時に実行しているクエリーやバッチがある場合は注意する必要があります。
SALES_DATE列でレンジ・パーティショニングされている場合は、第3回で紹介したパーティション・エクスチェンジと組み合わせることでさらに高速化できます。
CREATE TABLE sales_ledger_20090101
NOLOGGING
PARALLEL
AS
SELECT
.......,
CASE
WHEN tax_rate = 9.3
THEN 9.9
ELSE tax_rate
END tax_rate,
.......
FROM sales_ladger
WHERE sales_date = '2009-01-01'
;
ALTER TABLE sales_ladger
EXCHANGE PARTITION r20090101 WITH sales_ledger_20090101
WITHOUT VALIDATION
;
DROP TABLE sales_ledger_20090101;
■DELETE文
DELETE文を使用するよりTRUNCATE文を使用したほうが高速なことをご存知の方も多いでしょうが、TRUNCATE文では一部のデータだけを削除することができません。そのため、削除の条件となる列に索引を作成してDELETE文で削除しなければいけないこともあります。
たとえば以下のようなDELETE文で考えてみましょう。
DELETE FROM tx_log
WHERE symbol = 'JAVA'
;
これを以下のように書き換えることで、同じことがダイレクト・パスだけで行えます。削除する行が全体の多くを占めれば占めるほど、このように書き換えたほうが高速になります。
CREATE TABLE tx_log_new
NOLOGGING
PARALLEL
AS
SELECT * FROM tx_log
WHERE
symbol <> 'JAVA'
OR symbol IS NULL
;
RENAME tx_log TO tx_log_old;
RENAME tx_log_new TO tx_log;
DROP TABLE tx_log_old;
NOLOGGINGのメリット、RENAME文の注意点はUPDATE文の書き換えと同様です。
SYMBOL列でリスト・パーティショニングしているような場合は、ダイレクト・パスすら使用せずに削除できるので最も高速です。
ALTER TABLE tx_log
TRUNCATE PARTITION p_java
;
「トランザクション・データは60カ月分保持し、月次バッチで最も古い1カ月分を削除する」というような要件では、最も古いパーティションをDROP PARTITIONして、新たなパーティションをADD PARTITIONすればよいわけです。
■MERGE文
MERGE文とは更新先の表に該当する行が存在する場合はUPDATE、存在しない場合はINSERTするSQLで、UPSERT文と言われることもあります。たとえば、販売実績があったすべての従業員のボーナスがデフォルトで1,000ドルと挿入されているBONUSES表があり、給与が50,000ドル以下の従業員にボーナスを支給したいと思います。販売実績のあった従業員はデフォルトの1,000ドルに給与の1%を加えた額にボーナスを更新し、販売実績のない従業員(BONUSES表に載っていない従業員)は給与の1%をボーナスに設定するには以下のように行います。
SQL> SELECT * FROM employees ORDER BY employee_id;
EMPLOYEE_ID SALARY
----------- ----------
1 70000
2 35000
3 40000
4 36000
5 42000
6 60000
SQL> SELECT * FROM bonuses ORDER BY employee_id;
EMPLOYEE_ID BONUS
----------- ----------
1 1000
3 1000
5 1000
MERGE INTO bonuses b
USING employees e
ON (b.employee_id = e.employee_id)
WHEN MATCHED THEN
UPDATE SET b.bonus = b.bonus + e.salary * 0.01
DELETE WHERE (e.salary > 50000)
WHEN NOT MATCHED THEN
INSERT (b.employee_id, b.bonus)
VALUES (e.employee_id, e.salary * 0.01)
WHERE (e.salary <= 50000)
;
SQL> SELECT * FROM bonuses ORDER BY employee_id;
EMPLOYEE_ID BONUS
----------- ----------
2 350
3 1400
4 360
5 1420
これを以下のように書き換えることで、同じことがダイレクト・パスだけで行えます。
CREATE TABLE bonuses_new
NOLOGGING
PARALLEL
AS
SELECT
e.employee_id,
CASE
WHEN b.employee_id IS NOT NULL
THEN b.bonus + e.salary * 0.01
ELSE e.salary * 0.01
END bonus
FROM bonuses b
RIGHT OUTER JOIN employees e
ON b.employee_id = e.employee_id
WHERE e.salary <= 50000
;
RENAME bonuses TO bonuses_old;
RENAME bonuses_new TO bonuses;
DROP TABLE bonuses_old;
■PL/SQL
PL/SQLでカーソル処理している場合は、それが1回のSQLに書き換えられないかどうか検討してみてください。CやJavaなどの手続き型言語の頭のままPL/SQLを書き始めると、不必要なカーソル処理を思わず書いてしまうことがあります。
たとえば以下はVALID_FLAG列が1の行のみを新しい表に入れるPL/SQLです。
DECLARE
CURSOR log_cur IS SELECT id, description, valid_flag FROM logs;
BEGIN
FOR log IN log_cur LOOP
IF (log.valid_flag = 1) THEN
INSERT INTO logs_new VALUES (log.id, log.description);
END IF;
END LOOP;
COMMIT;
END;
/
以下では同じことを1回の INSERT SELECT 文で実行しています。APPENDヒントがついている場合、必ずダイレクト・パス・インサートになります。また、まとめて1回で書き込めるのでストレージの効率が良く、PL/SQLエンジンとSQLエンジンの切り替えコストも抑えられます。
INSERT /*+ APPEND */ INTO logs_new
SELECT id, description
FROM logs
WHERE valid_flag = 1
;
COMMIT;
INSERT SELECT文に書き換えられないような複雑な処理を行っている場合は、FORALLループを使用したバルク処理に書き換え、Oracle Database 11g Release 2 (11.2) から追加されたAPPEND_VALUESヒント句を使うという方法もあります。
バッチをCやJavaなどで書いている場合も同様に、できるだけ1回のSQLで処理するという点は重要です。特にCやJavaなどの場合は、そのバッチ・プログラムとOracle Database間の通信量も大きく変わってきてしまいます。
分かりやすくするため、今回の例はすべて、なるべく単純なものにしました。このくらい単純だと書き換えも簡単ですが、実際の現場で使われるSQLはもっと複雑なものでしょう。しかしこれらのSQLはバッチ処理などで頻繁に使用されていますので、もしバッチ処理の性能で困った場合には、ぜひ書き換えを試してみてください。
次回はついに最終回、「実行計画の取得と監視」に関する極意を伝授します!
■シバタツより
Oracle Exadataリリース当初から、お客様のSQLやデータを使用したPoC (Proof of Concept) を実施し続け、本番稼働しているたくさんのシステムのパフォーマンス・チューニングを行ってきました。2010年には米オラクルの開発部門に所属し、米国のお客様のPoCを実施しつつ、そこから見えてきたOracle Databaseのパフォーマンス課題の解決に取り組みました。
日米どちらのPoCでも共通に、いつも思うことは「もっとシンプルでいいのに」ということです。Oracle Databaseにはたくさんのパラメーターやらなんやらがありますが、OLTPでは効果があっても、データウェアハウスではほとんど効果がないどころか、逆に遅くなるだけということも。そこでこの連載では、データウェアハウスのパフォーマンス・チューニングに本当に効果があることだけにポイントを絞ってご紹介していきたいと思います。これらのチューニング手法はExadataに限ったものではなく、Oracle Databaseすべてにおいて使えるものですので、多くの方の参考になればと思います。
日本オラクル株式会社 テクノロジー製品事業統括本部 技術本部 Exadata技術部
プリンシパルエンジニア 柴田竜典(しばたたつのり)
