Data Science Service
A Oracle Cloud Infrastructure (OCI) Data Science é uma plataforma totalmente gerenciada para que equipes de cientistas de dados criem, treinem, implementem e gerenciem modelos de machine learning (ML) usando Python e ferramentas de código-fonte aberto. Use um ambiente baseado em JupyterLab para experimentar e desenvolver modelos. Amplie o treinamento do modelo com GPUs NVIDIA e treinamento distribuído. Leve os modelos para a produção e mantenha-os íntegros com os recursos das operações de ML (MLOps), como pipelines automatizados, implementações de modelos e monitoramento de modelos.

- O OCI Data Science oferece suporte aos modelos de peso aberto da OpenAI
A OpenAI anunciou o lançamento de dois modelos de peso aberto, gpt-oss-120b e gpt-oss-20b, que podem ser implementados e ajustados no OCI Data Science.
- Simplifique seu trabalho com modelos de base
Implemente, ajuste e avalie modelos de base com o OCI Data Science AI Quick Actions.
- Já disponível: Cohere Embed 4 no OCI Generative AI
Aprimore a geração aumentada de pesquisa e recuperação empresarial com o modelo de incorporação de alto desempenho mais recente da Cohere, agora acessível por meio da OCI.
- Experimente o OCI Data Science gratuitamente
Uma avaliação gratuita da Oracle Cloud permite acessar o OCI Data Science com US$ 300 em crédito gratuito na nuvem.
Como o OCI Data Science funciona?
O OCI Data Science é um serviço gerenciado abrangente projetado para agilizar o desenvolvimento, a implementação e a operacionalização de modelos de IA e machine learning. Os principais recursos incluem notebooks baseados em Jupyter para experimentação, ferramentas MLOps dimensionáveis para implementação e monitoramento de modelos e suporte integrado para grandes modelos de linguagem (LLMs) por meio do Hugging Face e outras estruturas.
Com ferramentas robustas para colaboração, detecção de anomalias e previsão, o OCI Data Science capacita as equipes a fornecer insights práticos de forma eficiente e segura.
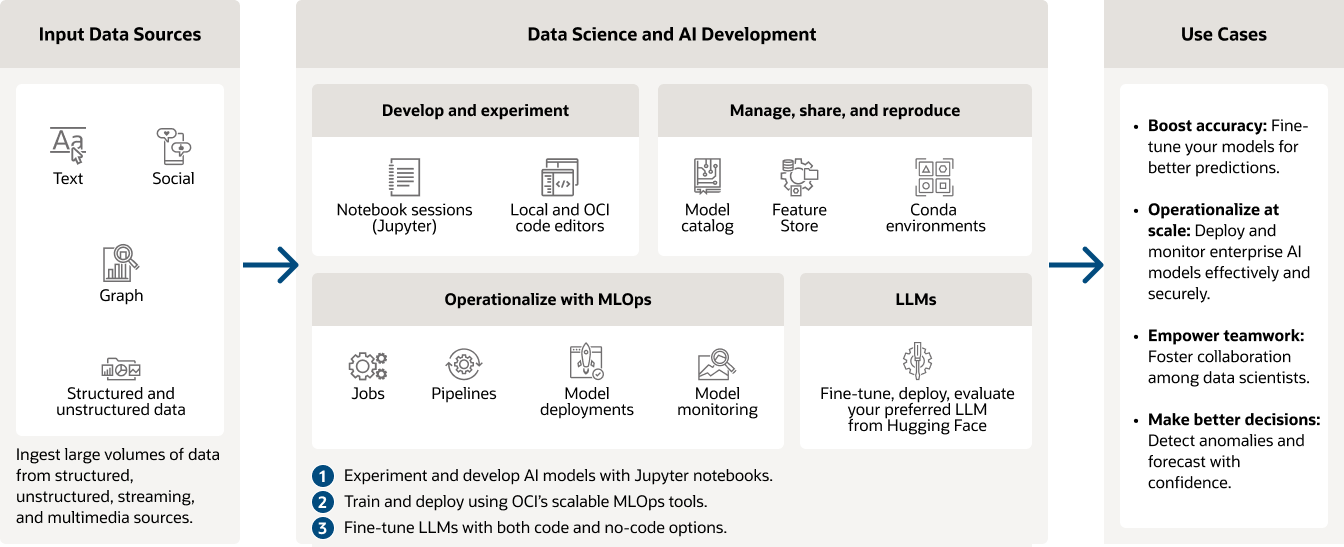
Casos de uso da OCI Data Science
Saúde: Risco de readmissão do paciente
Identificar fatores de risco e prever o risco de readmissão do paciente após a alta, criando um modelo preditivo. Use dados, como histórico médico do paciente, condições de saúde, fatores ambientais e tendências médicas históricas, para criar um modelo mais forte que ajude a fornecer o melhor atendimento a um custo menor.
Varejo: preveja o valor da vida útil do cliente
Use técnicas de regressão de dados para prever gastos futuros com clientes. Examine transações passadas e combine dados históricos de clientes com dados sobre tendências, níveis de receita e até fatores como o clima para criar modelos de ML que determinam se você deve criar campanhas de marketing para manter os clientes atuais ou adquirir novos clientes.
Manufatura: Manutenção Preditiva
Crie modelos de detecção de anomalias a partir de dados de sensor para detectar falhas no equipamento antes que elas se tornem um problema mais grave ou use modelos de previsão para prever o fim da vida útil de peças e máquinas. Aumente o período de disponibilidade de veículos e máquinas por meio de métricas de machine learning e monitoramento das operações.
Finanças: Detecção de fraude
Evite fraudes e crimes financeiros com ciência de dados. Crie um modelo de machine learning que possa identificar eventos anômalos em tempo real, incluindo valores fraudulentos ou tipos incomuns de transações.
O que é ciência de dados da OCI?
-
Ciência de dados de alto desempenho
Obtenha acesso a fluxos de trabalho automatizados para criação de modelos. Operacionalize o aprendizado de máquina facilmente com jobs reutilizáveis e orquestração de ponta a ponta para o ciclo de vida do AM. Execute cargas de trabalho distribuídas de alto desempenho com acesso a GPUs de menor custo.
-
Plataforma aberta
Espere o melhor de ML na Oracle através de parcerias importantes. Traga modelos, dados e código no formato necessário.
-
Melhor suporte da categoria
Beneficie-se do tratamento superior para parcerias estratégicas de ML. A Oracle tem cientistas de dados dedicados a garantir o sucesso da sua organização.
Sucessos e parcerias de clientes da OCI Data Science




Arquiteturas de referência de IA/machine learning
-
Playbook da solução
Descubra como os dados são armazenados, usados e analisados por um sistema de saúde para acompanhar a jornada de um paciente desde o diagnóstico até o tratamento e a recuperação.
-
Arquitetura de referência
Desenvolvimento de aplicativos modernos - ML e IA
Use esse padrão para criar plataformas de ML projetadas para cientistas de dados.
-
Criada e implementada
Implemente rapidamente uma arquitetura para lidar com segurança com grandes quantidades de dados de origem para criar modelos preditivos e usá-los em aplicações rapidamente desenvolvidas.
-
Arquitetura de referência
Enriqueça os dados de aplicações empresariais com dados brutos de outras fontes e use modelos de machine learning para trazer inteligência e insights preditivos aos processos de negócios.
Recursos do OCI Data Science
-
Aprendizado na nuvem