
スタッフのウェルビーイングを改善し、患者ケアを強化する
今日の医療システムは、従業員の燃え尽き症候群と人員不足という、相互に関連する2つの大きな課題に直面しています。調査対象となった医師と看護師の50%近くが、お役所的な管理タスクの負担が大きく、労働時間が長すぎるために、多くの燃え尽き症候群の症状を発症したと訴えています。その結果、多くの従業員が、より良いワークライフ・バランスを求めてこの業界を去ることを選択したため、病院は大きな人員不足の問題を抱えることになりました。米国の病院の半数以上が、看護師の欠員率が7.5%以上であり、残業代や派遣社員にかかる費用が2013年以来169%増加したと報告しています。残念ながら、多くの推定によれば、医療従事者不足は今後10年間で悪化する一方であるとされています。
これらの課題に対処するために、医療機関は、患者のエクスペリエンスと予後を改善しながら、医療従事者のウェルビーイングを優先するために、人員配置モデルを最適化し続けなければなりません。データプラットフォームの重要な役割は、医療機関が異種システムからのデータに一元的にアクセスできるようにし、高度な分析と機械学習モデルを使って、より正確に人員配置の必要性を予測できるようにすることです。このようなインサイトを活用することで、医療機関は、症例数のバランスを改善し、常に適切な人員を確保できるようになり、燃え尽き症候群を防ぎ、患者ケアを向上させることができます。
機械学習で医療スタッフ人員計画を簡素化
臨床データから患者について多くのことがわかるように、人材管理(HCM)システムなどの業務システムからも、臨床医やその他のスタッフの過去のスケジュール、労働時間、病欠など、医療機関は従業員についての多くの情報を得ることができます。以下のアーキテクチャが示すように、Oracle Data Platformは臨床データと運用データを統合し、高度な分析と機械学習を使用して、人員配置モデルが患者の転帰に与える影響、人員配置の意思決定が次の1週間の治療に与える影響、新型コロナウイルスの症例が再び急増した場合に埋める必要がある人員ギャップ、任意の時点における最適な人員配置モデル像などを、医療機関が把握できるようにします。
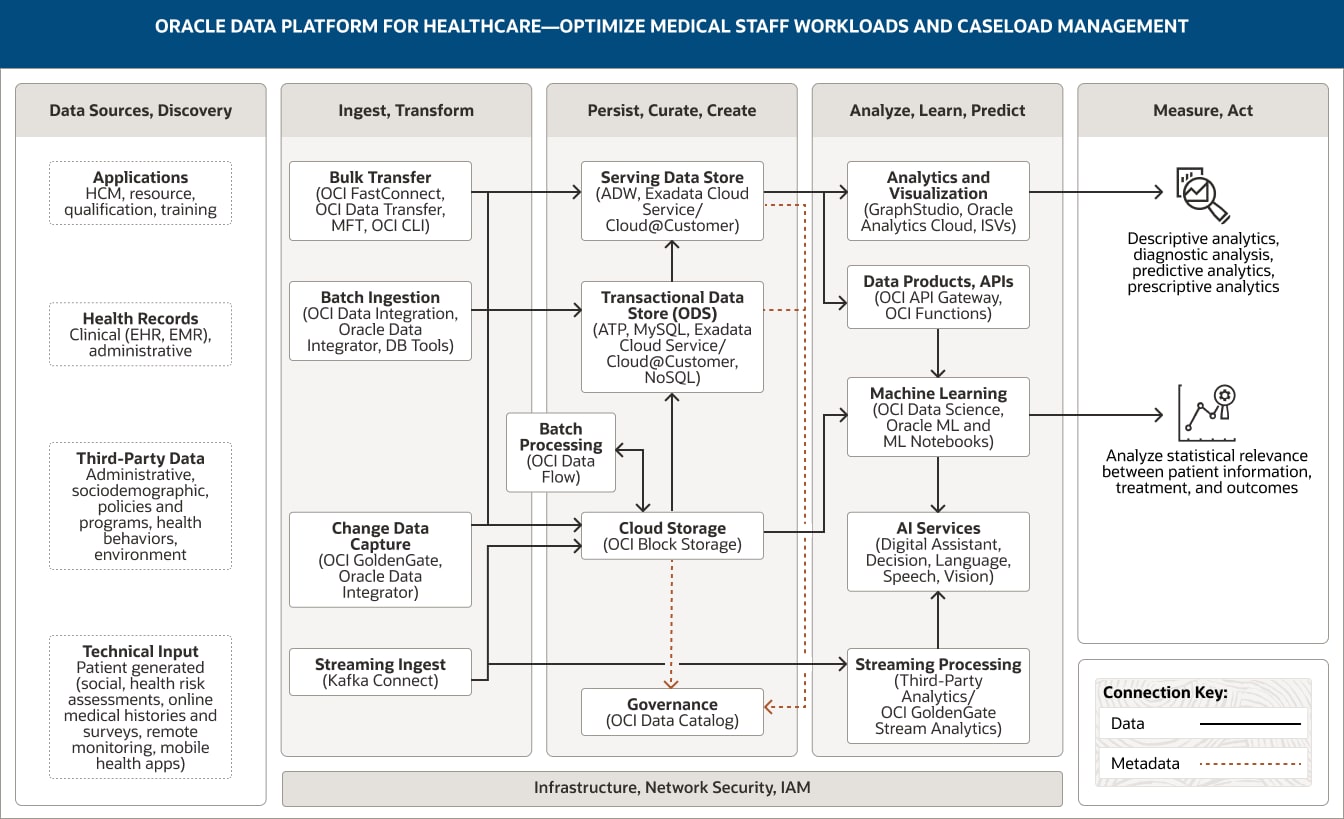
この図は、ヘルスケア向けOracle Data Platformを使用して、医療スタッフのワークロードを最適化する方法を示しています。このプラットフォームは、以下の5つの柱を掲げています。
- 1 データソース、検出
- 2 取込み、変換
- 3 永続化、キュレーション、構築
- 4 分析、学習、予測
- 5 測定、実行
データソース、検出の柱には、4つのカテゴリーのデータが含まれます。
- 1. アプリケーション・データは、HCM、リソース、資格、トレーニングなどのデータで構成されています。
- 2. 健康記録は、EHR、EMR、管理システムからのデータなど、臨床データを含みます。
- 3. サードパーティ・データは、行政データ、社会人口学的データ、およびポリシーやプログラム、健康に関わる行動、環境に関するデータから構成されています。
- 4. 技術的な入力データには、患者が作成したデータ(社会的データ、健康リスク評価、オンライン病歴、調査回答など)、遠隔監視やモバイルヘルス・アプリからのデータなどを含みます。
取込み、変換の柱は、4つの機能で構成されます。
- 1. 一括転送には、OCI FastConnect、OCI Data Transfer、MFT、OCI CLIを使用します。
- 2. バッチ取り込みには、OCI Data Integration、Oracle Data Integrator、DBツールなどを使用します。
- 3. 変更データの取得には、OCI GoldenGateとOracle Data Integratorを使用します。
- 4. ストリーミング取り込みにはKafka Connectを使用します。
4つの機能はすべて、永続化、キュレーション、構築のピラーの中で、サービング・データストア、クラウド・ストレージ、トランザクション・データストアに一方向に接続されています。
さらに、ストリーミングの取り込みは、分析、学習、予測の柱の中で、ストリーム処理に接続されます。
永続化、キュレーション、構築の柱は、5つの機能で構成されます。
- 1. サービング・データストアには、Autonomous Data Warehouse、Exadata Cloud Service、Exadata Cloud@Customerを使用します。
- 2. トランザクション・データストアには、Autonomous Transaction Processing、MySQL、Exadata Cloud Service、Exadata Cloud@Customer、NoSQLを使用します。
- 3. クラウド・ストレージには、OCI Object Storageを使用します。
- 4. バッチ処理には、OCI Data Flowを使用します。
- 5. ガバナンスには、OCI Data Catalogを使用します。
こうした機能は、柱の中で接続されています。クラウド・ストレージは、サービス・データストアには一方向に接続され、バッチ処理には双方向に接続されています。
トランザクション・データストアは、サービング・データストアに一方向に接続されています。
2つの機能が、分析、学習、予測の柱に接続されます。サービング・データストアは、分析と可視化機能、そしてデータ製品とAPI機能の両方に接続されています。クラウド・ストレージは、機械学習機能に接続します。
分析、学習、予測の柱は、5つの機能で構成されます。
- 1. 分析、可視化は、Oracle Analytics Cloud、GraphStudio、およびISVを使用します。
- 2. データ製品・APIは、OCI API GatewayとOCI Functionsを使用します。
- 3. 機械学習は、OCI Data Science、Oracle Machine Learning、Oracle ML Notebooksを使用します。
- 4. AIサービスは、Oracle Digital Assistant、OCI Decision、OCI Speech、OCI Language、OCI Visionを使用します。
- 5. ストリーミング処理には、OCI GoldenGate Stream Analyticsとサードパーティのストリーム分析を使用します。
3つの機能は、ピラーの中で接続されています。データ製品・API機能は、機械学習機能に一方向に接続されており、その機械学習機能はAIサービス機能に一方向に接続されています。また、ストリーム処理はAIサービス機能に一方向に接続されています。
サービング・データストア、トランザクション・データストア、オブジェクト・ストレージは、OCI Data Catalogにメタデータを提供します。
測定・実行のピラーは、医療スタッフの作業負荷の最適化と症例数管理をサポートするために、データ分析をどのように適用できるかを示します。これらのアプリケーションは、2つのグループに分けられる。
- 1. 第1のグループには、記述分析、診断分析、予測・処方的分析が含まれています。
- 2. 第2のグループには、患者情報、治療、結果に関する、統計的な関連性を分析することが含まれれています。
- 3. 3つの中心的なピラーである、取込み・変換、永続化・キュレーション・構築、分析・学習・測は、インフラストラクチャ、ネットワーク、セキュリティ、IAMでサポートされています。
医療機関が、各部門にとって最適なスタッフ配置を理解できるようにするために、データをアーキテクチャに取り込む方法は主に3つあります。
- 過去の人員配置と患者関連データは、将来の人員配置の必要性を理解し予測するために重要です。HCMアプリケーションは、過去の人員配置モデルや個々のスタッフに関するインサイトを得るのに必要な多くのデータを提供します。また、入退院・転院(ADT)アプリケーションは、各患者に関する基本的な詳細を提供します。このデータは、例えばソーシャルメディアからの非構造化データなど、サードパーティ・ソースからの患者データで強化することができます。変更データの取り込みが必要なリアルタイムまたはほぼリアルタイムの抽出は頻繁に行われます。また、OCI GoldenGateを介してHCMおよびADT運用システムからデータが定期的に取り込まれます。OCI GoldenGateは、「データ製品」が中心的なデータ・オブジェクトとなる、進化するデータ・メッシュ・アーキテクチャの重要なコンポーネントでもあります。
- さらに、ストリーミング・サービス/Kafkaを使用してウェアラブル・デバイスからリアルタイムで取り込まれるストリーミング・データを追加できるようになりました。たとえば、1日を通してスタッフの場所と動きを監視するGPS追跡機能を備えたウェアラブル・デバイスからデータを取り込み、スタッフをユニットや患者にうまく割り当てるために使用することができます。このストリーム・データ(イベント)が取り込まれ、いくつかの基本的な変換/集約が行われた後に、クラウド・ストレージにデータが保存されます。
- リアルタイムのニーズは進化していますが、医療システムからのもっとも一般的な抽出は、抽出、変換、ロード/抽出、ロード、変換プロセスを用いたバッチ取り込みです。バッチ取り込みは、ストリーミング取込みをサポートできないシステム(たとえば、古いメインフレーム・システム)からデータをインポートするために使用します。患者のニーズを完全に理解するためには、電子カルテ(EMR)や電子健康記録(EHR)システムなどの運用システムから、ほとんどの場合、Fast Healthcare Interoperability Resources プロトコルを介してデータを取り込む必要があります。データは、製品や地域を超えて提供されます。バッチ取り込みは、10分や15分といった頻度で行われることもありますが、それでもデータを個別のトランザクションではなく、グループでまとめて処理することになります。
収集されたすべてのデータに対する、データの永続化と処理のオプションは、4つのコンポーネントで構築されています。
- 取り込まれた生データは、バッチ処理用のクラウド・ストレージに保存され、必要なクレンジングやエンリッチメントなどが行われ、下流のユーザー(人、アプリケーション、機械学習プラットフォームなど)がデータを消費するのに適した状態に調整されます。一部のデータはサービング・データ・ストアに直接配置できますが、同時にクラウド・ストレージにも配置されます。このデータは、Sparkを使って処理されます。処理は、OCI Data Flowを使用して直接実行することも、OCI Data Integrationのオーケストレーション機能を使用して大規模なパイプラインの一部として実行することも可能です。処理されたデータセットはクラウド・ストレージに戻され、永続化、キュレーション、分析が行われ、最終的には最適化された形でデータ・ストアにロードされます。
- トランザクション・データストアは、運用レポートや、部門のデータウェアハウスまたはエンタープライズ・データウェアハウス(EDW)のデータソースとして使用されます。意思決定支援におけるEDWの補完的な要素であり、戦術的・戦略的な意思決定支援に使用されるEDWとは対照的に、運用上の報告、管理、意思決定に使用されます。運用データストア(ODS)は、通常、複数のソースからのデータを統合して永続化し、追加の運用、報告、制御、および運用上の意思決定支援に使用するように設計されたリレーショナル・データベースです。
- これで、最適化されたリレーショナル形式で、キュレーションや問合せのパフォーマンスのために、サービング・データ・ストアで永続化できるデータセットを作成しました。これにより、医療機関は、最適な人員配置計画を策定するために必要なすべてのデータと変数を調べることができるようになります。
分析、予測、実行する能力は、2つのテクノロジーに依存しています。
- 分析と可視化サービスは、記述的分析(ヒストグラムやチャートで現在の傾向を説明)、予測分析(将来の出来事を予測し、傾向を特定し、不確実な結果の確率を決定)、処方的分析(最適な意思決定を導く、適切な行動を提案)を提供します。これらを組み合わせることで、人員配置のニーズを予測し、適切な推奨事項を提案することができます。例えば、ある地域に住む患者の集団が、気温などの環境の変化にさらされ、特定の症状を示している場合、病気の流行が迫っているかどうかを分析を使って予測することができます。その場合、医療機関は、予想される症例数の増加に対応するために、スタッフ配置モデルを変更する必要があります。
- 高度な分析と同時に、機械学習モデルの開発、トレーニング、導入が行われます。これらの学習済みモデルは、現在および過去の運用データに対して実行でき、例えば、離職率の上昇につながるような不満を持つスタッフの増加などの事象や傾向を検出することができます。これらのイベントやその他の結果は、サービングレイヤーに戻して永続化し、Oracle Analytics Cloudなどの分析ツールを使用してレポートすることができます。また、モデルやデータをOCI Data Scienceなどの機械学習システムに送り込み、モデルをさらにトレーニングして、より効果的な人員配置モデルを推奨できるようにすることも可能です。こうしたモデルは、API経由でアクセスしたり、サービング・データストアに導入したり、OCI GoldenGateストリーミング分析パイプラインの一部として組み込むことができます。
- オラクルのキュレーション済み、テスト済み、かつ高品質なデータおよびモデルは、お客様のガバナンスルールやポリシーを適用し、データメッシュ・アーキテクチャ内のデータ製品(API)として公開し、医療機関全体に配布することが可能です。
人員配置を超えて:データを活用してその他の重要な医療課題に取り組む
Oracle Data Platformは、より正確で優れた人員配置モデルを開発する能力を医療機関に提供するだけでなく、他の分野でも業務を最適化して、患者ケアの向上、コストの削減、従業員エクスペリエンスの向上を支援することができます。以下に、その例をいくつか紹介します。
- 対象となる患者グループに対して、包括的かつ連携したケアを提供できます。
- パンデミックの流行が予測される場合、システム障害の可能性を事前に特定し、プロアクティブに介入することで、システムが成功するよう支援します。
- 患者コホートの傾向を監視し、ケアプログラムの有効性を評価します。
- 治療が過剰に行われている領域を特定します。
- 医療提供の品質とコストを監視します。
- 患者のリスクの階層化モデルを構築します。
- 患者の再入院のリスクを予測します。
- 患者の自己管理をサポートするために予防医療を推奨します。
関連リソース
-
ユース・ケース
医療系サプライチェーンの最適化
医療用Oracle Data Platformでサプライチェーンの回復力を高める方法をご紹介します。
-
ユース・ケース
人口健康管理
Oracle Data Platform for healthcareを活用して、人口健康管理を最適化し、患者のニーズをより良く満たし、予後を改善し、コストを削減する方法についてご紹介します。
-
ユース・ケース
パフォーマンス・モニタリングによる価値ベースのケアの改善
ヘルスケア向けOracle Data Platformを使用して、価値ベースのケア戦略の評価を簡素化する方法をご覧ください。
ここから始めよう
20以上のAlways Freeクラウド・サービスを30日間の試用版で試す
オラクルは、Autonomous AI Database、Arm Compute、Storageなどの一部のサービスについて時間制限のない無償枠を設けています。また、その他のクラウド・サービスをお試しいただけるよう、300米ドル分の無償クレジットもご用意しています。詳細をご確認のうえ、今すぐ無料アカウントにご登録ください。
-
Oracle Cloud Free Tierの内容
- 2つのAutonomous AI Databaseインスタンス、各20GB
- AMDおよびArm Compute VM
- 200GBの合計ブロック・ストレージ
- 10GBのオブジェクト・ストレージ
- 10TBのアウトバウンド・データ転送/月
- 10以上のAlways Freeサービス
- 300ドルの無料クレジットが30日間提供
段階的なガイダンスで学ぶ
チュートリアルとハンズオン・ラボを介して、幅広いOCIサービスを体験してください。開発者、管理者、アナリストのいずれであっても、OCIの仕組みを把握できるよう支援します。多くのラボは、Oracle Cloud Free TierまたはOracle提供の無料ラボ環境で実行されます。
-
OCIコア・サービスを使い始める
このワークショップのラボでは、仮想クラウド・ネットワーク(VCN)やコンピュートおよびストレージ・サービスを含むOracle Cloud Infrastructure(OCI)コア・サービスの概要を説明します。
OCIのコア・サービス・ラボを今すぐ始める -
Autonomous AI Databaseのクイック・スタート
このワークショップでは、Oracle Autonomous AI Databaseを使い始めるための手順について説明します。
Autonomous AI Databaseのクイック・スタート・ラボを今すぐ始める -
スプレッドシートからアプリを構築
この演習では、スプレッドシートをOracle Database表にアップロードし、この新しい表に基づいてアプリケーションを作成します。
このラボを今すぐ始める
150以上のベストプラクティス設計の詳細
アーキテクトなどのお客様が、エンタープライズ・アプリケーションからHPCまで、マイクロサービスからデータレイクまで、さまざまなワークロードをどのように導入しているかを参照してください。ベストプラクティスを理解し、当社のBuilt &Deployedシリーズで他のお客様のアーキテクトから話を聞くとともに、「Click to deploy」機能を使用して多くのワークロードをデプロイしたり、GitHubリポジトリから自分でデプロイすることができます。
一般的なアーキテクチャ
- Apache TomcatとMySQL HeatWave Database Service
- Oracle Weblogic on KubernetesとJenkins
- 機械学習(ML)およびAI環境
- Tomcat on ArmとOracle Autonomous AI Database
- ELKスタックによるログ分析
- OpenFOAMを使用したHPC
OCIのコスト削減効果をご覧ください
Oracle Cloudの価格は、わかりやすく、世界中で一貫性のある低価格であり、さまざまなお客様事例をサポートしています。コストを見積もるには、コスト見積ツールをチェックし、ニーズに応じて、サービスを設定します。
違いを体感してください。
- 1/4のアウトバウンド帯域幅コスト
- コンピューティングのコストパフォーマンスが3倍向上
- すべてのリージョンで同じ低価格
- 長期的なコミットメントのない低価格
-
次のような質問に回答します。
- OCIで最適に動作するワークロードは何ですか?
- オラクルへの投資全体を最大限に活用するには、どうすればよいですか?
- OCIは、他のクラウド・コンピューティング・プロバイダーと比較して、どうですか?
- OCIはIaaSとPaaSの目標をどのようにサポートできますか?