Avoiding Service Call Failures in Oracle Service Bus and Oracle SOA Suite
by Rolando Carrasco and Leonardo Gonzalez
April 2017
Introduction
This article is targeted at Oracle Service Bus (OSB) developers and architects who want to learn/validate their strategies for avoiding service call failures within their integration pipelines.
Having dual roles as architects and developers the authors have seen many projects in which the developer or the architect didn’t design or implement a good exception/failure management strategy.
This article will streamline a series of strategies to avoid such failures.
Some of the ideas in this article are were originally presented by our colleague David Hernández in a December 2015 session at a Microservices and API Management Symposium in Lima, Peru. That session focused on various strategies for mitigating failures in the development of Services:
- Circuit breakers
- Bulkheads
- Timeouts
- Redundancy
In this article we will apply these strategies to Oracle Service Bus.
These strategies can be implemented using OSB and Oracle SOA Suite (composites). Some features of the current latest release (12.2.1) will help you to facilitate the implementation; other strategies are very basic configurations in OSB that many people skip and therefore struggle to maintain stability in their Service Bus implementation.
Let’s always keep in mind that the Service Bus is a core element in any infrastructure that implements it. CIOs and managers sometimes do not give that specific weight to this platform and wonder why, if the OSB/SOA Suite is not available, the infrastructure crashes. Or sometimes they wonder why the OSB struggles when a platform is not available or is under heavy load. The answer is simple: OSB is the integration pipeline within your infrastructure and architecture. Imagine if a water pipeline in your house breaks: you don’t see it, but a real mess is happening behind your walls or beneath the floor. The same idea applies here.
Let's also bear in mind that 60% of the development of a service is related to exception management and the ability to avoid failures. If we don’t take care of this, or expect that someone else will take care of it, we are wrong. You need to be able to identify the following scenarios:
- What if the service that I am calling is down?
- What if the service that I am calling is not responding in the amount of time that I expect it to respond?
- What if the service that I am calling is not prepared to receive the amount of calls that I will send to it?
- What If my JMS queue fails?
- What if the Database call is taking longer than expected?
- What if I take care of the error—what happens next?
- What if I manage the error and keep the message in a queue for a later reprocessing? Is the endpoint prepared for it?
- What if I send all those transactions for a manual recovery?
- What if I don’t manage anything?
- What if a platform fails or is not available? Am I ready to avoid a domino effect?
- What if I need to break a circuit within my pipelines?
- What if my file systems run out of space?
And these are just some of the “what ifs” you’ll face.
As you can see, failures can happen anywhere and at any time, and we have to prepare for them.
In this article we will elaborate on different scenarios and show how OSB is able to handle them with different strategies. We'll also introduce a concept that we have created to explain the importance of delimiting responsibilities in any SOA-Service Bus architecture/infrastructure: Service Bus Complicity.
You are probably wondering: What’s that?
The answer is simple: If we let our SOA/OSB implementation be part of a problem that causes incidents, downtimes, interruption of continuous availability and SOA/OSB server crashes, then we are complicit in other people’s problems. And not only that—it is highly probable that we are going to be pointed to as the root cause of the problem, or the stopper of Business Continuous Availability. Isn’t that serious?
We think it’s really serious. It can cost us our jobs and our mental health.
So let’s take a look at the different strategies for avoiding failures in our SOA/OSB implementation, so we can avoid being that accomplice we just mentioned.
Circuit Breaker
This concept is reflected in a feature in the 12.2.1 release of Oracle SOA Suite, and is available as an option (Continuous Availability) that can be licensed on top of your current Oracle SOA Suite licenses.
A circuit breaker is a mechanism used to break a specific situation where an upstream service is not responding as expected. A common use case is when a Web Service (for example) that is used to communicate with another platform (let’s say a CRM application) is down, or is under a heavy load and is unable to process the number of requests that it’s receiving from Integration pipelines (Service Bus pipelines, Composites).
The break is applicable to the downstream service that is generating the load to the upstream. In that case, the circuit breaker will avoid the overload to the upstream. The downstream will be suspended, returning an error to its caller. Now the caller has the responsibility to manage the failure and report it.
In addition to the obvious problems this common scenario causes, it also creates constant headaches for the operations team, and therefore for the CIO and the business itself.
Often, the Service Bus and SOA infrastructure generate requests to different systems/platforms. When those are not available or are having problems, the OSB or SOA servers are candidates for the following scenarios:
- Many threads take some time to be completed. They are still running, because they are waiting for a response from the given Service/Platform.
- Our pipelines start to fill while time passes. As more time passes, more requests arrive, and more threads are at risk of being stuck.
- Our WebLogic servers start to panic (by which we mean: WARNING state).
- The consumers of those services are receiving a lot of errors or are not receiving any response.
- If it is an end-user system, customers are already waiting for "the system to come back."
- WebLogic servers pass from WARNING to FAILED.
- All the operations teams are in panic mode now!
Let’s take a look at how easy is to implement the Circuit Breaker functionality on top of Oracle SOA Suite 12.2.1.
In Enterprise Manager, go to the SOA-INFRA page:
Figure 1
Click on the SOA Infrastructure sub-menu and then click on the following options:

Figure 2
In the Resiliency Configuration section there are some very simple configurations we need to do to activate the Circuit Breaker:
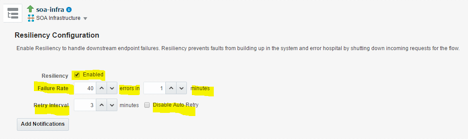
Figure 3
- The Resiliency checkbox. Activate this box to enable the Circuit Breaker feature. Note: this feature needs be licensed (ask your Sales Representative for the pricing model).
- Failure Rate. The number of errors a particular upstream service will raise. If the number of errors is above this number, the Circuit Breaker will do its magic.
- Errors in minutes. This parameter determines the amount of time in which the errors specified by the Failure Rate need to take place. In the example above, if there are more than 40 errors on a specific service within 1 minute, the Circuit Breaker will start.
- Retry Internal. The number of minutes that must pass before checking if the upstream service is responding. If it is responding, the flow of requests will continue.
- Disable Auto Retry. If you active this box, you will have to manually activate the services after the problem is resolved.
As you can see, this feature is very powerful but is also very easy to configure.
The following example explains the functionality of the Circuit Breaker:
Let’s imagine that we have a Web Service provided by CRM application, and in some circumstances it takes more than 30 seconds to respond. This Web Service is consumed as part of a set of Services and Composites within Oracle SOA Suite 12.2.1:

Figure 4
In a heavy load scenario, it can take more than those 30 seconds or there might even be no response. The development team has not configured any timeouts or Fault Policies that could avoid a catastrophe.
We have a downstream service that makes constant calls to this service. In the scenario where the first service takes more than 30 seconds to respond or, even worse, never responds, this second service struggles a lot, creating a domino effect for the rest of the consumers that depend on it. Errors start happening, WebLogic goes to WARNING and then, because of the huge number of stuck threads, WebLogic simply dies.
Now let’s see what would happen if we activated the Circuit Breaker feature:
- While executing our downstream service (the second service we described in the previous paragraph), the first service starts responding very slowly or even does not respond, and we get this answer:
- In the log files we see:
- On the SOA-INFRA home page, we see a list of the suspended services (services with more than 40 errors during a minute):
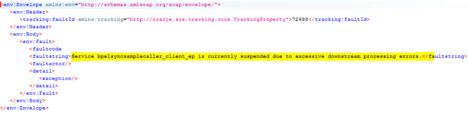
Figure 5
This is already throwing a fault and explaining the fault's origin. So we are already controlling the situation. The caller is not hanging at all; it is receiving a response.

Figure 6

Figure 7
Let’s say we have a problematic service (let’s call it service A) that can be a headache under a heavy load. Sometimes it responds in more than 30 seconds, or sometimes it doesn’t respond at all. We also have a second service (let’s call it B) that is constantly calling service A. Without proper fault management, this situation represents a time bomb. To defuse it, use the Circuit Breaker. Service B is suspended, so its callers aren’t affected by the non-response of service A.
As you'll see in the following sections, if we mix the strategies, our SOA services will be protected and we can avoid being complicit in the crises of others.
Bulkheads
The term "bulkhead" is associated generally with ships. A bulkhead's purpose is to avoid a complete failure. If one part of a ship floods, bulkheads will limit the flooding to that compartment, and the ship will not sink.
How does that idea apply to OSB implementations? A common scenario in OSB implementations is: “When a backend system goes down, SOA infrastructure is not working! Why?” Sound familiar?
In Oracle SOA Suite there are some mechanisms to protect the SOA Infrastructure. Thus, if any part of your integration application goes down, your ship will not sink.
These mechanisms are:
- Work managers
- Timeouts
- Throttling
Bulkheads can be implemented with the other three strategies described in this article. But let’s try to elaborate on the bulkhead idea without being redundant with the other strategies.
Bulkheads help ships tolerate failures. But do more bulkheads mean less probability for failure? In our OSB/SOA Suite scenario, that's not necessarily the case -- unless each bulkhead is dedicated to a specific service domain.
Imagine a telco that wants to be aligned to eTOM domains:
- Fulfillment
- Billing
- Assurance
- Operations and Support
Now let’s imagine that we have powerful hardware and use Oracle Exalogic to deploy four Oracle SOA Suite domains to align them to eTOM. We create four bulkheads, each one storing and maintaining one of our four eTOM domains. If one domain goes down, the ship can continue sailing, but if two or more are down, then the ship will pretty much sink.

Figure 8
Figure 8 illustrates the bulkhead concept. Recipients can go down, but our "ship" will sail on. And every recipient is also divided in smaller pieces.
In this case, our bulkheads can be as small as a managed server within a domain. As we can see, the domains are isolated and they can also be perceived as a larger bulkhead. In this scenario, if Operations and Support goes down, Billing, Assurance, and Fulfillment are still alive and the enterprise can continue operating.
We can take the idea even further by using SOA Suite partitions as smaller bulkheads. Not only are our domains isolated, but so are services within those domains. Keep in mind that 12.2.1 offers the capability to assign a WebLogic work manager per SOA partition. With that capability, a smaller bulkhead can be a partition within a SOA Suite domain and, due to its using a particular work manager, things like threads are isolated. Problems affecting a service in one partition will not affect services in another partition.
As we can see, Oracle SOA Suite offers some good technical options to support the bulkheads strategy.
Figure 9
There are several other ways to create this bulkheads strategy. We are not going to cover them within the scope of this article, but we definitely will in a separate one where we will talk about Docker, WebLogic 12.2.1 Multitenancy and Microservices.
Timeouts
In Oracle SOA Suite, certain infrastructure attributes control the transaction timeouts. Timeouts are essential to protect our SOA infrastructure for long-running synchronous calls to external components (databases, web services and other applications). If one of these components takes a long time to respond to our call, we are generating long-running threads.
If these threads are still running after a determined time period (600 seconds by default), then the WebLogic managed servers go intoWarning state and threads in the thread pool are marked as STUCK. After a considerable number of STUCK threads, our infrastructure will be forced to stop accepting and processing requests.
To protect our SOA domain in Oracle SOA Suite, it’s important to finely tune certain parameters into order to get the appropriate behavior.
The first of these parameters is JTA timeout, which specifies the maximum amount of time, in seconds, that a distributed transaction is allowed to be alive. After this time, the transaction is automatically rolled back. Generally, this is configured as the largest time in the infrastructure. To configure JTA timeout you must navigate to:
WebLogic Administration Console > domain > JTA > Timeout seconds (the value is in milliseconds)

Figure 10
The second level are the SOA EJB timeouts. The EJB timeouts that must be modified are:
- BPELActivityManagerBean
- BPELDeliveryBean
- BPELDispatcherBean
- BPELEngineBean
- BPELFinderBean
- BPELInstanceManagerBean
- BPELProcessManagerBean
- BPELSensorValuesBean
- BPELServerManagerBean
NOTE: In version 12c there are 4 additional EJBs:
- BPELCacheRegistryBean
- BPELCacheStoreBean
- BPELClusterBean
- BPELKeyGeneratorBean
To configure these timeout values, navigate to:
WebLogic Administration Console > domain > Deployments > soa-infra (expand) > EJB (expand) > BPELBean (select) > Configuration (tab) > Transaction Timeout (the value is in seconds).
The third timeout to configure is SyncMaxWaitTime, the maximum amount of time that a BPEL process will wait before returning a result to the client. This is a domain-level property of Oracle BPEL Engine (applies to all BPEL processes deployed on the same container) and applies only to synchronous calls.
To configure this timeout, navigate to:
Enterprise Manager > Navigation Icon (on the left) > soa-infra (click, right-click is not allowed in 12.2.1) > SOA Infrastructure (drop down) > SOA Administration > BPEL Properties > More BPEL Configuration properties (link) > SyncMaxWaitTime (the value is in seconds).

Figure 12

Figure 13
After configuring these properties, you can configure specific timeouts for your BPEL processes (bindings) in composite applications or your Business Services in Service Bus projects.
As you know, a Business Service in Service Bus projects represent a reference to an external component—databases, JMS, web services, and other applications. Timeout configuration is a graphic activity in Service Bus. You must navigate to your business service and select the Transport Detail tab, then configure Read Timeout and Connection Timeout properties.
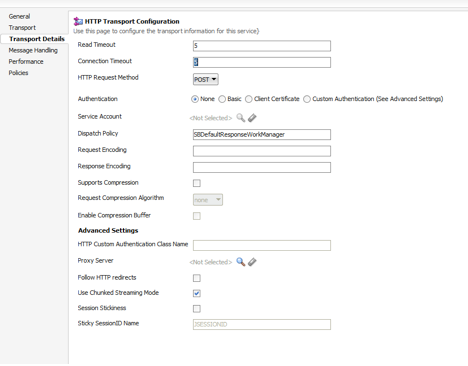
Figure 14
Just go to the reference section in the composite.xml file and add the following properties to the binding:
- oracle.webservices.local.optimization (false)
- oracle.webservices.httpConnTimeout (timeout in milliseconds)
- oracle.webservices.httpReadTimeout (timeout in milliseconds)
Your composite code looks like this:

Figure 15
You must disable local optimization because timeout (read and connection) properties work over HTTP. Local optimization is enabled by default in Oracle SOA Suite to optimize synchronous calls between BPEL processes deployed on the same container. If we maintain this property as “true”, HTTP timeouts will not be considered.
These timeouts can be configured for each binding in your composite application.
Configuring timeouts in SOA Suite allows communication with the clients when a synchronous call is getting long. The clients can then manage this message and SOA infrastructure can break all the long-running threads, avoiding unnecessary resource (threads, memory, processor) consumption and protecting servers from STUCK threads and a possible loss of service. Set the following scenario:
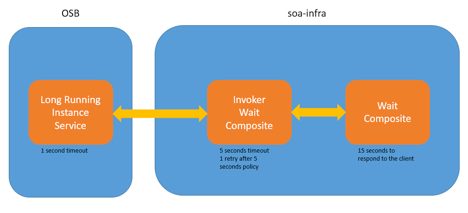
Figure 16
Wait Composite is a BPEL Process (service A) with a wait activity. It waits 15 seconds before responding to the service consumer.
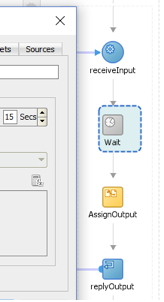
Figure 17
Invoker Wait Composite is another BPEL Process (service B) that invokes Wait Composite. This composite has configured timeout (read and connection) properties, 5 seconds for each property. We also configured local optimization property (false) because both BPEL processes are deployed in the same container. Also, this BPEL process uses Fault Management Framework to retry once (after 5 seconds) if the execution failed.

Figure 18

Figure 19
Long-Running Instance Service is a Service Bus Project (service C). This service has a Business Service with 1 second timeout configured. Business Service calls Invoker Wait Composite.
In this scenario, Wait Composite BPEL (service A) takes 15 seconds to respond to its invoker (service B). Service A will not throw any error, it will just take 15 seconds to respond. When service B calls service A, after 5 seconds (timeout configured) it will generate a timeout exception. Because of the policy configured, service B will retry once after 5 seconds but service A takes another 15 seconds to response. Then, the caller catches the timeout exception and responds with an error message.
Timeouts are one of the most important considerations. What if the invoker has not configured timeout parameters? And what if the invoker doesn’t have a catch block to manage the error message?
Further, we have service C invoking service B. Service B takes 10 seconds to respond to its client (5 seconds for the timeout configured and another 5 seconds for the retry interval). If the Business Service has not set timeout properties, then service C would wait until service B responds.
Now, imagine this scenario with response times on the order of 10, 15 or 20 minutes. Imagine also a lot of requests to service C. This causes an important number of STUCK threads within the SOA infrastructure, both managed servers, SOA and OSB.
This is a simple but very effective way to protect our SOA infrastructure, using timeouts. Using these properties in the appropriate component, we do not have a cascade effect that can damage WebLogic servers’ performance or state.
Redundancy
This seems to be the obvious one in this set of strategies for avoiding failures. It’s regularly adopted throughout SOA/Service Bus implementations, not only with Oracle but with any type of vendor.
We included it here because sometimes it is not understood as a benefit and a strategy. We, sometimes, do not tolerate that one node of a two-node cluster is down. But why? Isn’t that the purpose of redundancy? Isn’t this targeted for a fault tolerance strategy?
The Oracle SOA Suite 12c Enterprise Deployment Guide dictates this type of deployment for clustering and redundancy purposes:

Figure 21
(Image from Fusion Middleware Enterprise Deployment Guide for Oracle SOA Suite)
As we can see, the OSB, SOA, and OWSM are redundant along a couple of servers. Even the repository (database) is deployed in an Oracle RAC mode. At the middleware layer, this deployment leverages the WebLogic cluster capabilities.
By itself, this is going to give us redundancy on our integration pipelines and Services. Imagine a node goes down—well, the other one is going to serve the load while the first node is unavailable. And this is true. If you have this type of architecture, trust it. Trust the clustering capabilities that this offers. While we do want the platform to be as stable as possible to avoid any type of down time, if we have to work with one node because the other one fails, then let it be and recover the damaged node. Don’t panic: this architecture is built for exactly such situations.
The first thing to highlight about this strategy: trust WebLogic + SOA Suite clustering/redundancy capabilities. They will give you redundancy on your Services. Imagine that you have a good number of consumers using your services on a high-transactional environment. Suddenly, one node goes down: something happened at a low-level layer, the OS has an issue and has decided to restart. Consumers are hitting a load balancer, which recognizes that one node is down and redirects all the calls to the node that is still available. Services are ready in both nodes; even composites that are dehydrated can continue execution in the available node. The redundancy/clustering capabilities of Oracle SOA Suite protect you.
Oracle SOA Suite + WebLogic + Coherence offer different ways to promote redundancy. Let’s analyze some of them:
- Oracle Coherence: Coherence has been incorporated into OSB since the 11g release. It is used to enable data caching for Proxy Services in OSB. Let’s imagine a Customer service; among its operations is one that gets the basic data for a given customer. A variety of consumers use this service, consuming it through different channels: mobile, web, internal applications, etc. Cache is available through all the nodes of the OSB cluster, or even through more machines, if your architecture allows it. In this case the services are redundant, and Coherence is also giving you redundancy for the data access. In this scenario you have doubled up the redundancy strategy, not only for the Services but for the data access as well.
- JMS Distributed queues: If your services rely on JMS queues/topics, WebLogic can distribute those resources throughout the WebLogic cluster. A failure in one node is not going to put messages at risk. Rather, the message will be distributed along the cluster, and hence are always available. If you mix this with persistent stores based on Database tables, you not only have redundancy on your queues, but also fault tolerance for the storage of those messages.
- Business Services pointing to multiple endpoints:. OSB offers this capability; it is possible to configure a service that points to a set of different endpoints.
- Composites also offer something similar. But in this case it will work only if the first endpoint fails. Imagine the following entry of a composite.xml:
- Coherence Federated Cache: Similar to the first point of this list, we can leverage the Oracle Coherence Feature for a federated cache. Services in OSB that use Oracle Coherence can benefit from this feature. Imagine that the Coherence Cache is distributed along two different sites that are separated considerably:

Figure 22
In this case, we have redundancy at the Endpoint level. Specific rules can be applied for this endpoint in case of a failure. For example: if an endpoint stops responding it can be marked as inactive.
<code>
<reference name="Customer" ui:wsdlLocation="Customer.wsdl">
<interface.wsdl interface="http://www.spsolutions.com.mx/Customer/
First/BPELProcess1#wsdl.interface(BPELProcess1)"/>
<binding.ws port="http://www.spsolutions.com.mx/Customer/Second/
BPELProcess1#wsdl.endpoint(bpelprocess1_client_ep/BPELProcess1_pt)"
location="http://10.10.10.10:8001/soa-infra/services/default/
First/customerprocess1_client_ep?WSDL">
<property name="endpointURI">http://10.10.10.10:8001/soa-infra/
services/default/Second/customerprocess1_client_ep</property>
</binding.ws>
</reference>
</code>
The first endpoint is the default, in this case:
http://10.10.10.10:8001/soa-infra/services/default/First/customerprocess1_client_ep?WSDL
All requests are going to hit this endpoint, until a failure occurs.
If this endpoint fails, the second one will be used:
http://10.10.10.10:8001/soa-infra/services/default/Second/customerprocess1_client_ep
Here, we have a redundant endpoint for that particular service (Customer). It can be deployed on a different infrastructure, a different domain, etc. The important thing is that we are protecting our service to avoid a failure, and to maintain business continuity for our organization.
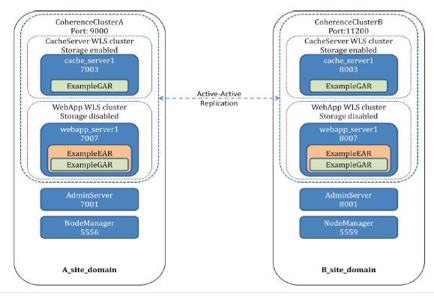
Figure 23
Services will have the redundancy described in previous bullets + this federated cache on a different site/domain. Isn’t this an infrastructure that will be as highly available as possible? Our services and integration pipelines will have enough redundancy to continue executing even if a disaster happens.
Conclusion
We’ve gone through four major strategies for avoiding failures:
- Circuit Breakers
- Bulkheads
- Timeouts
- Redundancy
We can mix them and, in fact, we encourage you to do so. Some strategies are better suited for some scenarios than others. Do not try to use the same formula for all scenarios—that will lead you to some trouble.
Try to minimize this concept of the "SOA/OSB Complicity." We don’t want to be the accomplice and/or the victim when failures happen. We need to be always ready when failures happen and react to them proactively. A better design and deployment will bring you longer weekends and fewer headaches. How about spending some time with your family, instead of waiting for your phone to ring because the OSB has crashed?
Convince the infrastructure team that you need more infra to deploy a bulletproof deployment with enough bulkheads to contain failures. Do not hesitate about that. It’s better for the entire organization.
Try to always explain in a simple way how the architecture works—it will save you some time when services go live. If your teammates understand how clustering works, how timeouts work, etc., they will also understand failure scenarios.
Oracle SOA Suite 12c offers a good set of tools to implement those strategies. Use them, rely on them, do not hesitate to implement them.
Trust the technology that Oracle offers; if you have a cluster, then use it. If a node needs to go down, it is OK. Try to recover the damaged node, but do not get in panic. The reason you deployed a cluster is to tolerate failures, so use it when necessary.
Always arrange SLAs with the rest of the platforms. Do not assume responsibility in timeouts, or large response times. If you don't do this, then expect a lot of calls from the monitoring team saying: "The OSB timeouts are very high." The reality is that the OSB is working as well as ever, but the platforms are having high response time. This affects the OSB, and makes it the favorite accomplice of the IT department.
About the Authors
Oracle ACE Rolando Carrasco is a SOA Architect and co-founder of the S&P Solutions team in Mexico and Latin America. He's been working with Oracle SOA since 2003/2004, and his professional career has been focused in the integration space. Rolando is also co-director of the Oracle Users Group in Mexico (ORAMEX), and co-founder of the SOA MythBusters blog.
Leonardo Gonzalez, a SOA architect with S&P Solutions, has been involved in IT projects spanning the entire deployment cycle, and has been engaged as an analyst, designer and developer in delivering enterprise architectures.