Pick Upテクノロジー シバタツ流! DWHチューニングの極意 第5回 統計情報と実行計画
この連載もついに最終回となりました。今までの連載で紹介したテクニックを使えば、ほとんどのデータウェアハウスは大幅に高速になるはずですが、統計情報の取得方法に問題があって想定どおりに動いていなかったら元も子もありません。
この連載もついに最終回となりました。今までの連載で紹介したテクニックを使えば、ほとんどのデータウェアハウスは大幅に高速になるはずですが、統計情報の取得方法に問題があって想定どおりに動いていなかったら元も子もありません。「SQLが遅い」という理由の一つに「実行計画が悪い」ということがありますが、オプティマイザは統計情報を基にして実行計画を作ります。なので、正しくない統計情報を使っていると正しくない実行計画が作られてしまい、その結果、SQLが遅いという結果になってしまいます。ある程度のコストが掛かる統計情報収集はデータの変更とリアルタイムで行われるわけではないので、統計情報を収集するタイミングや方法によっては現在のデータの実態を反映していない、正しくない統計情報になってしまいます。そこで今回は正しい統計情報の取り方と、その統計情報で正しい実行計画が作られたかどうかの監視の仕方についてご紹介します。
■いつ統計情報を収集するか
データウェアハウスの場合、データ量がどんどん増加していく傾向のものが多いでしょう。データ量が少ないときの統計情報から作られた実行計画では、結合方法にネステッド・ループが選ばれやすかったり、パラレル実行時の分散方法 (PQ_DISTRIBUTE) にBROADCAST(外部表のすべての行が各コンシューマに転送される方法)が選ばれたりしやすいですが、これらの方法はデータ量が多い場合には適切ではないことが多いです。そのため、適切なタイミングで統計情報を取得しなおすことで現在のデータに合った実行計画が検討しなおされ、性能が徐々に劣化していくという問題の発生を防げます。自動オプティマイザ統計収集をオフにしていなければ、このタスクが自動的に必要なタイミングで再収集してくれますが、オフにしている場合はデータの変化に合わせて統計情報を手動で取得しなおすことを忘れないようにしてください。再取得の時期の目安は表全体の10%が挿入 / 更新 / 削除されたタイミングです。
Oracle Database 11gの自動オプティマイザ統計収集は、月曜日から金曜日は22時から翌日2時まで、土曜日と日曜日は6時から翌日2時までの間に実行されるようにデフォルトでは設定されていますので、各システムの負荷状況に合わせて変更してください。現在の設定値はDBA_AUTOTASK_WINDOW_CLIENTSビューで確認でき、DBMS_SCHEDULER.SET_ATTRIBUTEプロシージャで変更することができます。ただ、DBMS_SCHEDULER.SET_ATTRIBUTEプロシージャは構文が複雑なので、Enterprise Managerから変更したほうが簡単でしょう。
■統計情報のロック
夜間バッチのタイミングによっては、自動オプティマイザ統計収集が実行される前の日次バッチでTRUNCATEされますが、自動オプティマイザ統計収集が行われた後にロードされなおすような表も存在するでしょう。このような場合はDBMS_STATS.LOCK_TABLE_STATSプロシージャを使用してください。このプロシージャを実行すると、DBMS_STATS.UNLOCK_TABLE_STATSプロシージャを実行するまで対象の表の統計情報は変更できなくなりますので、自動オプティマイザ統計収集が間違った再収集を行うことを防げます。
■統計情報のリストア
とはいえ、「年次バッチを考慮することを忘れた」などの様々な理由で、通常の状態を反映しない統計情報を取得してしまう場合もあるでしょう。そのようなときはDBMS_STATS.RESTORE_TABLE_STATSプロシージャを使用して、指定した日時の統計情報に戻すことができます。
履歴はデフォルトでは31日分保存していますが、この日数を変更したい場合はDBMS_STATS.ALTER_STATS_HISTORY_RETENTIONプロシージャで変更できます。現在の値はDBMS_STATS.GET_STATS_HISTORY_RETENTIONファンクションで確認できます。設定した日数を超えた履歴は1日に1回自動消去されますが、DBMS_STATS.PURGE_STATSプロシージャで手動削除することもできます。
■統計情報のエクスポートとインポート
本番環境のデータと量や個別値 (NDV) に違いがないテスト環境が存在する場合は、そちらの環境で統計情報を取得し、DBMS_STATS.EXPORT_TABLE_STATSプロシージャで統計情報を書き出し、本番環境にDBMS_STATS.IMPORT_TABLE_STATSプロシージャを使って読み込むことで、本番環境での統計情報取得時の負荷をなくすことができます。ただし、テスト環境のデータ量が少なかったり、ダミー・データのためにNDVの数が本番より少なかったりする場合には、正しくない統計情報を使用してしまうことになりますので注意してください。
※個別値 (NDV) とは: Number of Distinct Valueの略で、1つの列に存在する値の種類の数のことです。たとえば「性別」列の値は「男」か「女」の2種類なので、NDVは最大2です。Oracle Databaseは統計情報の一つとしてNDVを収集しています。
また、この方法はDBMS_STATS.ALTER_STATS_HISTORY_RETENTIONプロシージャで設定した期間よりも古い統計情報でリストアしたい場合などにも有効です。信頼できる統計情報をDBMS_STATS.EXPORT_TABLE_STATSプロシージャでバックアップしておくと、万が一の時にも安心です。
■統計情報の保留と比較
新しい統計情報に万が一問題があった場合でも、統計情報のリストアやインポートによって簡単に元に戻すことができますが、いずれの方法も問題発生後の対応になってしまいます。しかし、Oracle Database 11gからは統計情報を保留することで事前対応が行えるようになりました。
Oracle Database 11gからは統計プリファレンスにPUBLISHが追加されました。PUBLISHはデフォルトではTRUEであるため、収集された統計情報は自動的に公開されてオプティマイザにすぐに使用されますが、これをFALSEにしておくと、そのあとに収集された統計情報は公開されずに保留されます。以下ではUSER1ユーザーのTAB1表のPUBLISHプリファレンスをFALSEに変更しています。
EXEC DBMS_STATS.SET_TABLE_PREFS('user1', 'tab1', 'PUBLISH', 'FALSE');保留中の統計情報をオプティマイザは使用しませんが、OPTIMIZER_USE_PENDING_STATISTICSパラメータをTRUEにしたセッションだけは保留中の統計情報を使用します。つまり、現在の信頼できる統計情報を使用中のユーザー・アプリケーションが実行されている環境で、並行してOPTIMIZER_USE_PENDING_STATISTICSパラメータがTRUEのテスト・スクリプトが新しい統計情報を使って各SQLをテスト実行することで、性能劣化が起きるかどうかを事前確認することができます。
ALTER SESSION OPTIMIZER_USE_PENDING_STATISTICS = TRUE;
保留中の統計情報によって性能劣化が起きないことが確認できたら、これをDBMS_STATS.PUBLISH_PENDING_STATSプロシージャを使って公開します。
EXEC DBMS_STATS.PUBLISH_PENDING_STATS('user1', 'tab1);
性能劣化が起きてしまい、保留中の統計情報を採用しない場合はDBMS_STATS.DELETE_PENDING_STATSプロシージャを使って削除します。
EXEC DBMS_STATS.DELETE_PENDING_STATS('user1', 'tab1);
なぜ性能劣化が起きてしまったのかを原因を分析したい場合はDBMS_STATS.DIFF_TABLE_STATS_IN_PENDINGファンクションが役に立ちます。このファンクションによって保留中の統計情報と現在の統計情報(または指定した日時の履歴)とを比較できます。同様にDBMS_STATS.DIFF_STATS_IN_HISTORYファンクションを使えば履歴と現在の統計情報(または履歴同士)を比較することができます。
「突然の性能劣化が怖くて自動オプティマイザ統計収集を使えない」という方や「突然の性能劣化が怖くて稼働後には統計情報を再収集しない」という方は、この保留と比較を検討してみてください。
■どのようにして統計情報を取得するか
自動オプティマイザ統計収集ではなく、手動で統計情報を所得するときはDBMS_STATSパッケージを使用します。ANALYZE文は下位互換のために残されたものですので使用しません。DBMS_STATS.GATHER_TABLE_STATSプロシージャにはいろいろなパラメータが存在しますが、ownnameとtabname以外は特に指定する必要ないでしょう。これはDBMS_STATS.GATHER_SCHEMA_STATSプロシージャやDBMS_STATS.GATHER_DATABASE_STATSプロシージャを使うときも同様です。
estimate_percentを設定しない場合(デフォルトのAUTO_SAMPLE_SIZEを使用する場合)、Oracle Database 11gではNDVなどを考慮した新たなアルゴリズムが使用されますが、数値を指定した場合は従来と同じアルゴリズムが使用されます。Oracle Database 11gではAUTO_SAMPLE_SIZEでもestimate_percent=100にかなり近しい統計情報が短時間で取得できるようになっているので、まずはAUTO_SAMPLE_SIZEを試してみてください。
method_optを設定しない場合(デフォルトのFOR ALL COLUMNS SIZE AUTOを使用する場合)、列にヒストグラムが必要かどうか自動的に判断され、必要あれば自動的に作成されます。この判断には、その列がワークロードで使用されたかどうかという情報も使用されるので、システム稼働後に統計情報を再収集しない運用をしている場合はmethod_optでヒストグラムを必要な列を指定しておく必要があります。method_optについては第2回データ・ローディングの「データ・ローディング前の列使用統計情報の取得」も参考になるでしょう。
■増分統計収集
レンジ・パーティション表では、新しいパーティションにしか新しいデータが追加されないということが少なくありません。つまり、表全体の統計情報を再収集するときに、変更されたパーティションのみの再収集で済めばリソースの節約や時間の短縮になります。増分統計はOracle Database 11gから使用でき、以下の条件を満たす場合に自動的に行われます。
- パーティション表のINCREMENTALがTRUE
- パーティション表のPUBLISH値がTRUE
- DBMS_STATS.GATHER_xxx_STATSプロシージャのESTIMATE_PERCENTがAUTO_SAMPLE_SIZE
- DBMS_STATS.GATHER_xxx_STATSプロシージャのGRANULARITYがAUTO
すべての表のINCREMENTALをTRUEに変更したい場合、Oracle Database 11gで追加されたDBMS_STATS.SET_GLOBAL_PREFSプロシージャを使用すると簡単です。このプロシージャはINCREMENTALのほかにもPUBLISHやESTIMATE_PERCENTなどのデフォルト値を変更することができます。
EXEC DBMS_STATS.SET_GLOBAL_PREFS('INCREMANTAL', TRUE');
■拡張統計
1つの表の中のある2つの列が暗黙的な相関関係を持っていることは少なくありません。たとえば現在使用しているPCのアンケート調査を行った時、購入時期とメモリー容量には相関関係があり、購入時期が新しいほどメモリー容量が多い傾向があると考えられます。
SELECT COUNT(*)
FROM ownpc
WHERE
year = 2011
AND memory_gb = 4
;
COUNT(*)
----------
13341
SELECT COUNT(*)
FROM ownpc
WHERE
year = 1999
ANE memory_gb = 4
COUNT(*)
----------
2
2011年に購入したPCを4GBメモリーで現在使用しているユーザーは13,341人でしたが、1999年に購入したPCを4GBメモリーで現在使用しているユーザーはたった2人でした。このような相関関係は個々の列統計情報だけでは分からないので、オプティマイザは正しい選択値(セレクティビティ)を計算できませんでした。このような場合にはOracle Database 11gで追加された拡張統計が有効です。DBMS_STATS.CREATE_EXTENDED_STATSファンクションで拡張統計を作成すると、その後の統計情報収集で拡張統計の値も収集されるようになります。
SELECT
DBMS_STATS.CREATE_EXTENDED_STATS('user1', 'ownpc', '(year,memory_gb)')
FROM dual
;
拡張統計は四則演算や関数などを使用した式も指定できます。たとえば郵便番号の上3桁が107の顧客数を数えるSQLがあったとします。
SELECT COUNT(*)
FROM customers
WHERE SUBSTR(zipcode, 1, 3) = '107'
;
このような場合には以下のような拡張統計を作成します。
SELECT
DBMS_STATS.CREATE_EXTENDED_STATS('user1', 'customers', '(SUBSTR(zipcode, 1,3))')
FROM dual
;
作成した拡張統計の名前などの定義を確認するにはUSER_STAT_EXTENSIONSビュー、削除するにはDBMS_STATS.DROP_EXTENDED_STATSプロシージャを使用します。
■いつディクショナリの統計情報を収集するか
ディクショナリの統計情報も適宜再収集する必要がありますが、自動オプティマイザ統計収集をオフにしていない限り、このタスクで自動的に適切なタイミングで収集されます。自動オプティマイザ統計収集をメイン・アプリケーションのスキーマでは適用したくないけれど、ディクショナリだけは自動オプティマイザ統計収集に任せたいという場合は、Oracle Database 11gから追加されたDBMS_STATS.SET_GLOBAL_PREFSプロシージャを使用して、AUTOSTATS_TARGETの値をAUTOからORACLEに変更してください。
EXEC DBMS_STATS.SET_GLOBAL_PREFS('AUTOSTATS_TARGET', 'ORACLE');
自動オプティマイザ統計収集に任せない場合はDBMS_STATS.GATHER_DICTIONARY_STATSプロシージャを適宜実行してください。
■いつ固定オブジェクトの統計情報を収集するか
動的パフォーマンス・ビュー(V$ビュー)が参照している動的パフォーマンス表(X$表)などの固定オブジェクトは自動オプティマイザ統計収集の対象ではありません。そのため、典型的なワークロードが実行されているときに一度、DBMS_STATS.GATHER_FIXED_OBJECTS_STATSプロシージャを実行することを勧めます。
■実行計画の監視
私が「このSQLにはチューニングの余地は少なそう」「このSQL実行には問題がありそう」などを判断するのに最初に使う機能は、Oracle Database 11gのOracle Tuning Packオプションに含まれるリアルタイムSQL監視です。Oracle Tuning PackというとチューニングのアドバイスをしてくれるSQLチューニング・アドバイザが有名ですが、「アドバンスなんていらない! 自分でチューニングする!」というユーザーにこそ最適なのがリアルタイムSQL監視です。
自動ワークロード・リポジトリ (AWR) とリアルタイムSQL監視は何が違うのでしょうか。AWRは特定期間のデータベース上で発生した様々な結果をレポートしてくれますが、リアルタイムSQL監視は特定のSQLによって発生した様々な結果をレポートしてくれます。AWRではその期間内にどのような待機イベントがどれだけ発生したかまでは分かりますが、リアルタイムSQL監視では特定のSQLの実行計画のどのステップでどのような待機イベントがどれだけ発生したかが分かります。たとえば、1つの開発環境で複数の開発者が自由なタイミングでSQLをテスト実行しているとき、AWRでは自分のSQLに問題があるのかどうか分かりにくいですが、リアルタイムSQL監視であれば自分が開発しているSQLだけのレポートが取得できます。
では、あるSELECT文のSQL監視レポートを見てみましょう。Oracle Database 11g Release 2 (11.2) からはSQL監視レポートをFlash / HTML / テキストのいずれかのフォーマットで取得でき、このレポートはFlashで取得したものです。
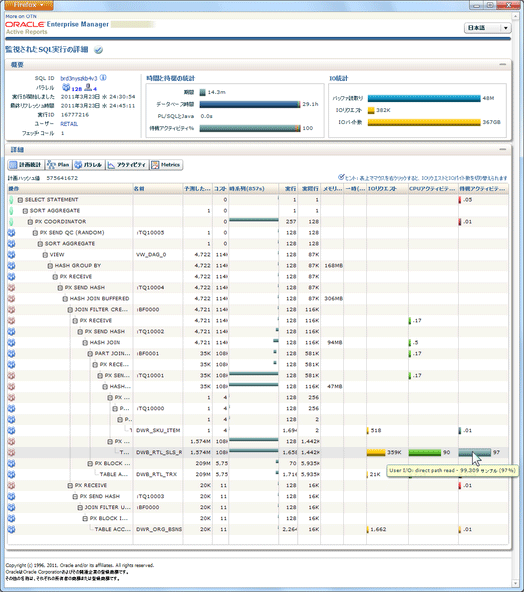
「計画統計」タブの「データベース時間」を見てみると、このSQLはユーザーI/O(濃い青の部分)がほとんどの時間を占めていることが分かります(このスクリーン・ショットでは濃い青の部分がユーザーI/Oだと分かりませんが、実際のレポートでは、バーにポインタを置くとラベルがポップアップされます)。「IOリクエスト」列を見てみるとDWB_RTL_SLS_RETURN_LINE_ITEM表で多くI/Oしていることが分かりますし、「待機アクティビティ%」列でもこの表の「User I/O: direct path read」が97%を占めていることが分かりますので、この表を圧縮するなりパーティショニングするなりして読取量を減らすのが良さそうです。また、統計情報という観点では、「予測した行」列と「実際行」列が極端に違う場合は統計情報に問題がある可能性があります。
今度は外部表からINSERT SELECT文でローディングしたときのSQLレポートの「アクティビティ」タブを見てみましょう。

パラレル度24で実行したので「並列度」の横線が24のところに引かれており、12物理コアのサーバーで実行したので「CPUコア」の横線が12のところに引かれています。赤く表示された「external table read」が多少発生していますが、緑で表示された「CPU (or wait for CPU)」がほとんどの場所で「CPUコア」の横線より上に来ているので、CPUはすでに100%使用されています。つまり、IOを速くして「external table read」をなくしても、これ以上CPUリソースが残っていないので速くはならないでしょう。速くするにはCPUコストの高いCSVフォーマットのフラットファイルから固定長フォーマットに変更するなどの対応が良さそうです。「CPUコア」の横線より「CPU (or wait for CPU)」が上に来ているのはHyper-Threadingが有効に働いていることを意味します。
このように、SQL単体の健康診断を行うのにSQL監視レポートはとても役立ちます。上記2つのレポートはSQL実行後に取得しましたが、SQL実行中にリアルタイムで取得することも可能です。実行中に取得すると実行計画のどのステップを現在行っているかが分かり、「予測した行」に対して現在何行処理したかが分かるので、あとどれくらいでそのSQLが終わるのかの見当がつきます。つまり「バッチのSQLが終わらないが、このまま終わるのを待つべきか、強制終了するべきか......」という悩みもリアルタイムSQL監視で解決できます。
リアルタイムSQL監視をインタラクティブに取得するにはEnterprise Managerを使用するのが良いでしょう。テスト・スクリプトに含めるなどのためにバッチで取得する場合はDBMS_SQLTUNE.REPORT_SQL_MONITORファンクションでSQL監視レポートを取得できます。以下は直前のSQLのレポートをテキスト形式で画面表示するシンプルな方法です。ファイルとして保存する場合はSQL*PlusのSPOOLコマンドなどを使用します。
SET LONG 10000000
SET LONGCHUNKSIZE 10000000
SET LINESIZE 200
SELECT DBMS_SQLTUNE.REPORT_SQL_MONITOR FROM dual;
パラレル実行されたSQL と5秒以上掛かったSQLが自動的に監視対象になりますので、それ以外を監視対象にしたい場合はMONITORヒントを使用してください。レポートを取得できるSQLの一覧はV$SQL_MONITORビューで確認できます。
■実行計画の管理
統計情報の保留を使うことで、新たに取得した統計情報を即座に反映せずに、事前チェックしてからその統計情報を採用するかどうかを判断できました。同様のことを実行計画レベルで行えるのがSQL計画管理です。たとえば、たまたま瞬間的にデータ量が少ないときに統計情報を再収集してしまい、実情を反映しない統計情報に変わってしまうことで効率の悪い実行計画となってしまい、今まで問題のなかったSQLのレスポンスが大幅に悪化するというような事故を防ぐことができます。
SQL計画管理を使用するには、まずは基礎となる実行計画であるSQL計画ベースラインを取得します。SQL計画ベースラインはOPTIMIZER_CAPTURE_SQL_PLAN_BASELINEパラメータをTRUEにすることで自動取得するか、AWRや共有SQL領域から手動ロードします。
オプティマイザがあらためてコスト計算を行って実行計画を構築したとき、SQL計画ベースラインに一致する実行計画があった場合はそれを使用します。見つからなかった場合、その新たな実行計画をSQL計画ベースラインではなくSQL計画履歴として保存し、(SQL計画履歴ではなく)SQL計画ベースラインの実行計画を使用します。つまり、統計情報が変わったとしてもSQL計画ベースラインが変わらない限り、常に同じ実行計画が使い続けられます。
データの変化に合わせたより良い実行計画が作られた可能性ももちろんありますので、適切なタイミングでSQL計画ベースラインの改良を行いましょう。DBMS_SPM.EVOLVE_SQL_PLAN_BASELINEファンクションを使用すると、SQL計画履歴内の実行計画とSQLベースライン内の実行計画を現在のデータでのコスト比較を行い、SQL計画履歴内の実行計画のほうが良ければ、その実行計画がSQLベースラインに追加されます。SQLベースラインに含まれる実行計画が複数になりますが、オプティマイザはその中で最小コストの実行計画を使用します。
SQL計画管理下の実行計画の詳細はDBMS_XPLAN.DISPLAY_SQL_PALN_BASELINEファンクションまたはDBA_SQL_PLAN_BASELINESビューで確認できます。ACCEPTED列がYESのものがSQLベースライン内のもの、NOのものが計画履歴内のものを意味します。
■おわりに
5回にわたった「シバタツ流! DWHチューニングの極意」もひとまずこれにて完了です。私が今まで行ってきたデータウェアハウスのパフォーマンス・チューニングを凝縮したつもりですが、いかがでしたでしょうか。読者の皆さんがデータウェアハウスの性能問題で困ったときの助けになればと思います。
11月9日から開催されるOracle DBA & Developer Days 2011では、私シバタツ自身が本連載の出張版セッションを行う予定ですので、よろしければぜひこちらにもご参加ください。また、OTNセミナーオンデマンドにもたくさんの役立つコンテンツがありますので、11月まで待てない方はこちらも併せてご利用ください。
オラクルエンジニア通信:「【セミナー動画/資料】複雑なSQLチューニングもラクにする!SQL監視機能とは」

イラスト:岡戸妃里
■シバタツより
Oracle Exadataリリース当初から、お客様のSQLやデータを使用したPoC (Proof of Concept) を実施し続け、本番稼働しているたくさんのシステムのパフォーマンス・チューニングを行ってきました。2010年には米オラクルの開発部門に所属し、米国のお客様のPoCを実施しつつ、そこから見えてきたOracle Databaseのパフォーマンス課題の解決に取り組みました。
日米どちらのPoCでも共通に、いつも思うことは「もっとシンプルでいいのに」ということです。Oracle Databaseにはたくさんのパラメーターやらなんやらがありますが、OLTPでは効果があっても、データウェアハウスではほとんど効果がないどころか、逆に遅くなるだけということも。そこでこの連載では、データウェアハウスのパフォーマンス・チューニングに本当に効果があることだけにポイントを絞ってご紹介していきたいと思います。これらのチューニング手法はExadataに限ったものではなく、Oracle Databaseすべてにおいて使えるものですので、多くの方の参考になればと思います。
日本オラクル株式会社 テクノロジー製品事業統括本部 技術本部 Exadata技術部
プリンシパルエンジニア 柴田竜典(しばたたつのり)