AI infrastructure
Run the most demanding AI workloads faster, including frontier model training and inference, agentic AI, scientific computing, and recommender systems, anywhere in our distributed cloud. Use Oracle Cloud Infrastructure (OCI) Supercluster for up to 131,072 GPUs for performance at zettascale.

NVIDIA and OCI deliver scalable supercomputing, accelerated vector workloads, and AI applications
-
![]() Power Production AI with OCI and NVIDIA RTX PRO
Power Production AI with OCI and NVIDIA RTX PRO
See how OCI with RTX PRO 6000 GPUs and NVIDIA AI Enterprise helps you build and scale production AI faster.
-
![]() First Principles: Zettascale OCI Superclusters
First Principles: Zettascale OCI Superclusters
OCI's top architects reveal how cluster networks power scalable GenAI—from a few GPUs to a zettascale OCI Supercluster with 131,072 NVIDIA Blackwell GPUs.
![]() AI in Action: 10 Cutting-Edge Innovations to Explore Now
AI in Action: 10 Cutting-Edge Innovations to Explore Now
Discover 10 groundbreaking AI-driven technologies that are reshaping how organizations perform maintenance, engage with customers, secure data, deliver healthcare, and more.
-
![]() Enterprise Strategy Group on AMD Instinct MI300X
Enterprise Strategy Group on AMD Instinct MI300X
Discover the analyst’s perspective on OCI AI infrastructure with AMD GPUs and how this combination can improve productivity, accelerate time to value, and reduce energy costs.




Oracle and NVIDIA co-innovation
Discover how the two companies are accelerating AI adoption.
Why run on OCI AI infrastructure?

Performance and value
Boost AI training with OCI’s unique GPU bare metal instances and ultrafast RDMA cluster networking that reduce latency to as little as 2.5 microseconds. Get up to 220% better pricing on GPU VMs than with other cloud providers.

HPC storage
Leverage OCI File Storage with high performance mount targets (HPMTs) and Lustre for terabytes per second of throughput. Use up to 61.44 TB of NVMe storage, the highest in the industry for GPU instances.

Sovereign AI
Oracle’s distributed cloud enables you to deploy AI infrastructure anywhere to help meet performance, security, and AI sovereignty requirements. Learn how Oracle and NVIDIA deliver sovereign AI anywhere.
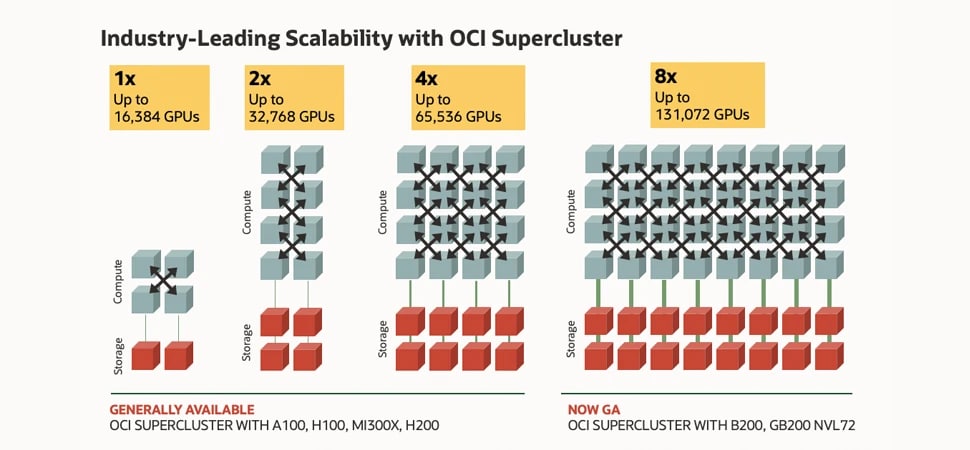 The image shows boxes that represent compute and storage, connected by lines for cluster networking. On the far left, there are four boxes of compute and two for storage for the smallest cluster with 16,000 NVIDIA H100 GPUs. To its right there are 8 boxes of compute and 4 boxes of storage for 32,000 NVIDIA A100 GPUs in a cluster. Next, there are 16 boxes of compute and 8 boxes of storage for 64,000 NVIDIA H200 GPUs. Finally, to the far right, there are 32 boxes of compute and 16 boxes of storage for 128,000 NVIDIA Blackwell and Grace Blackwell GPUs. This shows scalability of OCI Supercluster increasing by 8X from the smallest 16,000 GPU configuration on the far left to the largest 128,000 GPU configuration on the far right.
The image shows boxes that represent compute and storage, connected by lines for cluster networking. On the far left, there are four boxes of compute and two for storage for the smallest cluster with 16,000 NVIDIA H100 GPUs. To its right there are 8 boxes of compute and 4 boxes of storage for 32,000 NVIDIA A100 GPUs in a cluster. Next, there are 16 boxes of compute and 8 boxes of storage for 64,000 NVIDIA H200 GPUs. Finally, to the far right, there are 32 boxes of compute and 16 boxes of storage for 128,000 NVIDIA Blackwell and Grace Blackwell GPUs. This shows scalability of OCI Supercluster increasing by 8X from the smallest 16,000 GPU configuration on the far left to the largest 128,000 GPU configuration on the far right.
OCI Supercluster with NVIDIA Blackwell and Hopper GPUs
Up to 131,072 GPUs, 8X more scalability
Network fabric innovations enable OCI Supercluster to scale up to 131,072 NVIDIA B200 GPUs, more than 100,000 Blackwell GPUs in NVIDIA Grace Blackwell Superchips, and 65,536 NVIDIA H200 GPUs.
OCI AI infrastructure for all your needs
Whether you’re looking to perform inferencing or fine-tuning or train large scale-out models for generative AI, OCI offers industry-leading bare metal and virtual machine GPU cluster options powered by an ultrahigh-bandwidth network and high performance storage to fit your AI needs.
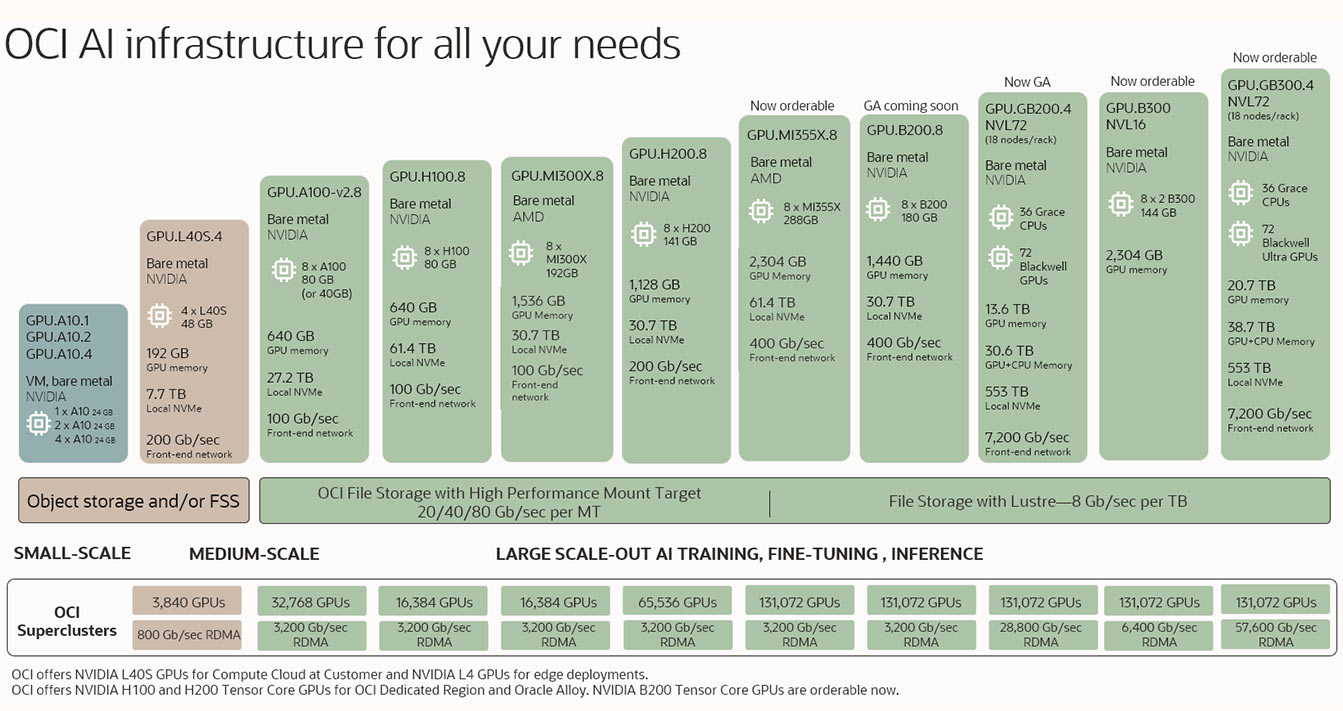 The image shows several products for AI Infrastructure starting on the bottom left with the smallest configurations then progressively increasing to medium scale and large scale configurations. The smallest configurations are with just 1 GPUs in a virtual machine and the largest configurations are for more than 100,000 GPUs in RDMA clusters.
The image shows several products for AI Infrastructure starting on the bottom left with the smallest configurations then progressively increasing to medium scale and large scale configurations. The smallest configurations are with just 1 GPUs in a virtual machine and the largest configurations are for more than 100,000 GPUs in RDMA clusters. Learn how to power production AI with OCI and NVIDIA RTX PRO.
Explore OCI Supercluster for large-scale AI training
Massive scale-out clusters with NVIDIA Blackwell and Hopper
Supercharged compute
• Bare metal instances without any hypervisor overhead
• Accelerated by NVIDIA Blackwell (GB200 NVL72, HGX B200),
Hopper (H200, H100), and previous-generation GPUs
• Option to use AMD MI300X GPUs
• Data processing unit (DPU) for built-in hardware acceleration
Massive capacity and high-throughput storage
• Local storage: up to 61.44 TB of NVMe SSD capacity
• File storage: Oracle-managed file storage with Lustre and high performance mount targets.
• Block storage: balanced, higher performance, and ultrahigh performance volumes with a performance SLA
• Object storage: distinct storage class tiers, bucket replication, and high capacity limits
Ultrafast networking
• Custom-designed RDMA over Converged Ethernet protocol (RoCE v2)
• 2.5 to 9.1 microseconds of latency for cluster networking
• Up to 3,200 Gb/sec of cluster network bandwidth
• Up to 400 Gb/sec of front-end network bandwidth
Compute for OCI Supercluster
OCI bare metal instances powered by NVIDIA GB200 NVL72, NVIDIA B200, NVIDIA H200, AMD MI300X, NVIDIA L40S, NVIDIA H100, and NVIDIA A100 GPUs let you run large AI models for use cases that include deep learning, conversational AI, and generative AI.
With OCI Supercluster, you can scale up to more than 100,000 GB200 Superchips, 131,072 B200 GPUs, 65,536 H200 GPUs, 32,768 A100 GPUs, 16,384 H100 GPUs, 16,384 MI300X GPUs, and 3,840 L40S GPUs per cluster.

Enlarge+
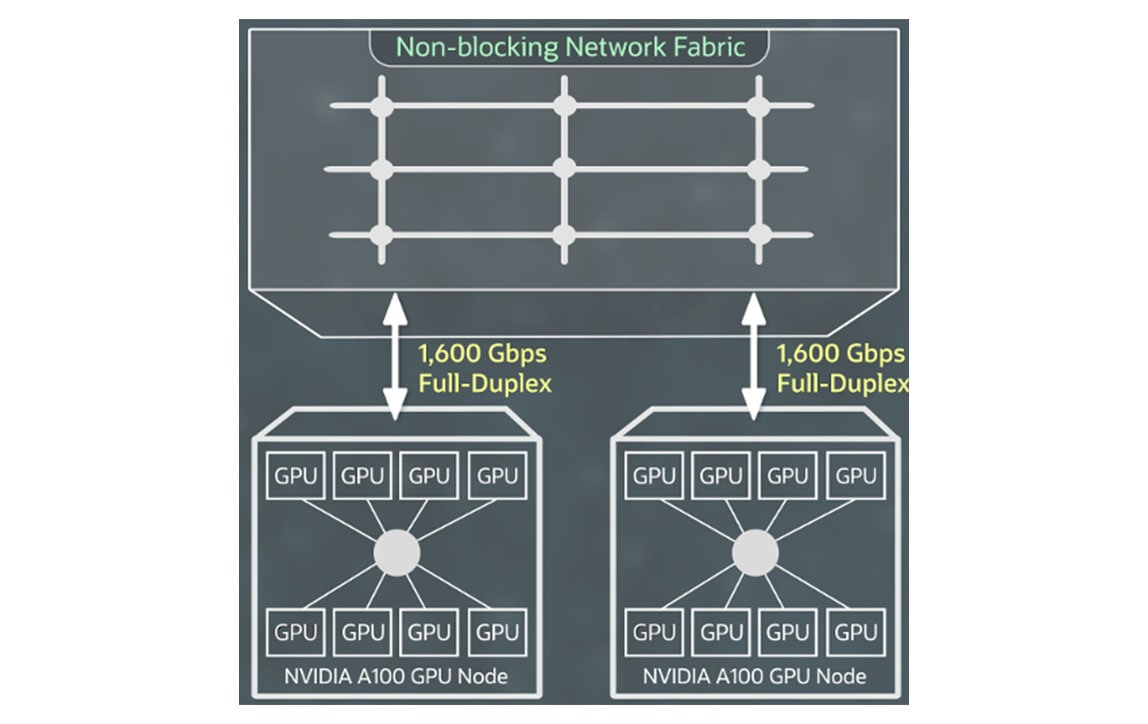
Networking for OCI Supercluster
High-speed RDMA cluster networking powered by NVIDIA ConnectX network interface cards with RDMA over Converged Ethernet version 2 lets you create large clusters of GPU instances with the same ultralow-latency networking and application scalability you expect on-premises.
You don’t pay extra for RDMA capability, block storage, or network bandwidth, and the first 10 TB of egress is free.
Enlarge+
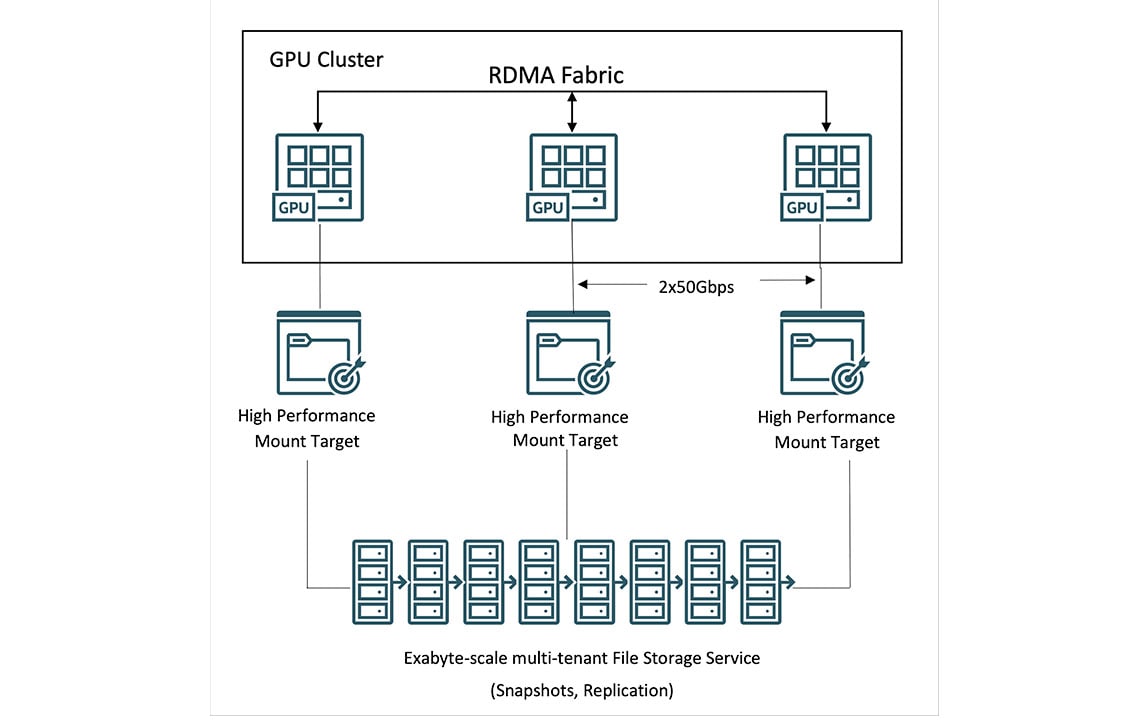
Storage for OCI Supercluster
Through OCI Supercluster, customers can access local, block, object, and file storage for petabyte-scale computing. Among major cloud providers, OCI offers the highest capacity of high performance local NVMe storage for more frequent checkpointing during training runs, resulting in faster recovery from failures.
For massive data sets, OCI offers high performance file storage with Lustre and mount targets. HPC file systems, including BeeGFS, GlusterFS, and WEKA, can be used for AI training at scale without compromising performance.

Zettascale OCI Superclusters
Watch OCI's top architects reveal how cluster networks power scalable generative AI. From a few GPUs to zettascale OCI Superclusters with more than 131,000 NVIDIA Blackwell GPUs, cluster networks deliver high speed, low latency, and a resilient network for your AI journey.
Seekr Selects Oracle Cloud Infrastructure to Deliver Trusted AI to Enterprise and Government Customers Globally
Abel Habtegeorgis, Oracle PRSeekr, an artificial intelligence company focused on delivering trusted AI, has entered a multi-year agreement with Oracle Cloud Infrastructure (OCI) to rapidly accelerate enterprise AI deployments, and execute a joint go-to-market strategy.
Read the complete postFeatured blogs
- MARCH 26, 2025 Announcing New AI Infrastructure Capabilities with NVIDIA Blackwell for Public, On-Premises, and Service Provider Clouds
- March 17, 2025 Advancing AI Innovation: NVIDIA AI Enterprise and NVIDIA NIM on OCI
- March 17, 2025 Oracle and NVIDIA Deliver Sovereign AI Anywhere
- March 11, 2025 Go from Zero to AI Hero—Deploy Your AI Workloads Quickly on OCI
Typical AI infrastructure use cases
- Deep learning training and inferencing
- Fraud detection augmented by AI
- AI-based medical image analysis
- Using AI to accelerate drug discovery
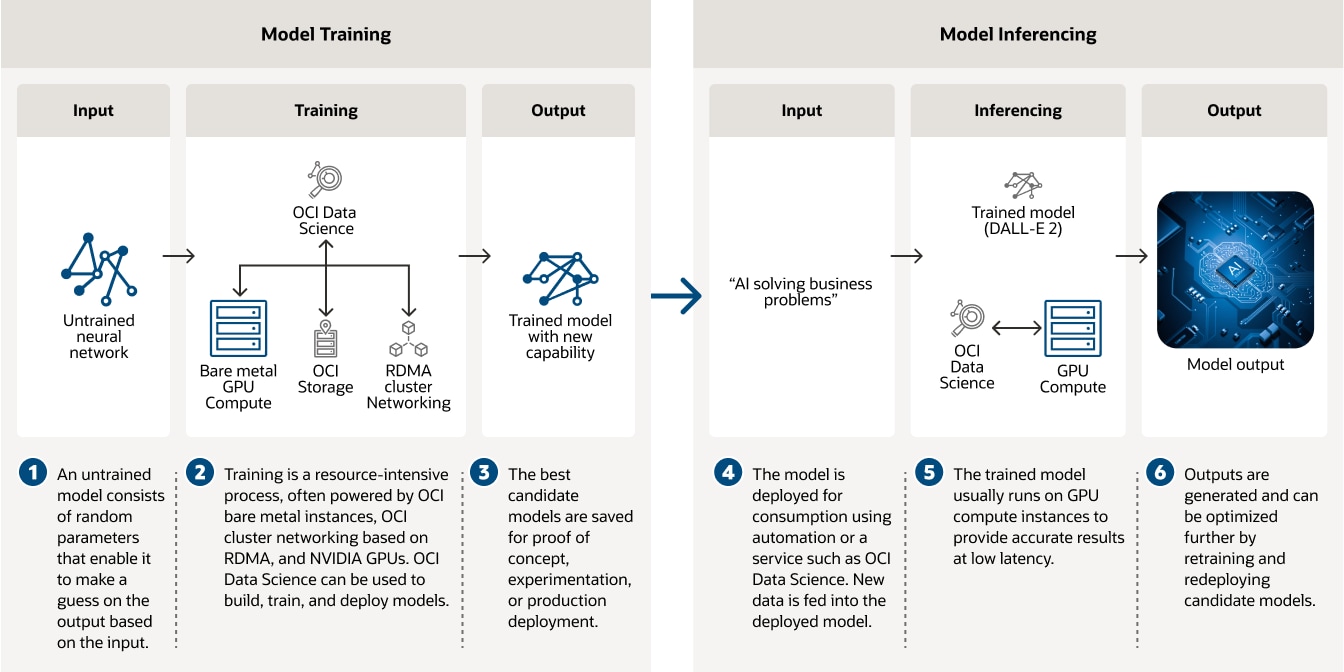
Train AI models on OCI bare metal instances powered by GPUs, RDMA cluster networking, and OCI Data Science.
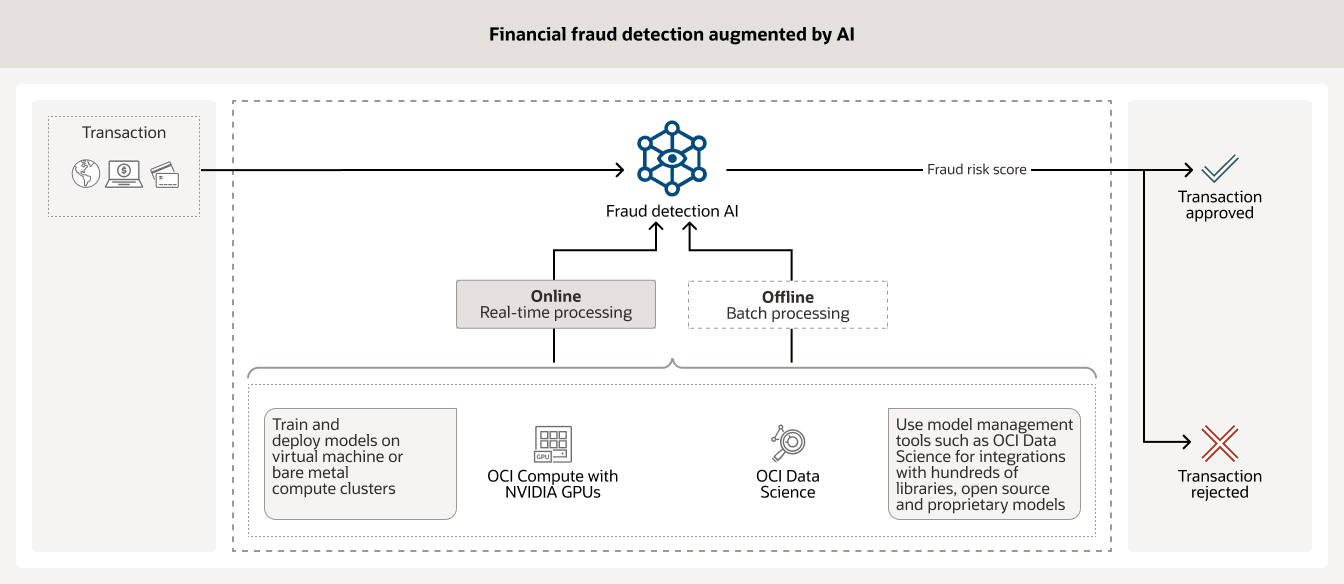
Protecting the billions of financial transactions that happen every day requires enhanced AI tools that can analyze large amounts of historical customer data. AI models running on OCI Compute powered by NVIDIA GPUs along with model management tools such as OCI Data Science and other open source models help financial institutions mitigate fraud.
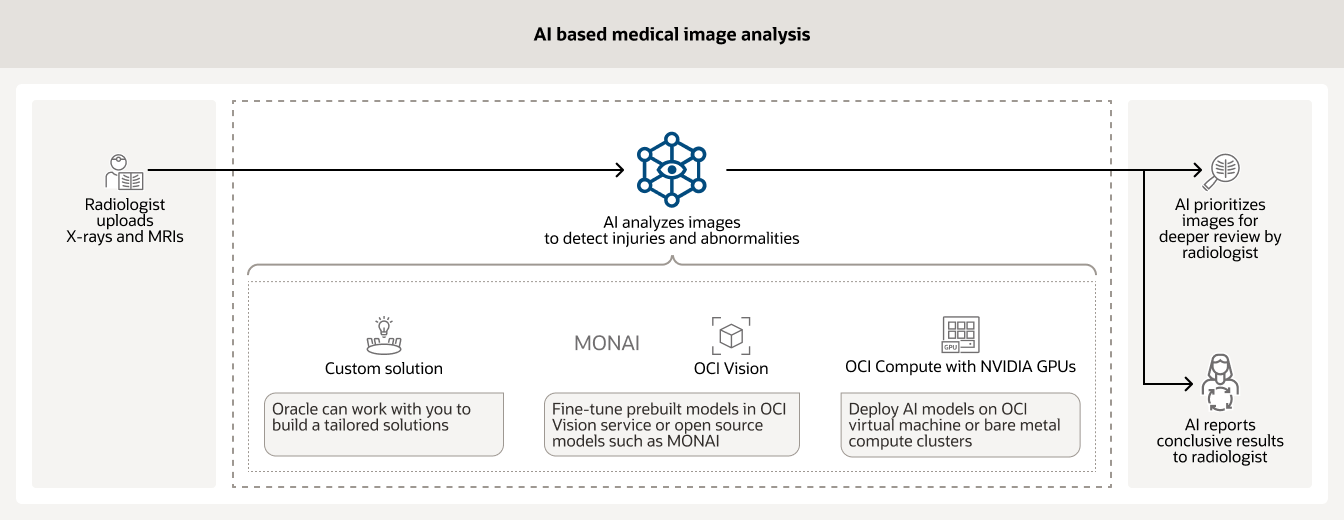
AI is often used to analyze various types of medical images (such as X-rays and MRIs) in a hospital. Trained models can help prioritize cases that need immediate review by a radiologist and report conclusive results on others.
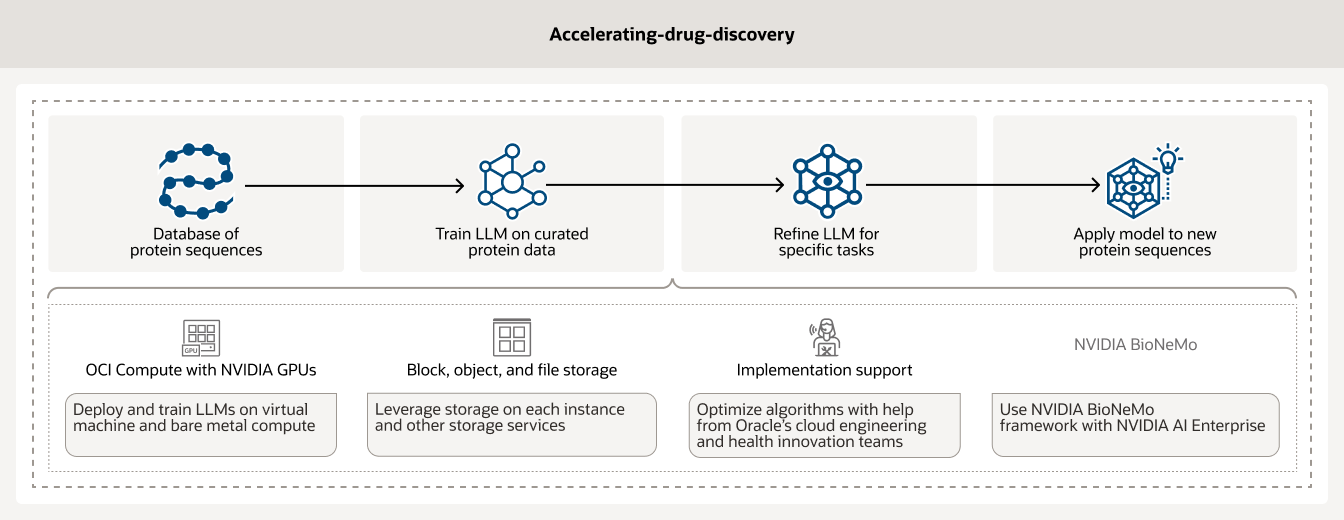
Drug discovery is a time consuming and expensive process that can take many years and cost millions of dollars. By leveraging AI infrastructure and analytics, researchers can accelerate drug discovery. Additionally, OCI Compute powered by NVIDIA GPUs along with AI workflow management tools such as BioNeMo enables customers to curate and preprocess their data.
AI infrastructure customer successes
















Get started with OCI AI infrastructure
Access AI subject matter experts
Get help with building your next AI solution or deploying your workload on OCI AI infrastructure.
-
They can answer questions such as
- How do I get started with Oracle Cloud?
- What kinds of AI workloads can I run on OCI?
- What types of AI services does OCI offer?
See how to apply AI today
Enter a new era of productivity with generative AI solutions for your business. Learn how Oracle helps customers leverage AI embedded across the full technology stack.
-
What can you achieve with Oracle AI?
- Fine-tune LLMs in OCI
- Automate invoice processing
- Build a chatbot with RAG
- Summarize web content with generative AI
- And so much more!
Additional resources
Learn more about RDMA cluster networking, GPU instances, bare metal servers, and more.
See how much you can save with OCI
Oracle Cloud pricing is simple, with consistent low pricing worldwide, supporting a wide range of use cases. To estimate your low rate, check out the cost estimator and configure the services to suit your needs.
Experience the difference
- 1/4 the outbound bandwidth costs
- 3X the compute price-performance
- Same low price in every region
- Low pricing without long term commitments