Oracle Berkeley DB Replication for Highly Available Data Management
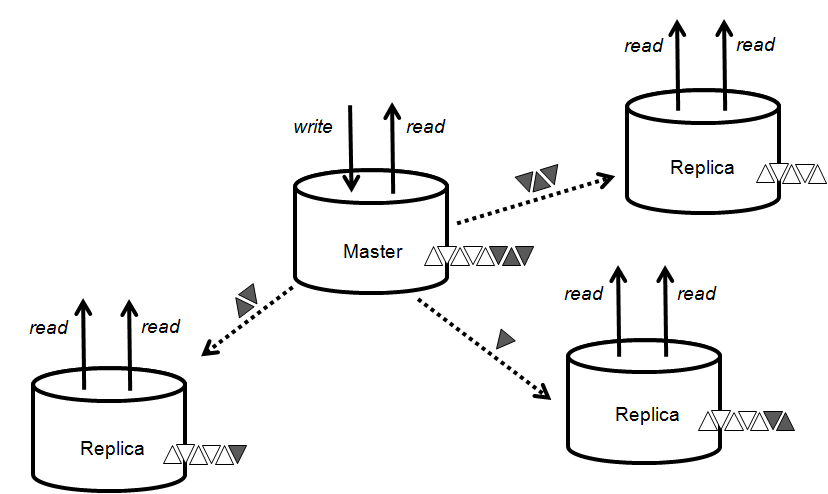
Berkeley DB provides replication for high availability and horizontal read scalability in distributed systems or within redundant hardware systems. Berkeley DB HA is a single master, multi-replica system with automatic failover. Replicas service reads, the master can service read and write operations. Replicas receive updates as transaction log records sent from the master or from other replicas and apply them locally. They inform the master of ther state and the master uses that information to manage consistency across the replica group. Each node in a replicated system maintains a complete copy of the data and logs. This architecture provides excellent read scalability, near instantaneous failover, and can deliver near 100% uptime. Applications using Berkeley DB HA scale beyond the processing constraints of a single system and gracefully manage failures to provide maximum availability.
Berkeley DB HA infrastructure can support any communications systems, not just TCP/IP, which can dramatically improve proformance in embedded hardware systems with internal high-speed custom interconnects between redundant systems (blades for instance). However, Berkeley DB does provides built-in support for managing replication groups over a TCP/IP network.
Only the master node can modify the database. Applications perform create, update and delete requests at the master then the master distributes those changes automatically to as many replicas as the application requires for the requested degree of consistency. A transaction, immediately consistent, require a quorum of nodes, or any other criteria your application requires. Reads can be processed by any node at any time, master or replica. Replicas can join, leave, even re-join the group at any time allowing you to size the solution to your needs as they change. When a master fails, an election is called to identify and promote a new master. This solution:
- Provides rapid failover in situations where downtime is unacceptable
- Provides read scalability by providing multiple read-only replicas
- Enables more efficient commit processing, allowing applications to provide durability by committing to the (fast) network, rather than to a (slow) disk
- Provides more flexibility to the application by not enforcing a single consistency model for all operations
Where Berkeley DB HA is applicable:
- Small-scale LAN-based replication: A data-center based service that provides data for a local population, such as a corporate site. This service is implemented by a few servers which reside in the same data center and communicate over a high-speed LAN.
- Wide-area data store: A world-wide service provider who stores information that is accessible anywhere in the world. This service is implemented by a collection of servers, which reside in different data centers scattered around the globe and communicate via highspeed data-center to data-center connections.
- Master/Slave: A simple installation to provide failover between a master and slave machine. Given the wide range of environments across which HA replicates data, no single set of data management and replication policies is appropriate. Berkeley DB HA lets the application control the degree of data consistency between the master and replicas, transactional durability, and a wide range of other design choices that dictate the performance, robustness, and availability of the data.
The choice of a master is made using a distributed two-phase voting protocol, which ensures that a unique master is always elected. Elections require that at least a simple majority of the electable nodes participate in the process. The participating Electable node which has the most up-to-date state of the environment is elected the master. An Electable node can be in one of the following states:
- Master: the node was chosen by a simple majority of electable nodes. The node can process both read and write transactions while in this state.
- Replica: the node is in communication with a master via a replication stream that is used to keep track of changes being made at the master. The replication stream is described in greater detail in subsequent sections. The replica only supports read transactions.
The master sends changes down to the replica asynchronously, as fast as the replica can process them. Changes are streamed to the replica eagerly, that is, even while the transaction is in progress and before the application attempts to commit the transaction on the master. If the transaction is subsequently aborted on the master, the replica will abort the transaction as well. An application thread may wait for one or more replicas to catch up to a specific transaction if the durability requirements of the transaction require it. The replica responds with explicit acknowledgment responses for such transactions, but this does not inhibit forward progress on the master, as it is free to proceed with other transactional work.
The write operations to the replication stream by the master and the read (and replay) operations on the replica are asynchronous with respect to each other. The master can write to the replication stream as soon as the application creates a new log entry. The replica reads from the replication stream and replays changes as soon as it reads them, additionally responding with acknowledgments to the replay of a commit operation if requested by the master.
Articles
- White paper: Managing Consistency with Berkeley DB High Availability (PDF)
- White paper: Unleash High Availability Applications with Berkeley DB (PDF)
- White paper: Berkeley DB Java Edition High Availability (HA) (PDF)
- White paper: Oracle Berkeley DB Java Edition High Availability - Large Configuration and Scalability Testing (PDF)