专为企业场景构建的图像分析
检测对象(包括人脸和面部特征),并对图像进行分类
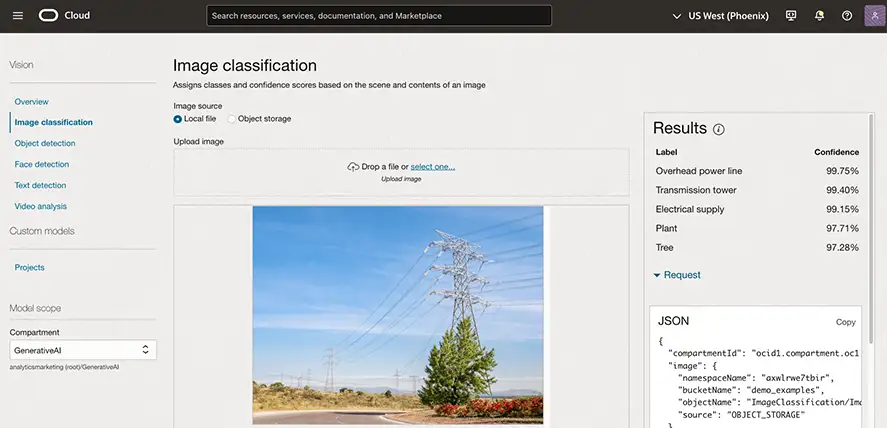
OCI Vision 可将图像分类为数千种类别,简化常见数字资产管理工作;可识别需要关注的项目,例如电源线附近的植被生长情况。另外,开发人员还可以利用它来识别和定位图像中的对象,自动对常见项目(例如包裹和车辆)进行计数。此外,开发人员可以使用人脸识别功能,识别图像中的人脸和面部特征。
已存储视频分析
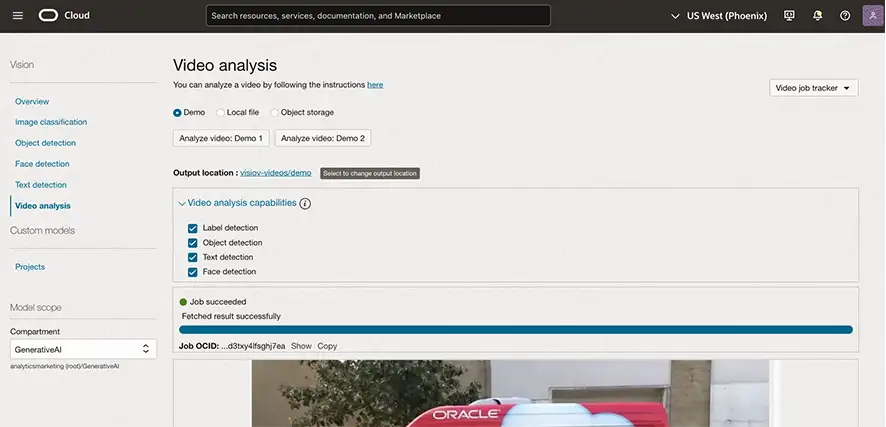
使用预训练或定制模型,逐帧分析视频。获取物体、标签、文本和人脸的信息以及检测时间。您可以使用时间线,直接查找标签或对象,轻松跳转到视频中特定标签或对象出现的确切时间戳。
流视频分析
OCI Vision 流视频分析功能使用 AI 驱动的分析从实时视频流提供实时洞察。它完全被托管并采用 GPU 加速,可以检测 RTSP 和 WebRTC 源中的物体、人脸、文本和标签,并且可以跟踪实时流中的人脸。它专为低延迟和可扩展性而设计,支持关键任务使用场景,包括安全监视、零售分析、制造和活动场馆运营。
针对业务领域的定制模型
轻松训练和管理模型
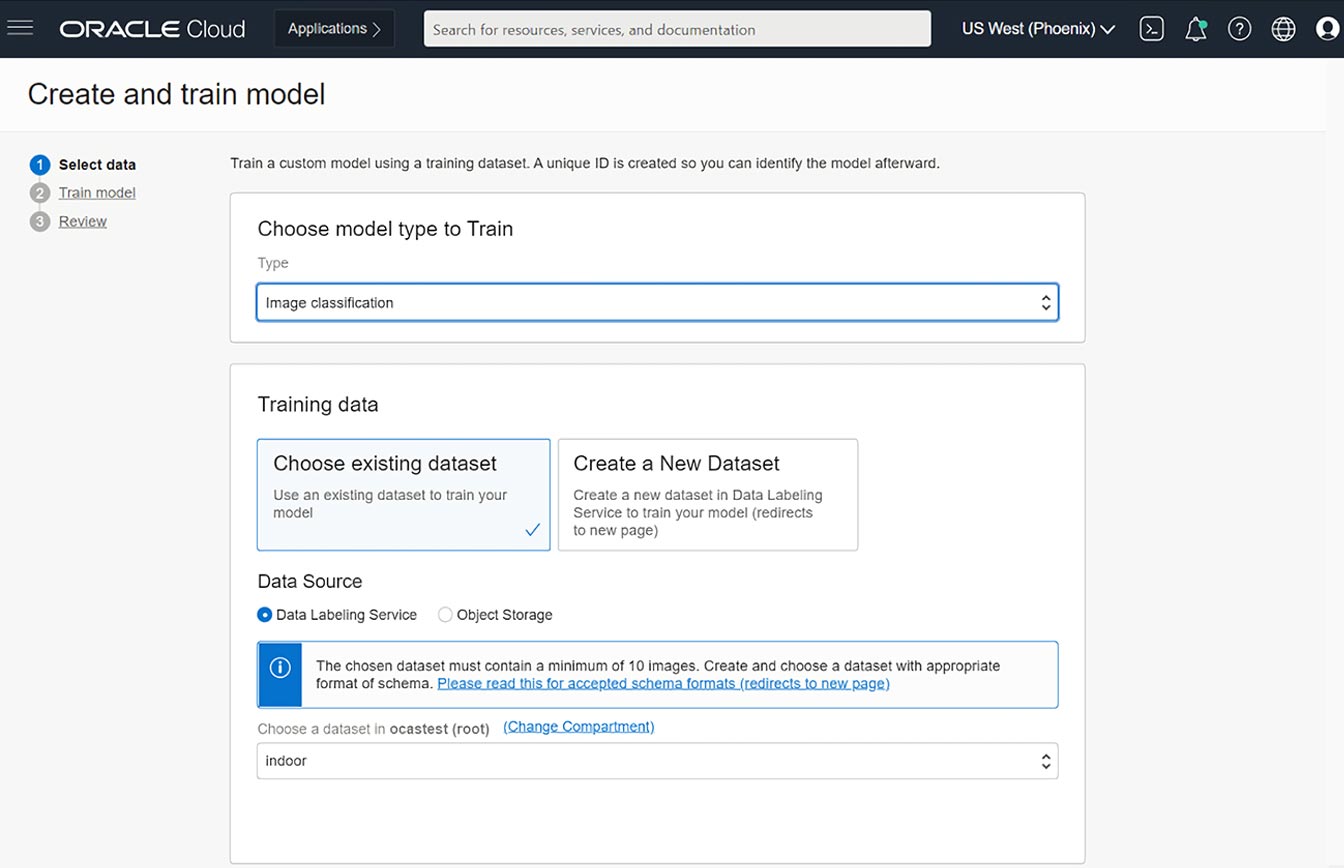
除了预训练模型外,开发人员还可以创建自定义模型,但无需管理自定义模型基础设施。此外,开发人员还可以通过 OCI Vision 的用户界面来上传数据、训练图像分类或对象检测模型、审查自定义模型指标以及将模型构建到项目中。利用 OCI Vision,所有人都可以轻松构建高度准确、经自定义训练的计算机视觉识别模型。
简单而高效的架构
轻松集成和部署
OCI Vision 功能完备,可通过 REST API、2 种 SDK 或 OCI 命令行来调用。开发人员即使不具备数据科学或机器学习专业知识,也可以轻松部署可扩展的视觉识别服务。
注:为免疑义,本网页所用以下术语专指以下含义:
- 除Oracle隐私政策外,本网站中提及的“Oracle”专指Oracle境外公司而非甲骨文中国。
- 相关Cloud或云术语均指代Oracle境外公司提供的云技术或其解决方案。