Integrating HFM 11.1.2.4 with ODI Metadata Knowledge Modules
Ricardo Giampaoli and Rodrigo Radtke
June 2017
Introduction
Oracle Hyperion Financial Management (HFM) is an Enterprise Performance Management (EPM) tool that provides financial consolidation and reporting that enable users to rapidly consolidate and report financial results, meet global regulatory requirements, reduce the cost of compliance, and deliver confidence in the numbers.
Like other EPM tools, HFM relies on dimensions (metadata) and fact measures (data) that are loaded into the tool and used to create reports. Prior to its latest version (11.1.2.4), HFM could use Oracle Data Integrator (ODI) to load such metadata and data into the tool, which led large companies to build large environments around HFM and ODI integrations.
However, in HFM's latest version, Oracle decided to remove its support for ODI, meaning that all HFM integrations would have to move from ODI to manual iteration with HFM, another integration tool would have to be used, or custom code would have to be created using the new Java HFM API. For new HFM implementations, the impact of Oracle"s decision could perhaps be managed, but for existing integration processes it would have a great impact, since none of the available options are smoothly implemented within large existing environments.
This article focuses on how we can achieve metadata load to HFM using ODI Knowledge Modules (KMs) built using the new Java HFM API. With this kind of ODI KM, companies can continue with legacy ODI/HFM integrations without the need to drastically change integration processes or add a new tool into their environment. New HFM implementations could also benefit from these ODI KMs, since they allow any kind of complex ETL logic on metadata and data before easily loading it to HFM.
Current HFM metadata integration process state
Before version 11.1.2.4, ODI could be easily used for HFM integration processes. ODI used its KMs with specific HFM drivers (HFMDriver.dll). provided by Oracle, which were used to access and manipulate HFM applications. Here is a current list of all possible metadata load processes to 11.1.2.4 HFM applications:
Data Relationship Management (DRM): DRM is the main Oracle tool for storing and managing large/complex sets of metadata that can be consumed by a diverse range of downstream applications. In the case of HFM, DRM can be used in two ways. For HFM Classic, DRM can create and export .APP files that contain the metadata information; these .APP files can later be imported within the HFM workspace. For non-classic HFM applications, DRM can create and export .ADS files, which can be used to load EPMA interface tables and later be imported into the HFM application.
Enterprise Performance Management Architect (EPMA): EPMA works only for non-classic HFM applications. It relies on its interface tables, which can be populated by metadata before being sent to HFM applications. Besides the "no support" for classic HFM applications, Oracle has already stated that EPMA is not in its future roadmap and that new implementations should not consider EPMA. In other words, EPMA is still supported by Oracle, but no new development/enhancement will be done in the tool.
Financial Data Management Enterprise Edition (FDMEE): Oracle is pushing hard to have FDMEE be the ultimate integration tool for both data and metadata in the EPM space. However, FDMEE has some serious limitations, especially regarding metadata integration process. Currently, FDMEE is able to load dimension metadata to HFM only from Fusion GL, EBS and PeopleSoft Enterprise Financial Management applications.
Manual Iteration: Users may always go to the HFM application on the workspace and execute manual metadata extract/load processes in the "Administer" section. For HFM classic applications, users can use the HFM desktop client, which is located on the HFM server; it may work well for very simple metadata processes, but it is not scalable for enterprise environments.
Custom Code with HFM Java API: With HFM 11.1.2.4, Oracle released a brand new Java API that can be used to perform several tasks on HFM applications. This is probably the best route if you have complex large environments or if specific ETL logic is applied to the metadata elements. The Java API allows you to automate the entire metadata process, creating a scalable, robust and secure environment.
With these options, large/complex environments will end up creating their own custom code with the Java API, because all the other options have some kind of limitation. Companies with existing ODI integration processes may not want to rebuild everything from scratch or add a new tool to their architecture. Since our architecture had both of those pain points, we decided to create brand-new ODI KMs using the HFM Java API. This approach brings the following benefits:
- Although it may be considered custom code, the code itself will be centralized inside ODI KMs, which can be shared and reused several times in different integration projects. Also, since the code is centralized, we have one single point at which to fix a possible issue or to implement a future enhancement that could benefit the entire HFM architecture.
- HFM/ODI legacy code could be entirely reused, since it would be just a matter of switching the old KMs into the new ones (with some minor adjustments, described below).
- No new tool would need to be implemented within the company's existing architecture. ODI would handle all metadata, data and consolidation processes for HFM applications, as it was in the past.
- Complex ETL logic can be created and HFM may feed from virtually any source using ODI.
- Automated processes can be created without any kind of human intervention, creating a true enterprise solution.
The following article sections will focus on the details of what is needed to have the new ODI metadata KMs working in your environment: one RKM for reversing HFM data store information inside ODI and one IKM for metadata load into HFM. They were built to be as generic as possible, so they could be used in several situations "out-of-the-box".
This article will also describe why some decisions were made when creating these new ODI KMs, because you may want to tweak the code for these customizable ODI KMs in order to solve a large problem in your architecture.
HFM Java API Architecture Requirements for HFM Classic Applications
Before we start with the ODI KMs, we need to understand a little bit about how the new HFM Java API works. Basically it is a replacement of the old HFM Visual Basic (VB) API. Oracle decided to make this architectural change in order to transform HFM into a platform-independent application in the future, since being Java-based would allow HFM to run in platforms other than Windows. This decision will greatly benefit the overall HFM architecture; the downside is that every component that used to use HFM VB API now needs to be converted to the HFM Java API.
The new HFM Java API can be used fairly easily for several admin tasks. This article does not aim to explain all of the API's methods or how to use them. Instead, it will focus on how to ready your architecture for it to work, and on basic explanations about some of its concepts. The steps described in this article were executed using the following apps/versions: HFM Classic 11.1.2.4 (on Windows Server 2012 R2 server), ODI 11.1.1.9 (on Windows Server 2012 R2 server and running an ODI standalone agent), JDK 1.7.0_67 and Eclipse Mars release (4.5.0).
The Java API must have the following requirements in order to run properly:
- JDK installed on the server that will run the code.
- Three HFM JAR files imported into your Java code: epm_hfm_web.jar, epm_j2se.jar and epm_thrift.jar. These three files are located on the HFM server, in the %EPM_ORACLE_HOME%\common\jlib\11.1.2.0 folder.
Taking a first look at those two requirements, it seems a very simple and straightforward effort: create some Java code in a machine that has JDK installed, and import the three HFM JAR files into it. The problem is that those three JAR files contain only manifest files, not the actual Java code needed to be used in HFM. In other words, manifest files contain only the class-path to other JAR files that contain the actual Java code or pointers to other manifest files that will have a class-path to still other JAR files. As an example, Figure 1 shows the content of the epm_thrift.jar Manifest file:
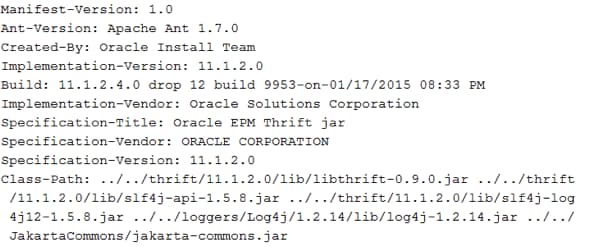
Figure 1 - Example of a Manifest File
As you can see, this manifest file points to several other JAR files, including libthrift.jar, Log4j.jar, jakarta-commons.jar and so on. You may also notice that it is also pointing to specific folders (e.g., ../../loggers/Log4j/1.2.14/lib). This means that we cannot only copy and paste those three JAR files to a server and import them in our HFM Java program because those files would point to other JAR files, in specific folders, that may not be there.
This kind of manifest architecture is great to organize and avoid JAR duplicate files over our environment, but also introduces a new problem to be handled: how do we make our Java code (that will be inside of ODI) import such JAR files and all dependencies? This question leads us to two main architectural approaches:
- Have ODI installed in the same server as HFM is installed. This would be the easiest and fastest approach, since we would only need to point ODI to those three JAR files that are located in the HFM directory. The only problem with this approach is that sometimes it is not possible or desirable (from an architectural point of view) to have an ODI agent installed on the HFM server.
- Copy the necessary HFM JAR files to the ODI agent server. In order to prevent the copy of the entire HFM Middleware folder, we can figure out which JAR files are really used on those manifest files and copy only the necessary ones to the ODI agent server.
Both approaches have pros and cons. Approach number one can be accomplished quickly and easily, but it has the inconvenience of having both ODI and HFM installed on the same server. This approach can be beneficial for future upgrades of HFM, since you won't need to change anything in ODI if you decide to upgrade HFM (or maybe just point to a new directory).
Approach number two is more complex but gives us the flexibility to have HFM and ODI on different servers. This approach leads us to two main challenges: figuring out which JAR files are necessary for the HFM code and, if we upgrade HFM in the future, perhaps searching for all those JAR dependencies again, just to make sure that they did not change in the new HFM version.
Both methods need to have some kind of setup in ODI in order to make them work, as described in the next section.
Using ODI and HFM on the same server
If your architecture allows you to have both HFM and ODI agent on the same server, you may use this approach, which is very simple. The only thing to do is to change the odiparams file (oracledi\agent\bin\odiparams.bat file in a standalone agent) and add the location of those three HFM JAR files. Open the odiparams.bat file and search for "ODI_ADDITIONAL_CLASSPATH". On that setting, set the location of the HFM JAR files, as in the example below (adjust the path accordingly for your environment):
set
ODI_ADDITIONAL_CLASSPATH=%ODI_ADDITIONAL_CLASSPATH%;"D:\Oracle\Middleware\EPMSystem11R1\common\jlib\11.1.2.0\epm_j2se.jar";"D:\Oracle\Middleware\EPMSystem11R1\common\jlib\11.1.2.0\epm_thrift.jar";"D:\Oracle\Middleware\EPMSystem11R1\common\jlib\11.1.2.0\epm_hfm_server.jar"
Save the file, restart the ODI agent and you"re done: ODI will read those three manifest files and will be able to locate all the necessary HFM JAR files in order to run HFM Java code in its agent.
It's worth mentioning here why we are setting those JAR files in the ODI_ADDITIONAL_CLASSPATH setting, instead of just coping them to oracledi\agent\drivers folder, as we normally do for other traditional jar files for ODI. The reason here is again due to the nature of the manifest files, which do not have the actual JAR code inside of them and just point to another JAR file, which has relative paths to its own JAR file.
In other words, if we try to copy the three HFM JAR files to the ODI agent drivers file, ODI will read the manifest file but it will not be able to find the other JAR files, since their paths are relative to the original JAR file and they will not exist inside ODI agent folders. But, if we directly add the full path to their original path inside the HFM installation using ODI_ADDITIONAL_CLASSPATH, they will work just fine.
Using ODI and HFM on different servers
Searching for JAR dependencies in this case is a job that cannot be done easily or manually, simply because a manifest file can point to a set of JAR files that can point to another set of JAR files and so on. Luckily, there are some tools available out there that can make this job easier for us.
The appendix to this article contains a list of all the necessary JAR files to be used in the HFM 11.1.2.4 and ODI integration process, and also describes how to find all necessary JAR files using Eclipse Java IDE (you may use different methods/tools if you prefer). This resource will come in handy if, as stated earlier, you upgrade HFM to a newer version and need to make sure you have the most up-to-date JAR files on your ODI server.
First you will need to install Eclipse IDE on the HFM server. The idea here is to use Eclipse to create a very simple Java class with the three necessary HFM JAR files associated with it. Next, we will use Eclipse's export method to generate an "Executable Jar" file, which will save our dummy Java class together with all JARs referenced by the manifest files. After that, it will be just a matter of copying those JAR files to the ODI agent folder.
After you've installed Eclipse, create a new Java Project by going to File\New\Java Project menu.
Figure 2 - Creating a Java Project
After that, we right-click the Java Project and create a new Class.
Figure 3 - Creating a Java Class
In order to associate the three necessary HFM JAR files to the Java Project, right-click it again and select "Build Path"\"Configure Build Path...".
Figure 4 - Configuring Build Path
Go to "Libraries" and click "Add External JARs...". Navigate to the HFM install folder and add epm_hfm_web.jar, epm_j2se.jar and epm_thrift.jar from the %EPM_ORACLE_HOME%\common\jlib\11.1.2.0 folder.
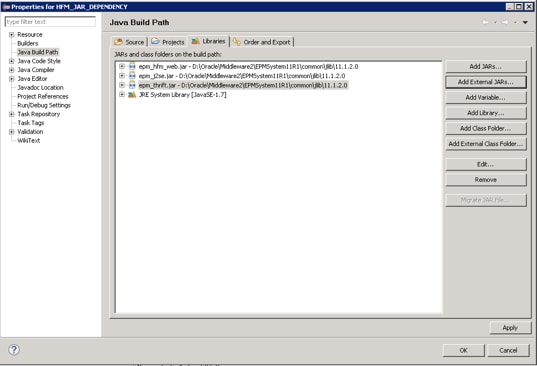
Figure 5 - Adding External JARs
Go to the Java file and create any dummy code (like a "Hello World!") and execute it as in Figure 6, below. This step causes Eclipse to create a valid .class file that will be exported later.
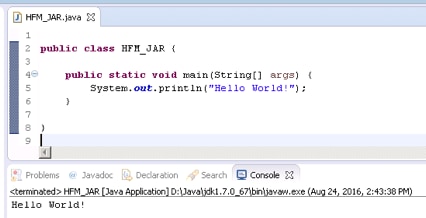
Figure 6 - Creating and Executing a Dummy Java Code
Now go to "File\Export" menu and select "Java\Runnable JAR file".
Figure 7 - Exporting as a Runnable JAR file
In the "Launch configuration" box, select the Java class that you created, as well as a folder that will contain the exported JAR files (you may select any name here for your dummy JAR file). Here is the big catch on this process: on "Library handling" select "Copy required libraries into a sub-folder next to the generated JAR".
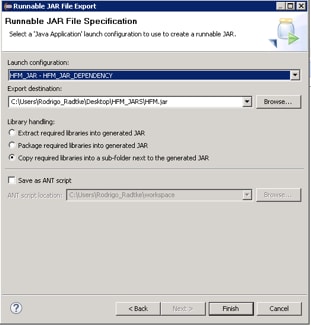
Figure 8 - Exporting Required Libraries
This option will do exactly what we want Eclipse to do for us here: it will analyze our code dependencies, check the three HFM manifest files and copy to a sub-folder all the JAR files necessary to run that code -- in other words, all the JAR files that we need to copy into our ODI agent server in order to make our code work there.
Go to the export folder and check its content. It will contain the dummy JAR file from our Java class and also an HFM_lib folder. When we double click that folder, we'll see 132 JAR files inside, which we need to copy to our ODI agent server. Copy all JAR files and paste in the oracledi\agent\drivers folder.
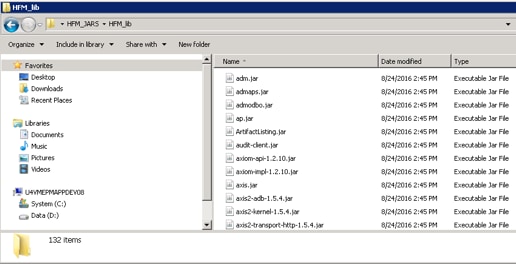
Figure 9 - Exported JAR Files
Restart the ODI agent. It should be ready to execute any HFM Java code inside ODI. It's worth mentioning that with this approach we don't need to change anything in the odiparams file, since oracledi\agent\drivers is already read by default when the ODI agent starts. Also remember that, when you upgrade HFM to a newer version, you will probably need to repeat those steps again in order to guarantee that you have the complete set of JAR files in the ODI agent folder.
ODI Reverse Knowledge Module for HFM 11.1.2.4
This section will describe the concepts used to create the ODI RKM for HFM11.1.2.4. Although the majority of ODI/HFM developers will want only to import the ODI RKM (links to its download can be found in the APPENDIX section) and use it in their projects, this article will describe the main steps and decisions that were made to create this RKM. Understanding how it works behind the scenes will allow you to make changes to its code if necessary.
This RKM contains only three steps, as showed in Figure 10, below. The first and the last step are used to Reset and Set the ODI datastore metadata information. They use standard ODI API calls (SnpsReverseResetTable and SnpsReverseSetMetaData) that are responsible for managing SNP_REV ODI tables.
SNP_REV ODI tables reside on ODI work repository schema and are used as "stage" tables that are populated with the appropriate data store information before it is applied to ODI itself. In other words, every time that we reverse any data store to ODI, there is a process that first resets the SNP_REV tables, then populates it with the correct information. and then sets the ODI data store information based on what was stored on SNP_REV tables.
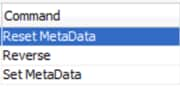
Figure 10 - RKM Command Steps
The second step is where all the true logic is stored. This step will be responsible for connecting to the HFM application, sending an extract metadata command to HFM so it creates an .APP file with the current metadata information, reading its format and parsing it into SNP_REV tables, as we can see in Figure 11, below. Here we are not interested in what kind of metadata lies in the HFM application at the moment that we run the reverse process for ODIÐwe are interested in the column and headers that exist in the .APP HFM file.

Figure 11 - ODI - HFM Reverse Process
We can see in Figure 12, below, an example of what an .APP file looks like for the Entity dimension. Each .APP file will contain a header with an exclamation mark, indicating a dimension that exists in HFM. Right after that, on the line below, we are going to have all the columns that need to be sent to HFM in order to load a member to that dimension.
Since each dimension has its own set of columns, and we also may have a different number of HFM custom dimensions in different HFM apps, the ODI reverse process just sends a command to HFM to extract all dimensions at once, in a single .APP file, and parses the entire file looking for these dimension headers. When ODI finds one of them, it inserts its relevant information in the SNP_REV_TABLE and SNP_REV_COL tables.

Figure 12 - Entity .APP File Example
There is also some additional information that is added to the ODI data stores that does not come from the .APP file itself. This information was added to the data stores in order to facilitate other processes (e.g., Metadata and Data loads). Table 1, below, compiles the additional information that the reverse process creates automatically as well as the reason behind its creation.
| Feature | Reason |
|---|---|
|
Creation of AggregationWeight column on Custom dimensions as Read Only |
AggregationWeight does not exist as a "column" in the .APP file, but HFM uses it when building the Custom hierarchies. If nothing is mapped to AggregationWeight in the metadata load process, it defauls to 1. |
|
Creation of ParentMember column for all dimensions as Read Only |
ParentMember column does not exist as a "column" in the .APP file, but HFM uses it to build the parent/child relationship between the members. |
|
Table Alias are set accordingly to the HFM API function name of that dimension |
The table Alias is used in the other HFM KMs to call the correct "SET" Java command for each dimension to which it belongs. |
|
"Default Parent" column receives "DefaultParent=" as a default value |
This default value is automatically added to the .APP file during the HFM metadata load process. |
|
"Description(s)" column receives "<%=odiRef.getOption( "DESCRIPTION_LANGUAGE" )%>=" as a default value |
This default value is used in the HFM metadata load process to select the language in which the metadata is stored. This option will default to "English" in the metadata load IKM. |
|
HFMData data store is created automatically based on the dimensions that exist in the .APP file |
HFMData data store is used to load data to HFM using the data load IKM (which will be described in the next article). |
Table 1 - RKM Additional Features
ODI RKM usage
This section will focus on how to use the new RKM after the architectural setup is done. This article assumes that readers are already familiar with the basic concepts of HFM and ODI usage, topology, model and interface configurations, and will show only the high-level steps on how to get the data store information reversed to ODI.
The first thing to do is to import the new RKM into ODI. It is a very simple KM, with just one option to set the log file that will be generated when reversing the data store information. When we double click it, there is a brief description of what it is and how to use it. There are only a couple of differences between the previous/older ODI/HFM RKM. The first difference is that the new RKM does not yet support "multi-period" HFM data tables. This, of course, can be implemented in the future if needed, but for now, we decided to not implement it.
The second difference is how to set up the "Cluster (Data Server)" information on Data Server (Physical Architecture). For the new HFM API, we need to inform two new settings: Oracle Home and Oracle Instance Paths. Those paths are related to the server on which your HFM application is installed. These settings will be used internally in HFM API to figure out all HFM information related to that specific HFM instance.
Due to these two new settings and in order to continue to accommodate all connection information within a single place (ODI Topology), "Cluster (Data Server)" was overloaded to receive three settings instead of just one, separating them by a colon. So now "Cluster (Data Server)" receives "dataServerName:oracleHomePath:oracleInstancePath" instead of just dataServerName.
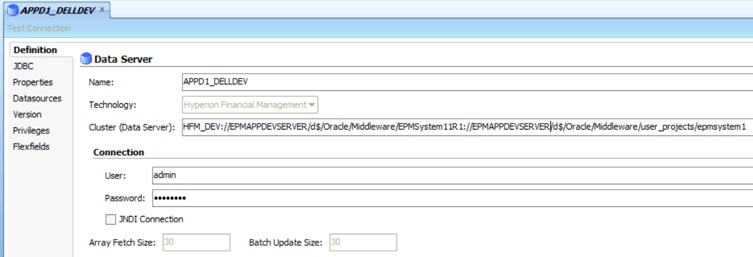
Figure 13 - Data Server Configuration
With these considerations in mind, it is just a matter of creating a new Data Server and setting both the overloaded "Cluster (Data Server)" information and the user/password that ODI will use to access the HFM application. After that, we just need to create a Physical Schema with the name of the HFM application, a new Logical Schema and associate that to a context.
Now we are ready to use the new RKM to reverse the data store information. Create a new ODI Model and select the Logical Schema that is pointing to the HFM application. On the "Reverse Engineer" tab, select "Customized" and the new RKM. Add a valid folder location for this reverse execution log and click "Reverse Engineer".
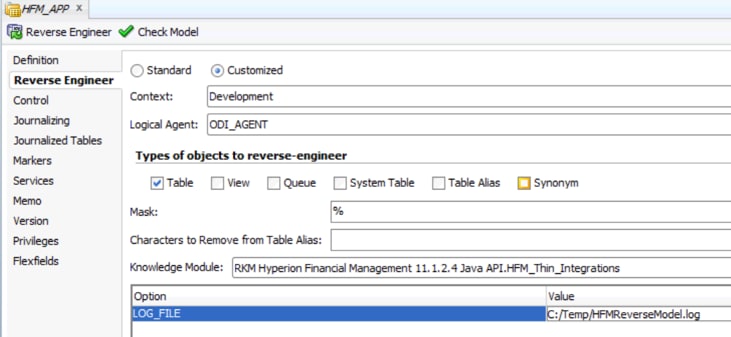
Figure 14 - Model Configuration for Reverse Engineer
Check if the execution completed successfully in Operator. If it did, you should now see a list of all HFM dimensions, plus HFMData data store information within your ODI Model component.
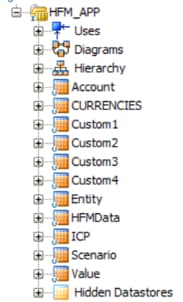
Figure 15 - HFM Reversed Successfully in ODI
ODI Metadata Integration Knowledge Module for HFM 11.1.2.4
The IKM for HFM metadata load is divided in two steps, as we can see in Figure 16: the first creates a valid .APP file in a folder location and the second loads this .APP file to the HFM application. This IKM basically mimics a manual process that can be done in HFM using workspace; users could create a valid .APP file and load it, through workspace, to the HFM application. ODI is used here to abstract all the details behind the creation of a valid .APP file and to give users the power and flexibility to do any kind of ETL logic before creating and loading the file to HFM.
Figure 16 - IKM Command Steps
The first step of the IKM creates the three necessary .APP sections: header, members and hierarchy sections. The header section is basically created based on the IKM options that are informed during the ODI interface creation.
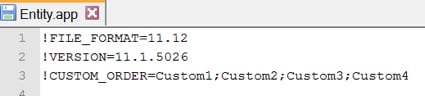
Figure 17 - .APP Header Section
The members section is built using the metadata information that returns from our source data stores.

Figure 18 - .APP Members Section
The hierarchy section is build using Parent/Label columns to build the relationship between the members.

Figure 19 - .APP Hierarchy Section
This IKM uses some of the pre-configured information set in the HFM data stores that were created by the new RKM; for example, in the members section the code will return all target data store information that is not set as a "Read only" column. If you recall, all the "artificial" columns that were created in the RKM process, like "Aggregation Weight" and "Parent Member", were set as "Read Only", meaning that those columns are not a real part of the .APP file and they will not be created as a members column in the file either.
However, they will be used later on in the hierarchy section, where "Parent Member" will be used to create the hierarchy association between the members and "Aggregation Weight" will be used as an extra column for the Custom dimensions, which are the only dimensions that use the "Aggregation Weight" information. The IKM will use the table alias information to call the correct "set" method in the Java API. For example, for the "Account" dimension it will call the "setAccounts" API command, based on its alias, which is named "Accounts". The same holds true for the "Entity" dimension, which will call "SetEntities" based on its "Entities" alias.
As you can see, the metadata IKM relays some information that weas created as part of the ODI data store in the RKM reverse process, so if you plan to make any changes in the data store object itself, do so with caution, since some modifications may cause the new IKM to stop working properly.
ODI IKM Metadata usage
After HFM data store information is correctly reversed inside ODI and the new "IKM SQL to Hyperion Financial Management Dimension 11.1.2.4 Java API" is imported, it's time to build the metadata load interface. You'll notice that it has many more options than the old IKM for HFM Metadata. This is because the new IKM basically works in a two-step process: first it creates an .APP file in a folder location, then it gets this .APP file and loads it to HFM.
The creation of this .APP file has some setups that need to be defined in the ODI interface object, for which we use the IKM options. Table 2 lists all the available options and a description of how to use them.
| Option | Description | E.g. Values |
|---|---|---|
|
APP_FILE_DELIMITER |
Defines which delimiter will be used in the .APP file creation. |
; , | * |
|
APP_FILE_LOCATION |
Defines the folder location where the .APP file will be created and stored before loading to HFM. |
C:/Temp/Account.app |
|
CUSTOM_ORDER |
Custom dimension order in HFM application. |
Custom1;Custom2; Custom3;Custom4 |
|
DESCRIPTION_LANGUAGE |
Description language used in the metadata members. |
English |
|
FILE_FORMAT |
.APP file format for the HFM application. |
11.12 |
|
LOG_LOCATION |
Log File location. |
C:/Temp/Account.log |
|
ORDER_BY_COLUMNS |
Select a valid column name from the source result set that will be used to sort the members in the .APP file. |
Any column name from the source result set |
|
REMOVE_DUPLICATED_ FROM_HIERARCHIES |
This option removes any duplicated reference in the Parent-Member relationship that may exist in the metadata source. The option was created because HFM does not allow identical duplicated relationships in the hierarchy session of the .APP file. If this situation exists in your metadata (duplication), set this option to True. Caution: if set to True, ORDER_BY_COLUMNS will be ignored and the file will be created ordering by Label and Parent Member. |
True False |
|
SET_CHECK_INTEGRITY |
Checks the metadata against the data to ensure integrity. |
True False |
|
SET_CLEAR_ALL |
All dimension members and corresponding data, journals, and intercompany transactions in the application database are deleted. |
True False |
|
SET_PRESCAN |
Set to True to verify that the file format is correct. Caution: this will not load the .APP file to HFM, but will only scan the file format. |
True False |
|
SET_USE_REPLACE_MODE |
If set to True, all dimension members in the application database are deleted and the members from the load file are put into the database. If set to False, HFM will load as Merge: If a dimension member exists in the load file and in the application database, then the member in the database is replaced with the member from the load file. If the database has other dimension members that are not referenced in the load file, the members in the database are unchanged. |
True False |
|
START_WITH_MEMBER |
Set the start column name which will be used to build the parent-child relationship. This must be a column from the target data store and it will be used together with the START_WITH_VALUE option. |
Any column name from the target data store. Generally Label or ParentMember |
|
START_WITH_VALUE |
Set the start value that will be used to build the parent-child relationship. This will be used together with the START_WITH_MEMBER option. |
Any value from the hierarchy. E.g.: = "Channel" = "Products" Is null Is Not null = "BS" |
|
VERSION |
.APP file version for the HFM application. |
11.1.5026 |
Table 2 - IKM Options
Knowing that the IKM options are used to create the .APP file correctly, let's look closely at the CUSTOM_ORDER, FILE_FORMAT and VERSION options, which are used to build a valid header for an .APP file. The easiest way to know exactly what your HFM application is expecting to receive in the .APP file header is to generate one .APP file manually from your HFM application. In your HFM application, go to "Application Tasks/Extract/Application Elements" and export any metadata from there.
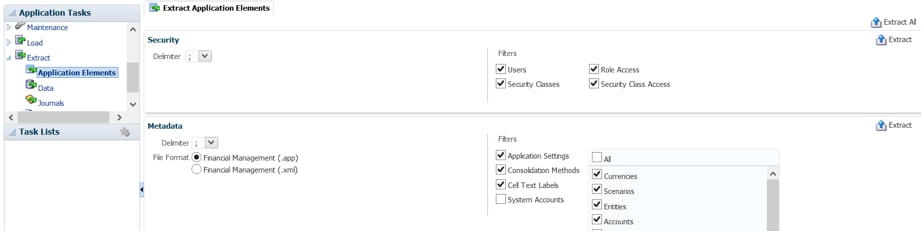
Figure 20 - Exporting .APP File from HFM
Open the generated .APP file and you will see a valid header, so you may use the same information on the ODI IKM options.
The second section of the .APP file is basically the metadata information itself, which will be built based on the interface ETL components (e.g., source transformation logic, target data store, etc.). There is no option that affects this section.
For the third section, four options are used to build it correctly: START_WITH_MEMBER, START_WITH_VALUE, REMOVE_DUPLICATED_FROM_HIERARCHIES and ORDER_BY_COLUMNS. These options will define how this IKM builds the Parent-Child relationship on the .APP file and its order.
It uses Oracle's CONNECT BY command to create this relationship and uses START_WITH_MEMBER and START_WITH_VALUE to figure out which is the first member of that hierarchy, building the hierarchy based on that.
The ORDER_BY_COLUMNS option will be used to define the members' order on the creation of the .APP file hierarchy. This is important, as HFM will load the members to the application in the same order as they appear in this section.
REMOVE_DUPLICATED_FROM_HIERARCHIES is a special option used on complex hierarchy models that contains "shared members" (a member that appears more than once in the hierarchy). In those situations, due to the nature of Oracle's CONNECT BY command, a member may appear twice, with the same information, in the hierarchy result set. HFM does not allow that and will throw an error if it happens. To bypass this limitation, the REMOVE_DUPLICATED_FROM_HIERARCHIES option may be used, but doing so will cause the ORDER_BY_COLUMNS option to be ignored and the result set will be only sorted by label and parent members alphabetically.
Since all the other options are self-explanatory and do not affect the .APP file creation, we may start to create the ODI interface itself. In this example we will load the Custom1 dimension from an Oracle table. Its creation is the same as any other interface: you may do joins, filters, ETL modifications to the mapped columns, and so on.
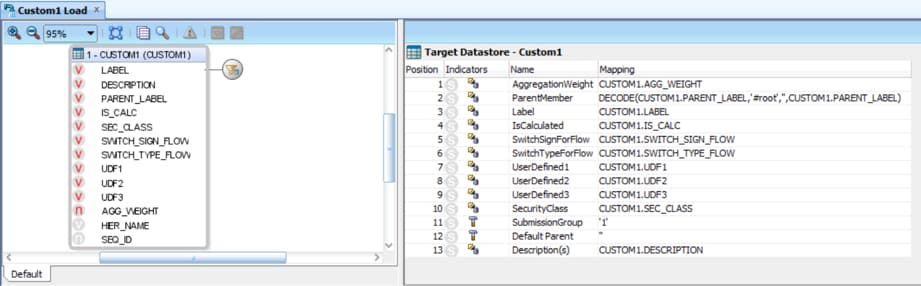
Figure 21 - ODI Interface for HFM Metadata Load
Note that, since our target is an HFM application, we need to set our Staging Area to a valid Oracle Logical Schema (probably the same used in our source data store) in order to do any ETL to the metadata.
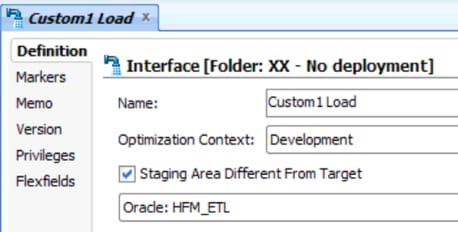
Figure 22 - Setting a Different Staging Area
In the Flow tab, select the options needed for your integrations and execute the interface. If all goes well, you will see two green steps in the ODI Operator, indicating that the metadata was successfully loaded to the HFM application. You may check the .APP file created on the folder that you added in the IKM option and the log that it generated.
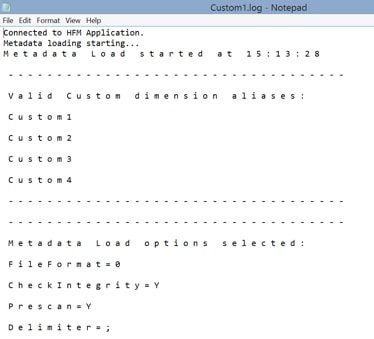
Figure 23 - HFM Metadata Load Log Information
As we can see, this is a very easy and transparent way to load metadata into HFM, using the same approach as the old version of ODI/HFM KMs.Conclusion: HFM/ODI integration in a real environment
This article demonstrates the true power of ODI as a development platform. ODI is far from being just another ETL tool, as it goes way beyond this scope to give us the opportunity to implement any kind of connectivity between virtually any existing technologies. With a little setup and a couple of redesigned KMs, we were able to re-implement the old HFM/ODI connectivity, allowing us to do any kind of ETL on the necessary metadata before loading it, systematically and easily, to HFM.
These new KMs have already proven their worth on real projects where several ODI jobs created using the old HFM KMs needed to be replaced by the new ones, as the company was upgrading HFM to a newer version. This was a great accomplishment since there was no need to install any new application to the environment, like FDMEE; further, all the legacy ODI codes could be reused, since the only change necessary to make ODI work in the new version of HFM was to replace the old KMs with the new ones and do some minor adjustments in its topology, data stores and interface options.
For new HFM implementations, the users could use ODI to create robust, scalable and enterprise integration solutions with very little development complexity, as the new ODI KMs abstract all the hard logic inside of them and can be reused as many times as necessary. Also, with ODI, users can integrate any kind of metadata and data sources into HFM, guaranteeing that all business requirements are fully implemented, even the more complex ones.
ODI is a dynamic and powerful tool that can provide an excellent platform for creating and maintaining EPM environments. This article demonstrates that we are limited in its use only by our imagination. With a few changes in the KMs we can overcome the boundaries of the default development, achieving a new level of excellence and thereby providing the increased flexibility, reliability and scalability to meet the challenges of a global and competitive environment.
About the Authors
Oracle ACE Rodrigo Radtke is a Software Development Consultant at Dell, where he specializes in ODI and EPM tools. A computer engineer experienced in software development, especially in the BI for Finance space, he is \ a certified professional on Oracle Data Integrator, Oracle SQL Expert, and Java (SCJP and SCWCD).
Oracle ACE Ricardo Giampaoli, a Master in Administration and system analyst, has been working in the IT environment for 20 years, the last nine years a an EPM consultant. He is a Certified professional on Hyperion Planning, Essbase, OBIEE and ODI, and works with a great variety of Oracle tools.
Rodrigo and Ricardo frequently share their expertise by presenting at Kscope and other events and via their blog: https://devepm.com/
Appendix
- RKM and IKM downloads: https://drive.google.com/drive/folders/0B6qArlZmuBsaYnpRVVNzeVJvV2M
- HFM Javadoc: https://docs.oracle.com/cd/E40248_01/epm.1112/hfm_javadoc/index.html
- HFM Developer and Customization Guide: http://docs.oracle.com/cd/E57185_01/HFMCD/hfm_customdev.html
- HFM Administrator's Guide: http://docs.oracle.com/cd/E57185_01/HFMAD/toc.htm
- Eclipse Home Page: https://eclipse.org/
Required Jar files for HFM 11.1.2.4 and ODI 11.1.1.9 integrations:
| Jar Files | |
|---|---|
|
adm.jar admaps.jar admodbo.jar ap.jar ArtifactListing.jar audit-client.jar axiom-api-1.2.10.jar axiom-impl-1.2.10.jar axis-ant.jar axis-jaxrpc-1.2.1.jar axis.jar axis2-adb-1.5.4.jar axis2-kernel-1.5.4.jar axis2-transport-http-1.5.4.jar axis2-transport-local-1.5.4.jar backport-util-concurrent.jar broker-provider.jar bsf.jar castor-1.3.1-core.jar castor-1.3.1.jar com.bea.core.apache.commons.collections_3.2.0.jar com.bea.core.apache.commons.net_1.0.0.0_1-4-1.jar com.bea.core.apache.commons.pool_1.3.0.jar com.bea.core.apache.log4j_1.2.13.jar com.bea.core.apache.regexp_1.0.0.0_1-4.jar com.bea.core.apache.xalan_2.7.0.jar com.bea.core.apache.xml.serializer_2.7.0.jar com.oracle.ws.orawsdl_1.4.0.0.jar commons-cli-1.1.jar commons-codec-1.4.jar commons-compress-1.5.jar commons-configuration-1.5.jar commons-dbcp-1.4.0.jar commons-discovery-0.4.jar commons-el.jar commons-fileupload-1.2.jar commons-httpclient-3.1.jar commons-io-1.4.jar commons-lang-2.3.jar commons-validator-1.3.1.jar cpld.jar css.jar cssimportexport.jar ctg.jar ctg_custom.jar dms.jar epml.jar epm_axis.jar epm_hfm_web.jar epm_j2se.jar epm_jrf.jar epm_lcm.jar epm_misc.jar epm_stellant.jar epm_thrift.jar essbaseplugin.jar essbasestudioplugin.jar ess_es_server.jar ess_japi.jar fm-actions.jar fm-adm-driver.jar fm-web-objectmodel.jar fmcommon.jar fmw_audit.jar glassfish.jstl_1.2.0.1.jar hssutil.jar |
httpcore-4.0.jar identitystore.jar identityutils.jar interop-sdk.jar jacc-spi.jar jakarta-commons.jar javax.activation_1.1.jar javax.mail_1.4.jar javax.security.jacc_1.0.0.0_1-1.jar jdom.jar jmxspi.jar jps-api.jar jps-common.jar jps-ee.jar jps-internal.jar jps-mbeans.jar jps-unsupported-api.jar jps-wls.jar js.jar json.jar jsr173_1.0_api.jar lcm-clu.jar lcmclient.jar LCMXMLBeans.jar ldapbp.jar ldapjclnt11.jar libthrift-0.9.0.jar log4j-1.2.14.jar lucene-analyzers-1.9.1.jar lucene-core-1.9.1.jar lucene-spellchecker-1.9.1.jar neethi-2.0.4.jar ojdbc6dms.jar ojdl.jar opencsv-1.8.jar oraclepki.jar org.apache.commons.beanutils_1.8.3.jar org.apache.commons.digester_1.8.jar org.apache.commons.logging_1.1.1.jar osdt_cert.jar osdt_core.jar osdt_xmlsec.jar quartz.jar registration_xmlBeans.jar registry-api.jar resolver.jar saaj.jar scheduler_ces.jar servlet-api.jar slf4j-api-1.5.8.jar slf4j-log4j12-1.5.8.jar sourceInfo.jar stax-api-1.0.1.jar wf_ces_utils.jar wf_eng_agent.jar wf_eng_api.jar wf_eng_server.jar wldb2.jar wlpool.jar wlsqlserver.jar wsplugin.jar xbean.jar xmlparserv2.jar xmlpublic.jar xmlrpc-2.0.1.jar XmlSchema-1.3.1.jar |
Table 3 - Required Jar Files
This article represents the expertise, findings, and opinion of the author. It has been published by Oracle in this space as part of a larger effort to encourage the exchange of such information within this Community, and to promote evaluation and commentary by peers. This article has not been reviewed by the relevant Oracle product team for compliance with Oracle's standards and practices, and its publication should not be interpreted as an endorsement by Oracle of the statements expressed therein.