高可用性データ管理のためのOracle Berkeley DBレプリケーション
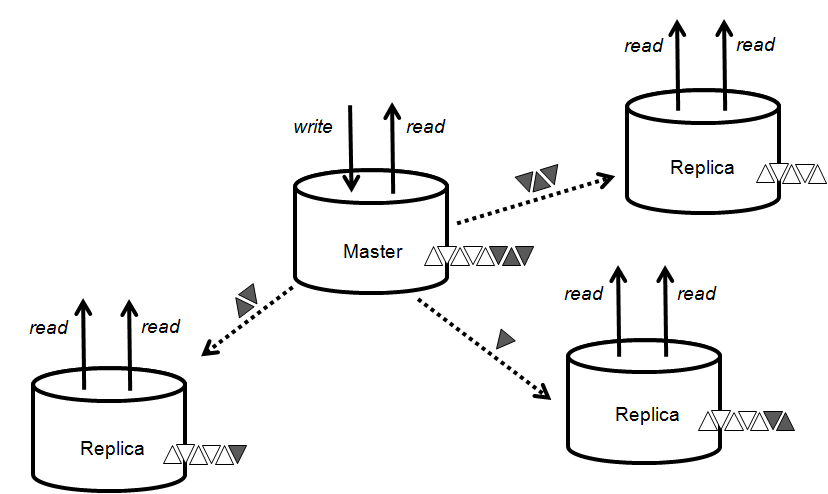
Berkeley DBによって、分散システムまたは冗長ハードウェアシステム内でレプリケーションを実行し、高可用性と水平方向の読み取りスケーラビリティを確保できます。Berkeley DB HAは自動フェイルオーバーに対応した、単一マスター、複数レプリカのシステムです。レプリカは読み取りを実行しますが、マスターは読み取りと書き込み操作を実行できます。レプリカはマスターまたは他のレプリカから送信された更新をトランザクション・ログ・レコードとして受け取り、ローカルで適用します。レプリカはマスターにステータスを通知し、マスターはその情報を使用して、レプリカグループ全体の整合性を管理します。レプリケートされたシステムの各ノードは、データとログの完全なコピーを保持します。このアーキテクチャにより、優れた読み取りスケーラビリティ、およびほぼ瞬時のフェイルオーバーが実現し、稼働時間はほぼ100 %になります。Berkeley DB HAを使用するアプリケーションは、単一システムの処理の制限を超えたスケーリングが可能であり、障害にも適切に対応して、可用性を最大化します。
Berkeley DB HAのインフラストラクチャは、TCP/IPだけではなくあらゆる通信システムをサポートします。このため、冗長システム間(ブレードなど)でカスタマイズされた内部の高速相互接続により、埋め込みハードウェアシステムのパフォーマンスが劇的に改善されます。ただし、Berkeley DBには、TCP/IPネットワークを介したレプリケーション・グループ管理のサポートも組み込まれています。
マスターノードのみがデータベースを変更できます。アプリケーションは作成、更新、削除リクエストをマスターで実行し、次いでマスターがそれらの変更を、要求された整合性のレベルを達成するのにアプリケーションが必要とする数のレプリカに自動配信します。即座に整合性が確保されるトランザクションでは、ノードのクォーラム、またはアプリケーションが要求する他の何らかの基準が必要です。読み取りはマスターとレプリカのどのノードからでも、いつでも処理できます。レプリカは、グループへの参加、離脱、あるいは再参加がいつでも可能であり、ニーズの変化に合わせてソリューションのサイズを調整できます。マスターに障害が発生すると、選出が実行され、特定されたノードが新しいマスターに昇格します。このソリューションでは、以下のことが可能です。
- 許容範囲を超える停止時間が発生している場合に、高速フェイルオーバーを実行
- 複数の読み取り専用レプリカを用意することで、読み取りのスケーラビリティを確保
- 効率の良いコミット処理を有効にし、(低速の)ディスクではなく(高速の)ネットワークにコミットすることで、アプリケーションの耐久性を確保
- すべての操作に単一の整合性モデルを適用しないことで、アプリケーションの柔軟性が向上
Berkeley DB HAは、次のような場所での使用に適します。
- 小規模LANベースのレプリケーション:企業サイトなど、狭い範囲の人々にデータを提供する、データセンターベースのサービス。このサービスは、同一のデータセンター内にあり、高速LANを介して通信するいくつかのサーバーによって実装されます。
- 広域データストア:世界中のどこからでもアクセスできる情報を保持している、世界規模のサービスプロバイダ。このサービスは、世界中に散在するさまざまなデータセンターに設置され、高速なデータセンター間接続を介して通信するサーバー群によって実装されます。
- マスター/スレーブ:マスターマシンとスレーブマシンの間でフェイルオーバーを実行する、シンプルなインストール。HAが広範な環境でデータをレプリケートする場合、データ管理およびレプリケーションのポリシーセットを1つしか用意しないことは適切ではありません。Berkeley DB HAでは、マスターとレプリカ間のデータ整合性レベル、トランザクションの耐久性の他、データのパフォーマンス、堅牢性、可用性に影響を与えるさまざまな設計オプションを、アプリケーション自身が制御できます。
マスターの選出は、分散された2フェーズの投票プロトコルを使用して行われるため、常に一意のマスターが選出されます。選出を行うには、適格なノードの単純過半数以上が、選出プロセスに参加している必要があります。参加している適格なノードの中で、環境の状態が最も新しいノードがマスターとして選出されます。適格なノードは、以下のいずれかのステータスになります。
- マスター:適格なノードの単純過半数によって選択されたノード。このノードはこのステータスにある間、読み取りおよび書き取りトランザクションの両方を処理できます。
- レプリカ:レプリケーション・ストリームを介してマスターと通信するノード。レプリケーション・ストリームは、マスターで行われた変更の追跡に使用されます。レプリケーション・ストリームについては、以降のセクションで詳しく説明します。レプリカは読み取りトランザクションのみをサポートします。
マスターは、レプリカが処理可能な速度で、レプリカに変更を非同期で送信します。トランザクションが進行している最中でも、アプリケーションがマスターのトランザクションをコミットしようとする前であっても、変更はレプリカに次々とストリーミングされます。その後、トランザクションがマスター上で中断された場合、レプリカもトランザクションを中断します。アプリケーション・スレッドは、トランザクションの耐久性の要件で必要とされる場合に、1つ以上のレプリカが特定のトランザクションに追いつくまで待機することがあります。そのようなトランザクションでは、レプリカは明示的な確認応答を返しますが、これはマスターでの進行を妨げるものではありません。マスターは、他のトランザクション作業を自由に進めることができます。
マスターによるレプリケーション・ストリームへの書き込み操作と、レプリカでの読み取り(および再実行)操作は、それぞれ非同期で行われます。マスターは、アプリケーションが新しいログエントリを作成するとすぐに、レプリケーション・ストリームに書き込むことができます。レプリカはレプリケーション・ストリームから読み取った変更をすぐに再実行し、マスターが要求する場合は、コミット操作の再実行の確認応答を返します。