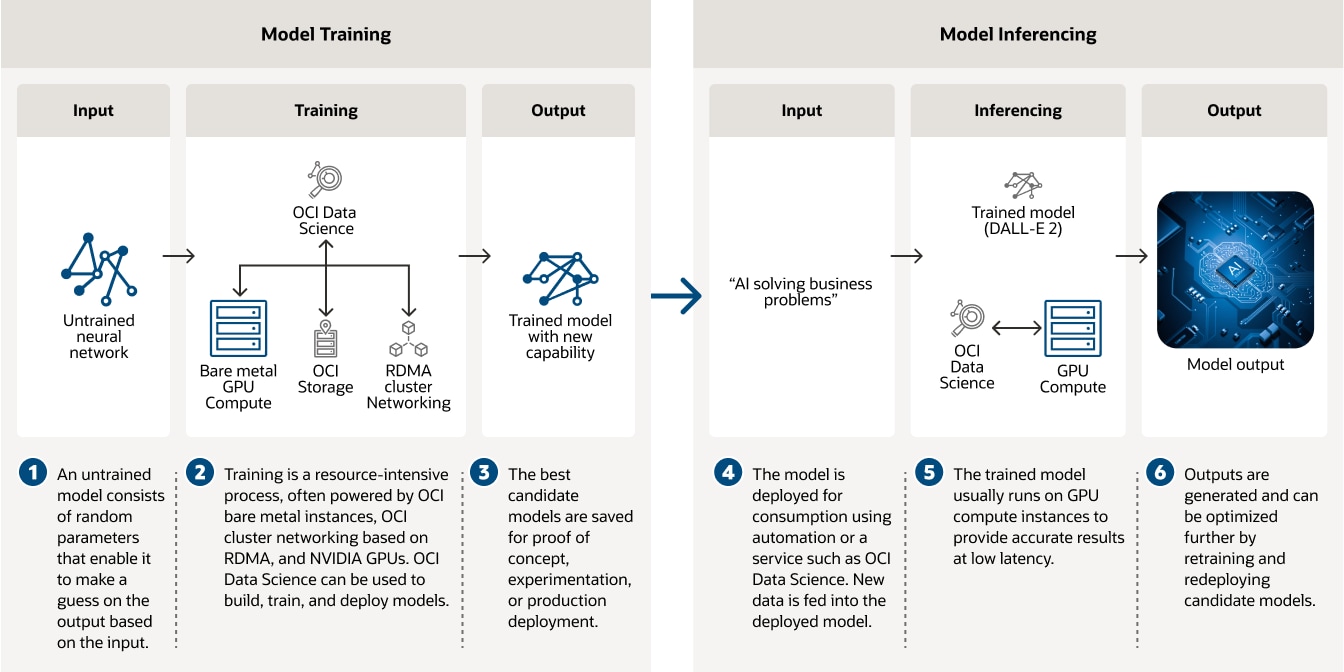
AI 基础设施
在分布式云环境的任意位置更快地运行高要求的 AI 工作负载,包括包括前沿模型训练和推理、agentic AI、科学计算和推荐系统。使用可支持多达 131072 个 GPU 的 Oracle Cloud Infrastructure ( OCI ) Supercluster,实现 zettascale 级性能。

参加 NVIDIA GTC 大会的 Oracle 活动
2026 年 3 月 16 日至 19 日
美国加利福尼亚州圣何塞市及线上
-
![]() 了解 2026 年将影响企业发展的 AI 趋势
了解 2026 年将影响企业发展的 AI 趋势
参加我们的系列网络研讨会,了解企业如何做好准备。
-
![]() 首要原则:Zettascale OCI Superclusters
首要原则:Zettascale OCI Superclusters
OCI 的优秀架构师揭示了集群网络如何为可扩展的 GenAI 提供强大支持,从几个 GPU 到具有 131072 个 NVIDIA Blackwell GPU 的 Zettascale OCI Supercluster。
![]() AI 实况演示:您值得探索的十大前沿创新
AI 实况演示:您值得探索的十大前沿创新
了解这十项突破性的 AI 驱动技术如何助力企业在执行维护工作、与客户互动、保护数据、提供医疗服务等方面实现变革。
-
![]() AMD Instinct 企业策略组 MI300X
AMD Instinct 企业策略组 MI300X
了解分析师对使用搭载 AMD GPU 的 OCI AI 基础设施的看法,以及此组合如何提高生产力、加快价值实现速度并降低能源成本。




Oracle 和 NVIDIA 共同创新
了解两家公司如何加速 AI 采用。
为何要选择 OCI AI 基础设施?

性能和价值
利用 OCI 独特的 GPU 裸金属实例和超快的 RDMA 集群网络加快 AI 训练速度,将延迟降低至 2.5 微秒。在 GPU VM 上获得更实惠的定价。

HPC 存储
利用具有高性能挂载目标 (HPMT) 和 Lustre 的 OCI File Storage,实现每秒 TB 级的吞吐量。可使用高达 61.44 TB 的 NVMe 存储,是业内超高的 GPU 实例。

主权 AI
Oracle 的分布式云技术支持您在任意位置部署 AI 基础设施,满足您独特的性能、安全性和 AI 主权要求。了解 Oracle 和 NVIDIA 如何在任何位置提供主权 AI 服务。
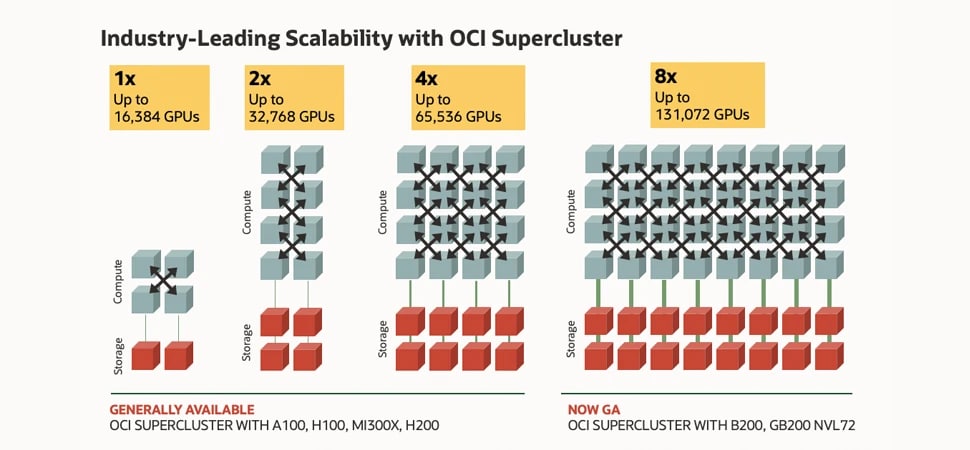 该图显示了代表计算和存储的盒子,这些盒子由线条连接在一起,形成了集群网络。左侧是最小的集群,仅有 16000 个 NVIDIA H100 GPU,有四个计算盒子和两个存储盒子。其右侧是一个搭载了 32000 个 NVIDIA A100 GPU 的集群,有 8 个计算盒子和 4 个存储盒子。然后是配置 64000 个 NVIDIA H200 GPU 的集群,有 16 个计算盒子和 8 个存储盒子。最后,右侧则是配备 128000 个 NVIDIA Blackwell 和 Grace Blackwell GPU 的集群,有 32 个计算盒子和 16 个存储盒子。此图表明了 OCI Supercluster 高达 8 倍的可扩展性,包括从左边最小的 16000 个 GPU 配置增加到右边最大的 128000 个 GPU 配置。
该图显示了代表计算和存储的盒子,这些盒子由线条连接在一起,形成了集群网络。左侧是最小的集群,仅有 16000 个 NVIDIA H100 GPU,有四个计算盒子和两个存储盒子。其右侧是一个搭载了 32000 个 NVIDIA A100 GPU 的集群,有 8 个计算盒子和 4 个存储盒子。然后是配置 64000 个 NVIDIA H200 GPU 的集群,有 16 个计算盒子和 8 个存储盒子。最后,右侧则是配备 128000 个 NVIDIA Blackwell 和 Grace Blackwell GPU 的集群,有 32 个计算盒子和 16 个存储盒子。此图表明了 OCI Supercluster 高达 8 倍的可扩展性,包括从左边最小的 16000 个 GPU 配置增加到右边最大的 128000 个 GPU 配置。
搭载了 NVIDIA Blackwell 和 Hopper GPU 的 OCI Supercluster
GPU 多达 131072 个,8 倍更高的可扩展性
网络结构的创新支持 OCI Supercluster 扩展至 131072 个 NVIDIA B200 GPU,以及超过 100000 个 NVIDIA Grace Blackwell Superchips 和 65536 个 NVIDIA H200 GPU。
OCI AI 基础设施可满足您的所有需求
无论是执行推断、微调还是训练大型横向扩展的生成式 AI 模型,OCI 都能提供出色的裸金属和虚拟机 GPU 集群,通过超高带宽网络和高性能存储满足您的 AI 需求。
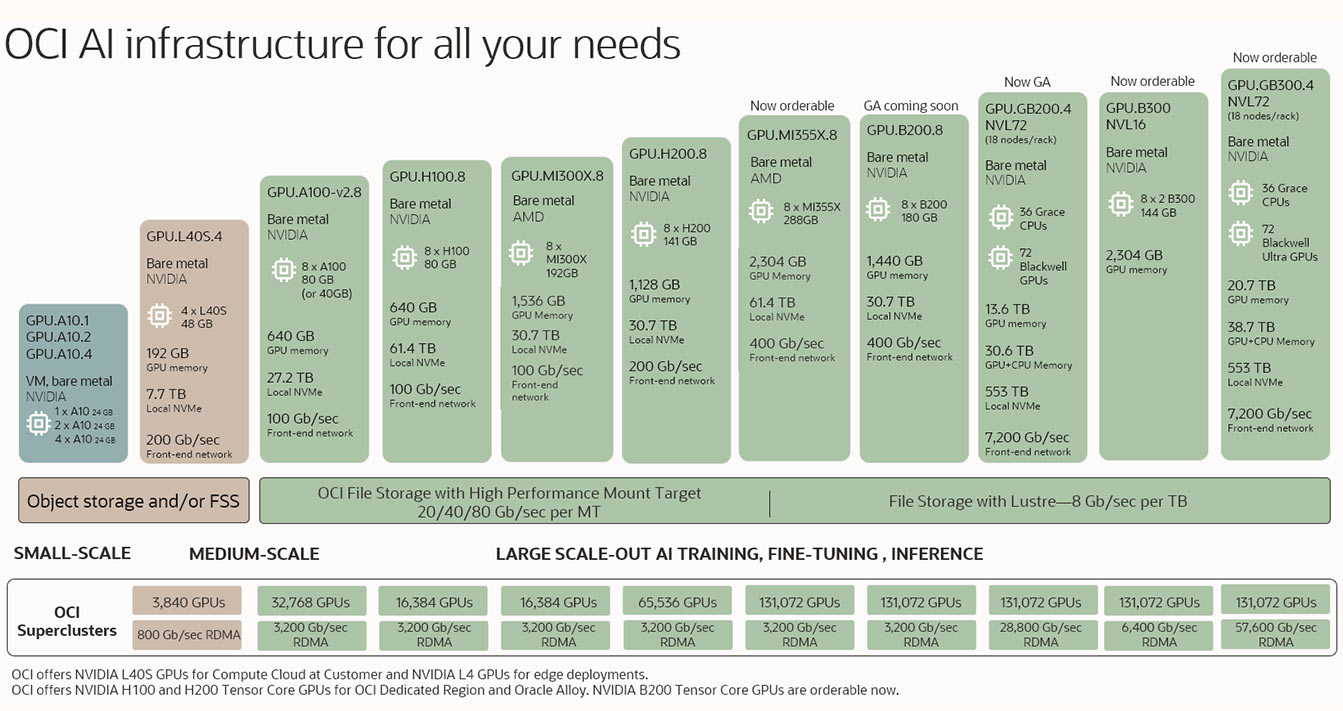 该图显示了 AI 基础设施的多个产品,从左侧的最小配置开始,然后逐步增加到中等规模和大规模配置。最小的配置仅具有 1 个 GPU,常用于在虚拟机中;而最大配置则配备了高达 100000 多个 GPU,可用于 RDMA 集群。
该图显示了 AI 基础设施的多个产品,从左侧的最小配置开始,然后逐步增加到中等规模和大规模配置。最小的配置仅具有 1 个 GPU,常用于在虚拟机中;而最大配置则配备了高达 100000 多个 GPU,可用于 RDMA 集群。 6 月 11 日,了解如何使用 OCI 和 NVIDIA RTX PRO 为生产 AI 提供支持。
了解面向大规模 AI 训练的 OCI Supercluster
使用 NVIDIA Blackwell 和 Hopper 实现大规模横向扩展集群
超级计算
•无任何虚拟机管理程序开销的裸金属实例
•由 NVIDIA Blackwell (GB200 NVL72,HGX B200)、
Hopper (H200,H100) 和上一代 GPU 加速
•可选择使用 AMD MI300X GPU
•用于内置硬件加速的数据处理单元 (Data Processing Unit,DPU)
大容量和高吞吐量存储
•本地存储:高达 61.44 TB 的 NVMe SSD 容量
• 文件存储:由 Oracle 托管的文件存储,具备 Lustre 服务和 高性能挂载目标
• 块存储:均衡、高性能和超高性能卷,并提供性能 SLA
• 对象存储:不同的存储类层、存储桶复制和高容量限制
超高速网络
•定制设计的基于融合以太网的 RDMA 协议 (RoCE v2)
• 2.5 至 9.1 微秒的集群网络延迟
•至多 3,200 Gb/秒的集群网络带宽
•最多 400 Gb/秒的前端网络带宽
OCI Supercluster 计算服务
基于 NVIDIA GB200 NVL72、NVIDIA B200、NVIDIA H200、AMD MI300X、NVIDIA L40S、NVIDIA H100 和 NVIDIA A100 GPU 的 OCI 裸金属实例支持您为深度学习、会话式 AI 和生成式 AI 等使用场景运行大型 AI 模型。
借助 OCI Supercluster,您可以扩展至超过 100000 个 GB200 Superchips、131072 个 B200 GPU、65536 个 H200 GPU、32768 个 A100 GPU、16384 个 H100 GPU、16384 个 MI300X GPU 以及每个集群 3840 个 L40S GPU。

放大+
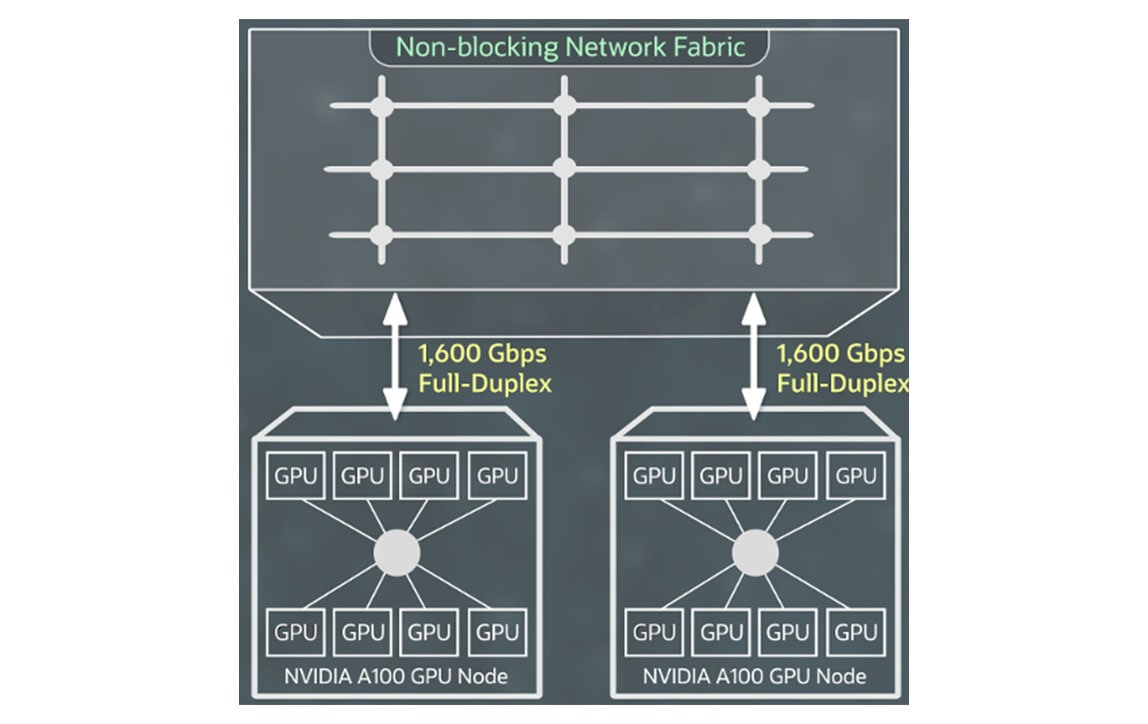
OCI Supercluster 网络服务
基于 NVIDIA ConnectX 网络接口卡和基于融合以太网的 RDMA 第二版的高速 RDMA 集群网络支持您创建大型 GPU 实例集群,获得与本地部署环境下相同的超低网络延迟和应用可扩展性优势。
您无需为 RDMA 容量、块存储或网络带宽额外付费,同时前 10 TB 数据出站也完全免费。
放大+
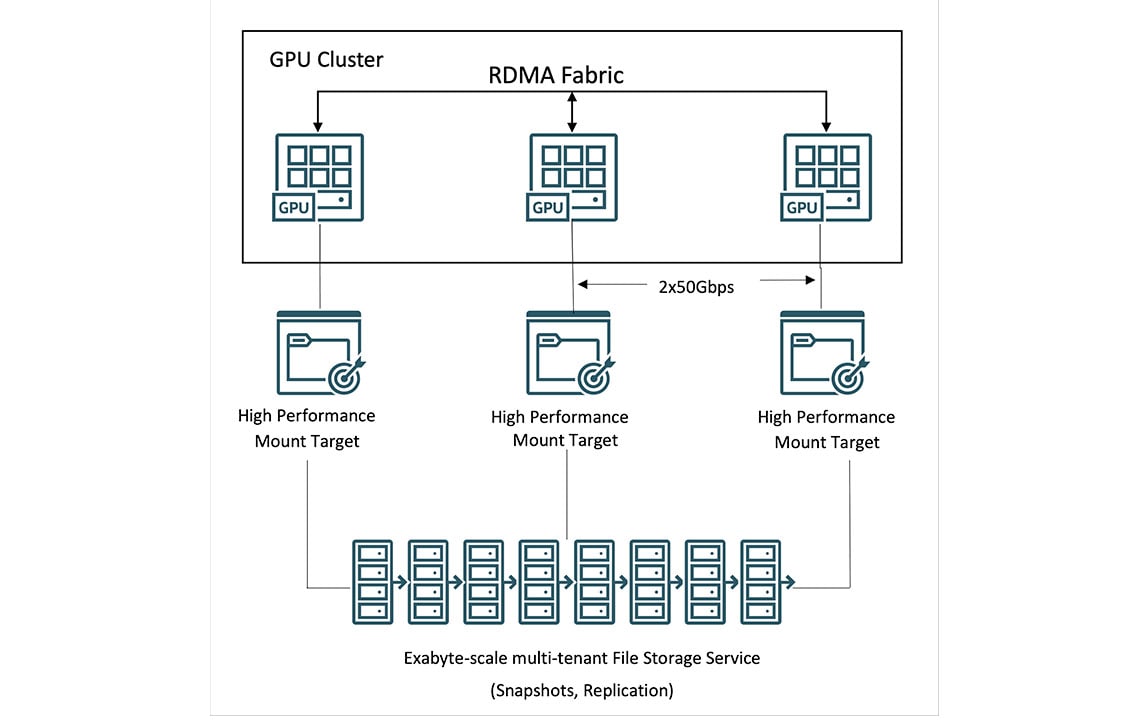
OCI Supercluster 存储服务
OCI Supercluster 支持您访问本地存储、块存储、对象存储和文件存储来执行 PB 级计算。相比其他主流云技术提供商,OCI 提供更高的高性能本地 NVMe 存储容量,可满足更高频次的训练中检查点要求,进而加快故障恢复速度。
对于海量数据集,OCI 通过 Lustre 和挂载目标提供高性能文件存储。同时,您还可以使用 HPC 文件系统(包括 BeeGFS、GlusterFS 和 WEKA)进行规模化 AI 训练而无需担心性能下降。

Zettascale OCI Superclusters
观看 OCI 的优秀架构师演示,了解集群网络如何为可扩展的生成式 AI 提供强大支持。从几个 GPU 到拥有超过 131000 个 NVIDIA Blackwell GPU 的 Zettascale OCI Superclusters,集群网络可为您的 AI 之旅提供高速、低延迟和弹性网络。
Seekr 选择 Oracle Cloud Infrastructure 为全球企业和政府客户提供值得信赖的 AI 技术
甲骨文公司公关专员 Abel Habtegeorgis作为一家专注于提供可信 AI 的人工智能公司,Seekr 已与 Oracle Cloud Infrastructure (OCI) 签订多年期协议,以快速加速企业 AI 部署并执行联合市场推广战略。
阅读全文精选博客
- 2025 年 3 月 26 日 NVIDIA Blackwell 推出面向公有云、本地部署和服务提供商云技术平台的新 AI 基础设施功能
- 2025 年 3 月 17 日 推进 AI 创新:基于 OCI 的 NVIDIA AI Enterprise 和 NVIDIA NIM
- 2025 年 3 月 17 日 Oracle 和 NVIDIA 在任何位置提供主权 AI 服务
- 2025 年 3 月 11 日 从新手到 AI 达人 — 在 OCI 上快速部署 AI 工作负载
AI 基础设施的典型使用场景
使用基于 GPU 的 OCI 裸金属实例以及 RDMA 集群网络和 OCI Data Science 训练 AI 模型。
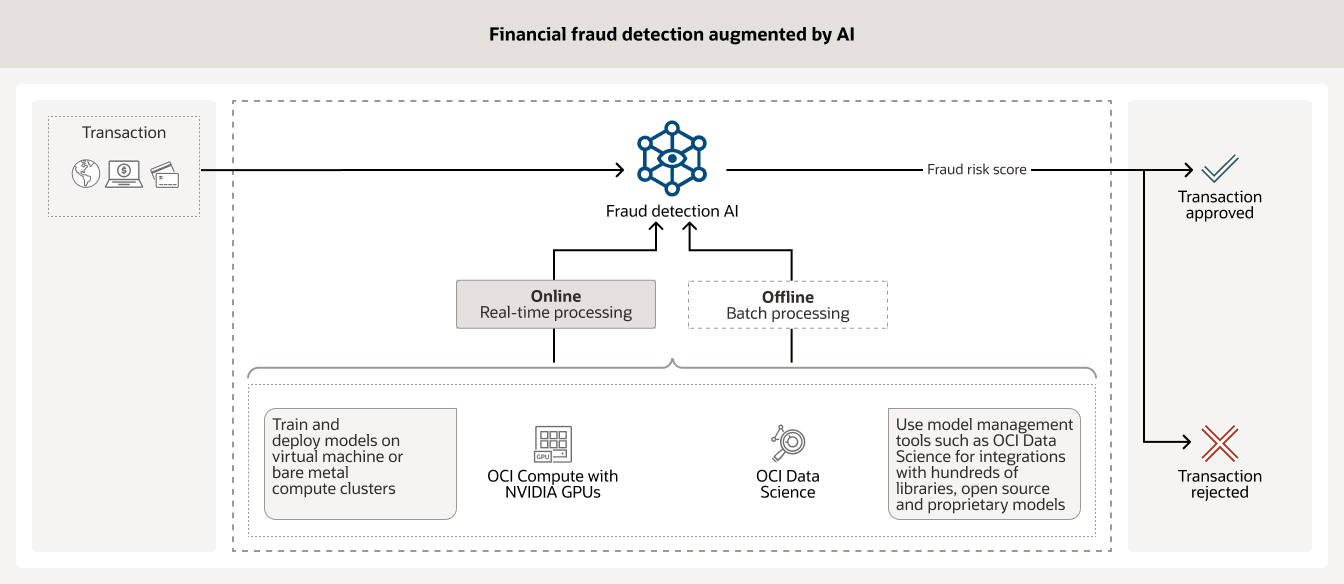
使用增强型 AI 工具分析海量历史客户数据对于确保每天数十亿笔金融交易安全至关重要。借助基于 NVIDIA GPU 的 OCI Compute 以及 OCI Data Science 等模型管理工具和其它开源模型,金融机构可以显著降低欺诈风险。
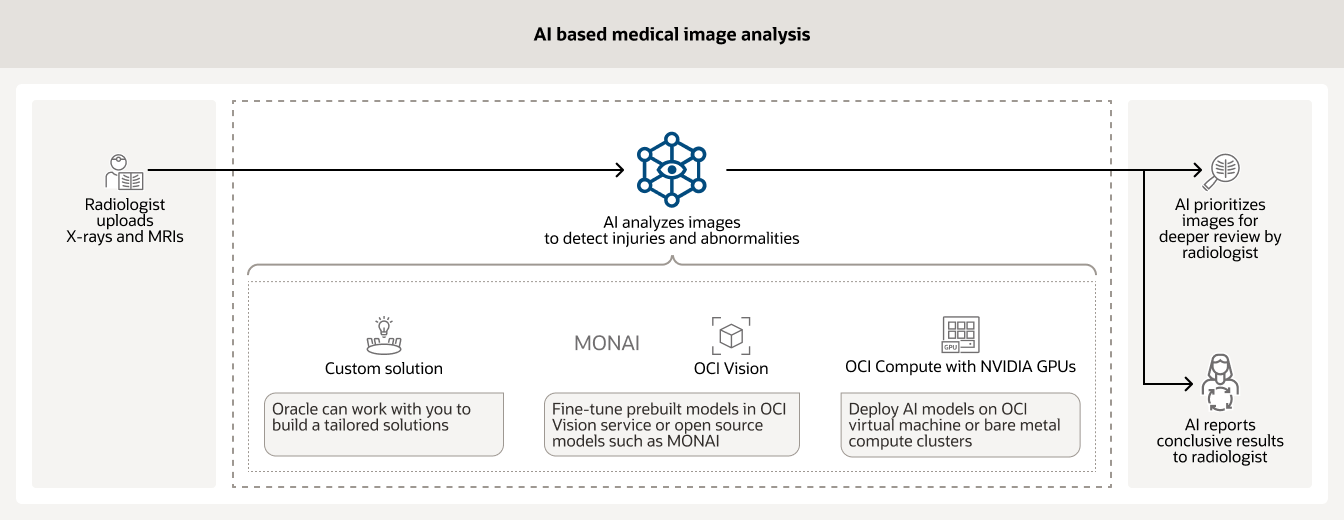
AI 常常被医院用于分析各种类型的医疗图像,例如 X 射线和 MRI 图像。经过良好训练的 AI 模型有助于高效识别需要放射科医生即刻审阅的高优先级图像并向其他人报告最终结果。
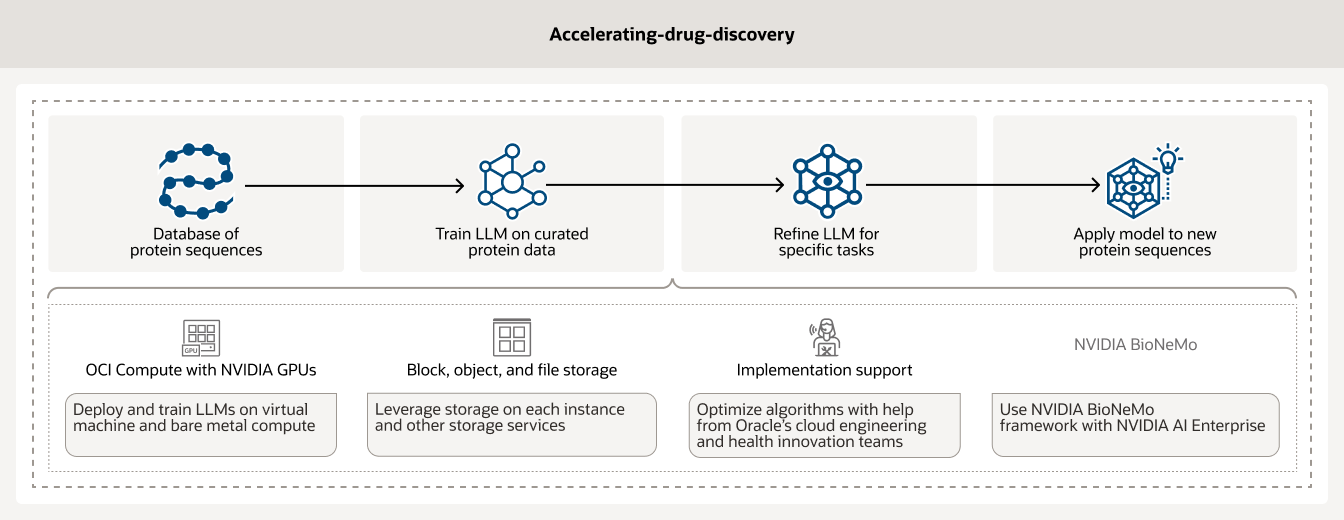
药物发现过程既耗时(可能长达数年)又耗费资金(可能耗资数百万美元)。AI 基础设施和分析可以帮助研究人员加快药物发现速度。此外,基于 NVIDIA GPU 的 OCI Compute 以及 AI 工作流管理工具(例如 BioNemo)还能帮助客户管理和预处理自己的数据。
AI 基础设施客户成功案例















赶快行动
-
专家能为您解答以下问题:
- 如何开始使用 Oracle Cloud?
- 可以在 OCI 上运行哪些 AI 工作负载?
- OCI 提供哪些类型的 AI 服务?
-
Oracle AI 可助力企业实现哪些目标?
- 在 OCI 中微调 LLM
- 实现发票处理自动化
- 使用 RAG 构建聊天机器人
- 使用生成式 AI 汇总网络内容
- 等等!
更多资源
详细了解 RDMA 集群网络、GPU 实例和裸金属服务器等等。
体验不同之处
- 1/4 出站带宽成本
- 3 倍计算性价比
- 全球统一超低价格
- 无长期承诺的低定价
注:为免疑义,本网页所用以下术语专指以下含义:
- 除Oracle隐私政策外,本网站中提及的“Oracle”专指Oracle境外公司而非甲骨文中国。
- 相关Cloud或云术语均指代Oracle境外公司提供的云技术或其解决方案。