Fault Handling and Prevention for Services in Oracle Service Bus
Guido Schmutz and Ronald van Luttikhuizen
Part two in a series on Fault Handling in a Service-Oriented Environment
- Part 1: Introduction to Fault Handling in a Service-Oriented Environment
- Part 2: Fault Handling and Prevention for Services in Oracle Service Bus
May 2013
Introduction
Part 1 of this article series on Fault Handling and Prevention discussed what fault handling is and why it is important. It also addressed the specific challenges in handling faults in a service-oriented landscape as compared to traditional systems. Part 1 concluded by presenting a sample scenario, an Order process implemented in a BPM and SOA environment, discussed potential pitfalls, and described generic fault prevention and recovery patterns.
Part 2 concentrates on concrete fault handling and prevention measures in the integration layer that are realized through Oracle Service Bus (OSB). The integration domain covers typical elements and integration functionality, such as Adapters for connectivity to back-end systems, Routing, Transformation, and Filtering.
Figure 1, below, revisits the scenario from Part 1. We are using the Trivadis integration architecture blueprint notation [1]. The left side shows the process steps in the Order process from the moment the order request is received until the order is processed. The right side shows all the external systems that the process interacts with to complete an order request. The middle lanes show the integration of the process with the back-end systems by exposing the back-end systems as services to the process using OSB.
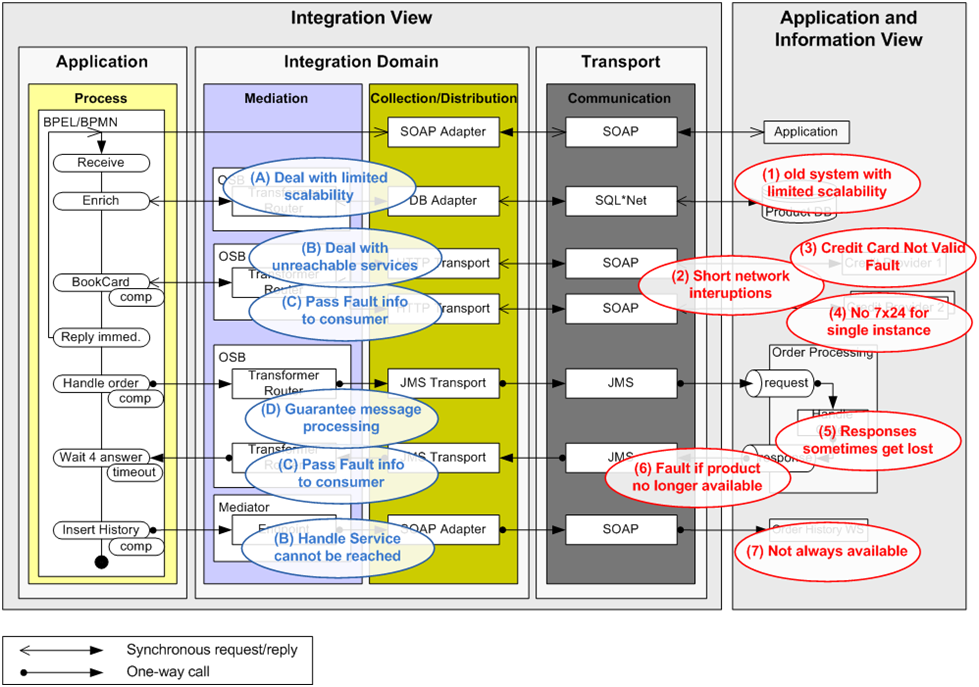
Figure 1: Possible fault situations and the accompanying fault handling and prevention measures in the Integration layer
- Deal with limited scalability - make sure that the existing and un-scalable Product Database is not overloaded (fault situation 1)
- Deal with unreachable services - handle situations where a given service is unreachable (fault situation 2, 4 and 7)
- Pass fault information to consumers - some of the faults in the back-end systems need to be transformed and passed to consumers because the integration domain cannot deal with them in an automatic way (fault situation 3 and 6)
- Guarantee message processing - make sure that a message is processed in an all-or-nothing fashion (fault situation 5)
The remainder of this section discusses the measures to prevent and handle these various fault situations and shows how these measures are realized through the Oracle Service Bus.
(A) Deal with limited scalability
The Product Database belongs to a legacy system that has limited scalability. We have to be careful not to overload the system with requests, otherwise the system might crash. Such a peak in requests can, for example, be caused by a seasonal increase of orders just before Christmas.
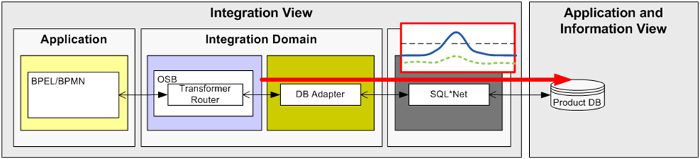
Figure 2: New consumers and/or more orders produce a higher load on the Product Database
Solution A1 - Add caching to minimize calls to external systems
Instead of calling the back-end system for each product request, you can store the result of a given request in a cache. The cache is then used to retrieve data that has already been requested when another request for the same information arrives.
Oracle Service Bus allows for declaratively adding a result cache on a Business Service. This way, every request on the Business Service first checks if the desired information is already in the cache (1). If so, the data is directly returned to the consumer. If not, the request is sent to the back-end system (2), the response is stored in the cache (3) and returned to the consumer.
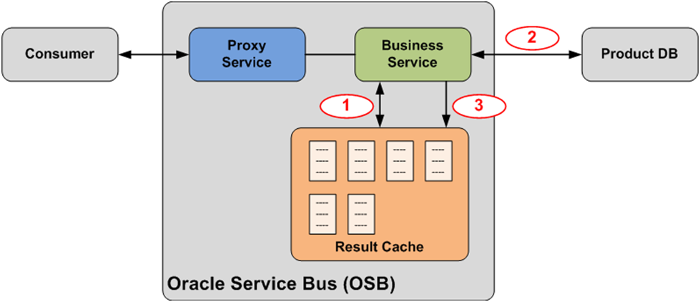
Figure 3: Result Caching for a Business Service
Result caching can be activated in the Advanced Settings of the Business Service configuration. Enabling the caching is as simple as selecting the Supported check box, specifying the value to be used for the cache token, and specifying the time after which the data in the cache will expire (Figure 4). The cache token acts as unique identifier to reference data elements and is configured using an XPath expression. In the Figure 4, below, the product code is specified as a unique identifier for product data that resides in the cache.
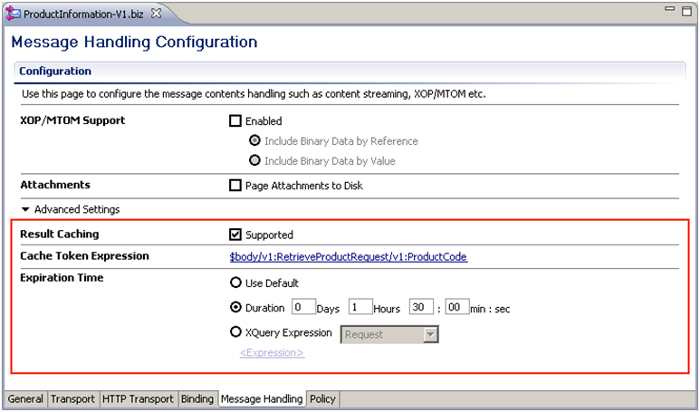
Figure 4: Configuration of Result Caching for an OSB Business Service
Behind the scenes Oracle Service Bus uses Oracle Coherence to implement the Result Cache. Note that the cache is managed entirely by OSB and cannot be accessed or updated from an API or the message processing logic of the OSB Proxy Service.
Fault action type:
- Alternative action (fault prevention)
Application and considerations:
- The data that is returned through the service operations and is cached should be read-only
- The data should be static. If data is not entirely static, it should be acceptable for a consumer to get results that are not always up to date.
- To increase the effectiveness of this solution, consider pre-populating the cache before the service consumers start hitting the back-end systems. As there is no external direct access to the cache, the only way to achieve this is by invoking the service once for each result (product) to be cached, for example, immediately after the OSB server has been started.
Impact:
- Adding caching will increase memory usage on the middle tier.
- " Once in the cache, the information is no longer synchronized with potential changes in the source, for example, when directly updating the underlying database.
Alternative implementations:
- For RESTful services a Web Cache can be used, although OSB result caching works for all transports, including the HTTP transport used for RESTful service calls.
- To reduce additional memory consumption, a NoSQL database could be used to store results on disk instead of in memory. Especially for large datasets, where the cache won't fit into memory, this could be interesting. Unfortunately, there is no way to replace the out-of-the-box result caching store (Oracle Coherence) with something else. Therefore we would have to implement our own caching service (for example, in Java, accessing the NoSQL data store) and call it either through a Java Callout or Service Callout action. Such a NoSQL database cache could also support non-static data, where a modification in the original source would automatically trigger an update in the NoSQL data store as well.
Solution A2 - Throttle requests before they are sent to back-end systems
Caching might not be feasible since the requested data is dynamic. Even when you apply caching (A1) there still might be too many request messages for the Product Database to handle. For example, this could happen when a lot of different products that have not been previously ordered (so they are not yet in the result cache) are ordered at the same time. To avoid crashing the back-end system, you can limit the number of simultaneous requests that are sent to back-end systems by buffering them.
You can use Oracle Service Bus to control, or throttle, the message flow between Proxy and Business Services using a Throttling Queue. This is basically an in-memory queue that holds requests during a peak load and effectively limits the number of concurrent requests sent to the back-end system.

Figure 5: Configuring a Throttling Queue for a Business Service
Figure 5: Configuring a Throttling Queue for a Business Service Throttling is an operational task and can therefore only be added through the OSB Console. It's not available in the development environment when working with the Oracle Enterprise Pack for Eclipse (OEPE). Figure 6 illustrates the configuration of Throttling using the console.
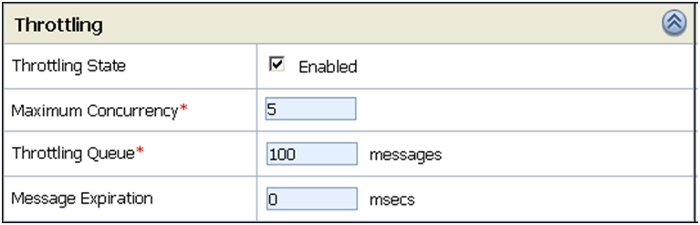
Figure 6: Configuring a Throttling Queue for a Business Service
In this case the throttling queue is configured to hold a maximum of 100 messages. The concurrency is limited to 5, meaning that only 5 messages are allowed to be sent to the Product Database at the same time. Additional messages are buffered in the queue and submitted when the concurrency decreases to less than the maximum. The message expiration attribute is used to configure the maximum time that a message is stored in the queue. When buffered messages expire, a fault is returned to the service consumer. A message expiration of 0 means that messages in the throttling queue will not expire.
Fault action type:
- Throttling (fault prevention)
Application and considerations:
- Works best if an asynchronous request-response or a one-way message exchange pattern is used. In a synchronous request-response pattern, a timeout on the consumer side occurs in case request throttling takes longer than the synchronous timeout value.
- The throttling queue is not persistent. For example, requests in the throttling queue are lost if the OSB server goes down.
Impact:
- In the event that messages are throttled, it might take longer for a synchronous request to return its response. This could mean that some of the service level agreements (SLA) defined for the service are violated, or, in the worst case, a timeout occurs.
Alternative implementations:
- Use Oracle WebLogic JMS server to implement custom throttling based on persistent queues. In this scenario you need to control the number of concurrent threads consuming the messages from the queue. For OSB this can be done by specifying a Dispatch Policy on a Proxy Service. The downside of this approach is that boilerplate coding is necessary instead of configuration.
(B) Deal with unreachable services
When communicating with external systems, aspects that are beyond your control can interfere with the stability of a given service. For example, a network connection might not be as reliable as the service itself, resulting in connectivity issues. As long as these interruptions are temporary (a few seconds or less), we might be able to handle the fault in the integration layer by resending the request, or by using another runtime instance of the service. In these cases the consumer might not even recognize that a problem has occurred.
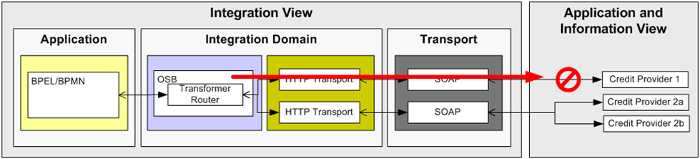
Figure 7: Network interruption when trying to reach instance 1 of the Credit Service
Solution B1 - Use the retry mechanism to resend faulted requests
Instead of passing a technical fault to the service consumer indicating the service is unavailable, the integration layer can handle the error by retrying the faulted request multiple times. If the original fault occurred because of a short network interruption, chances are that a second or third try will be successful. If the retry period is long enough, we might even be able to wait until a service is restarted in case a failure of the service instance was the reason and an automatic service restart procedure is in place.
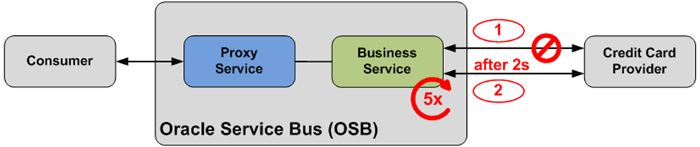
Figure 8: Retry behavior of a Business Service
Oracle Service Bus allows you to define the retry behavior of a Business Service. This is completely transparent to the Proxy Service that invokes the Business Service. The Proxy Service still needs to be prepared to handle or pass the fault in case the total number of retries has been reached without successful invocation of the service.
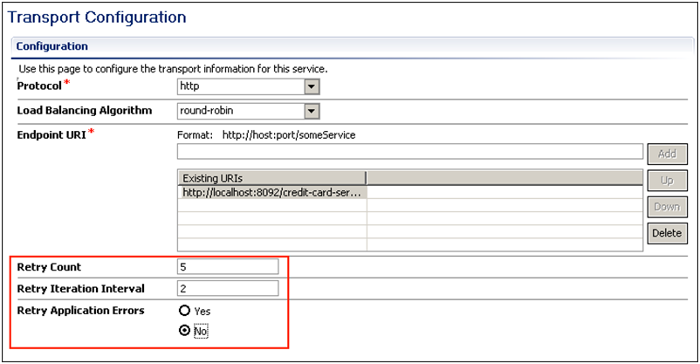
Figure 9: Configuring the Retry behavior on the Transport Configuration of a Business Service
The retry behavior is configured on the Transport Configuration of the Business Service (Figure 9). We can configure the number of retries (Retry Count), the time to wait in between the retries (Retry Iteration Interval), and indicate whether Application Errors should be retried. Since application errors usually indicate (functional) faults in the back-end systems, retrying application errors often won't solve the underlying issue.
Fault action type:
- Retry (fault prevention)
Application and considerations:
- The invoked service should be idempotent, meaning that multiple calls with the same input will yield the same result and not cause side-effects such as duplicate data.
Impact:
- If the configured retry behavior kicks in, it might take longer for a service to return a response. This could result in the failure to meet some SLAs.
- Service consumers still need to handle an error if the fault still occurs after the configured number of retries is exhausted and the fault is passed back to the consumer.
Alternative implementations:
- In Oracle SOA Suite similar retry functionality can be configured in components, such as the Mediator, by using the Fault Policy Framework.
- Service consumers can be left to handle the problem by omitting the addition of retry functionality, thus returning the fault the first time it occurs. This is a bad practice since a service should be autonomous, robust, and self-contained.
Solution B2 - Use load-balancing and invoke another service instance in case of failures
The service itself could be down due to a fault situation (e.g. the service crashed) or planned maintenance. Because such situations can be foreseen the service provider could provision multiple instances of the same service. In such a scenario the service consumer can invoke another, still active service instance. Depending on the cause of the original service failure, this new instance can run anywhere: on a separate machine, on the same machine as the original instance, or in a different virtualized environment.
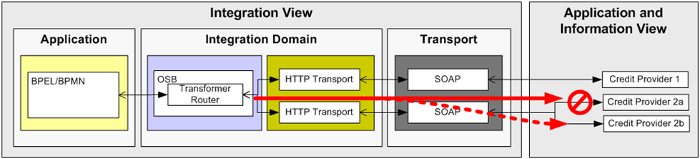
Figure 10: Configuring Service Pooling for a Business Service
You can define a pool of service endpoints for a given Business Service in Oracle Service Bus. If OSB detects an error on one of the endpoints, it will retry the request on a different instance of the service. The service pool can be configured in the following ways:
- For simple failover: all requests are sent to one single instance and only if this instance crashes are requests send to the second instance;
- To provide load-balancing: all of the available services are used in a round-robin or random fashion.
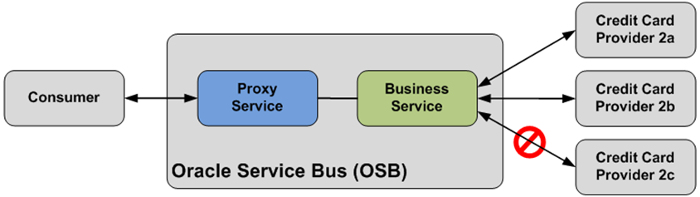
Figure 11: Service Pooling behavior of a Business Service
OSB has the capability to mark a service endpoint as offline in case of an error. This way service requests will no longer be sent to the faulted endpoint. An offline endpoint can be brought online automatically after a given time interval, or manually through the OSB console or through JMX.
The use of service pooling is completely transparent to the Proxy Service invoking the Business Service.
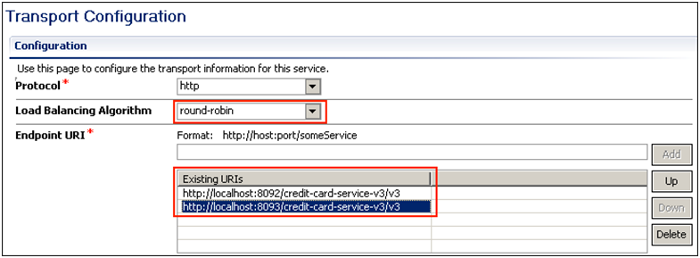
Figure 12: Configuring Service Pooling on the Transport Configuration of a Business Service
Service pooling is configured on the Transport Configuration of the Business Service (Figure 12). Here you can configure the load balancing strategy to be used (Load Balancing Algorithm) and the various service endpoints that will be used to invoke the service instances (Endpoint URI). Service pooling works for all protocols that OSB supports (HTTP is used in Figure 12).
Fault action type:
- Share the load (fault prevention)
Application and consideration:
- Can only be used if the service provider provisions multiple instances of the same service.
Impact:
- It might take longer for a request to return its response when the request initially is routed to a service instance that is no longer available. This also means that some of the SLAs defined for the service might be violated
- A consumer still needs to handle an error if all service instances fail.
Alternative implementations:
- Use an existing hardware or software load-balancer to front the multiple service instances offered by the service provider. A load-balancer might be restricted to HTTP traffic, whereas OSB can pool service requests on any transport it supports.
- Provision the services in a clustered environment, for example, an Oracle WebLogic cluster. This also uses the load balancing measure, but applied on cluster level, transparent to Oracle Service Bus. Note that not all service implementations allow for running on a cluster or a clustered environment.
(C) Pass fault information to consumers
As described in the first article in this series, there is a difference between business and technical faults. This differentiation can be used in the integration layer to separate errors that can be re-tried from those that can't.
A temporary network failure is an example of a technical fault that can be retried. A re-try of the request a few seconds later might be enough to recover from such a fault. This is the situation described in Solution B1 - Use retry mechanism to send the same request multiple times. In case of a business fault, such as a Credit Card Not Valid Fault, there is no point in retrying the request an instant later -- the card will still be invalid. We cannot prevent or handle such faults in the service itself. We need to inform the service consumer about this fault situation, in this case the Order business process. Handling such errors in the process layer will be covered in the third article in this series.
So we need a mechanism to pass the faults that can't be re-tried back to the service consumer. The original fault can be passed through the integration layer as is, or it can be transformed into another fault message that is agreed upon in the service interface.
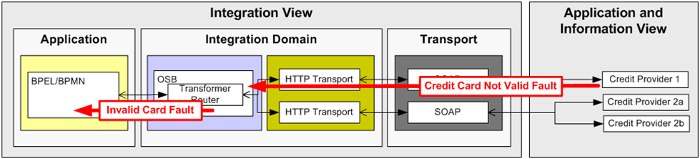
Figure 13: Pass the Credit Card Not Valid Fault to the consumer
How the fault is passed to the consumer depends on the protocol being used. With SOAP-based Web Services you can declare and return a Fault message if a synchronous request/response message exchange pattern is used. If we use asynchronous communications, a fault has to be returned as a normal callback message.
In case of RESTful Web Services a fault situation should be signaled using the HTTP status code, with the message holding more information about the error.
Solution C1 - Returning a fault message
The first solution involves returning fault messages to the service consumer with all the necessary information. The consumer is then responsible for deciding how to handle the fault. This solution discusses both synchronous and asynchronous cases.
In a synchronous Web Service operation, functional fault messages should be declared in the interface definition (WSDL). Oracle Service Bus uses the concept of error handlers, like any modern programming language, for handling fault situations, such as a fault message returned from a service invocation or a problem in the message flow of a Proxy Service. Figure 14 illustrates:
- The Credit Card Not Valid Fault from the service implementation (Credit Card Provider) is caught by an error handler in OSB
- The fault is then transformed into a functional fault that is specified in the service WSDL, and then returned to the consumer, as indicated by the red lines in Figure 14.
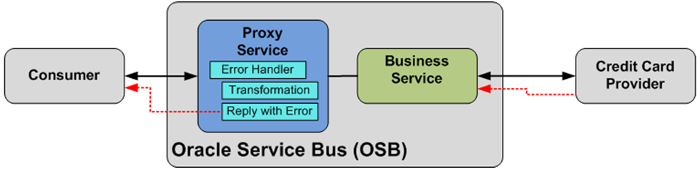
Figure 14: Fault Handling on the OSB Proxy Service showing the optional transformation into another fault message
Figure 15 shows how the Error Handler is graphically modeled in the message flow designer of the Proxy Service. In this case an Assign action is used to transform the back-end fault into the fault message declared in the service interface. The fault is then returned to the service consumer by a Reply action.
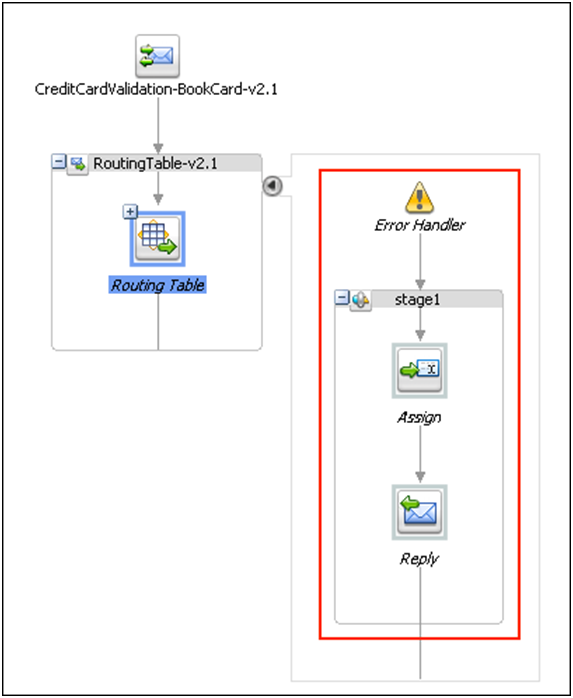
Figure 15: Fault Handling in the message flow of an OSB Proxy Service including returning it to the service consumer using a Reply activity
On the Reply action it is important to specify the With Failure option, so that the consumer waiting for the response receives the message as a failure and not as a successful response.

Figure 16: Reply with Failure to signal the consumer of the OSB service of the fault situation
If an asynchronous request/response message exchange pattern is used in a SOAP-based Web service, a fault is specified as an additional callback message. Technically, there is no difference between a "normal" callback message signaling a successful result, and a fault callback.
In our sample case, the Product No Longer Available fault is returned asynchronously because the service operation is asynchronous. Since it makes no sense to retry in this fault situation, we have to pass the fault on to the consumer (the Order process), which will handle it and execute the necessary actions. The third article in this series will address how to do that.
Figure 17 shows an asynchronous message exchange between service consumer and OSB, and between OSB and the Order Processing System. Since those exchanges involve two exchanges (request and callback), two pairs of Proxy and Business Services are used. The back-end Order Processing system publishes both successful responses and fault messages to the same response queue. The OSB Proxy Service that listens to the response queue differentiates between successful responses and fault messages.
In such a case the Proxy Service might first throw an internal error so that an Error Handler can be used to transform the information into a proper fault message and returned to the consumer as a fault callback message. This is shown by the red line in Figure 17.
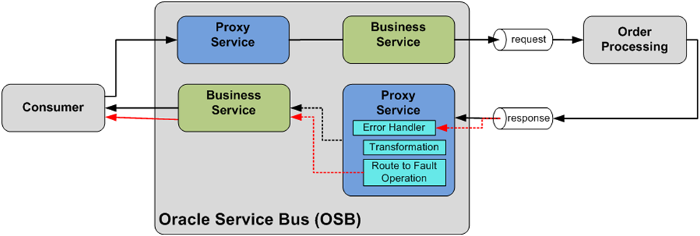
Figure 17: Returning an asynchronous fault message to the service consumer
The interface that is agreed upon between the service consumer and service provider (OSB in this case) defines the functional faults that can be expected. If the fault callback message is defined in the same interface as the standard callback message, the fault can be returned to the consumer through the same Business Service. Otherwise, you need to add an additional Business Service.
The fault situation could also be signaled to a service consumer using a normal response message instead of a separately defined message fault, but that practice is not recommended.
If the Order Processing system returns different messages for fault responses than for successful responses, two Proxy Services might be used. Each service would act as a selective consumer on the queue, one consuming only the successful messages and the other consuming only the fault messages. The fault message returned to the consumer can again be sent through the same Business Service or through an extra Business Service, if the fault message is declared in a different interface (Figure 18).
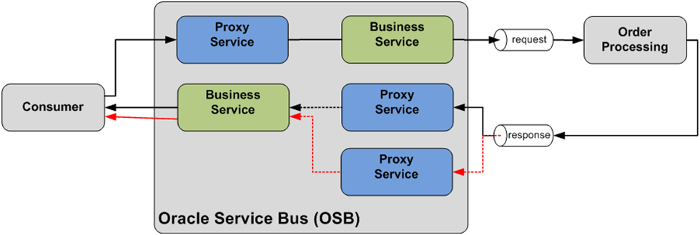
Figure 18: Returning an asynchronous fault message to the consumer using a second Proxy Service that consumes the fault messages from the Order Processing system
If the Order Processing system separates faults from successful results by using different response queues, a similar setup as shown earlier can be used. You'd still have two Proxy Services: one consuming the successful responses and the other one consuming the fault responses, as shown in Figure 19.
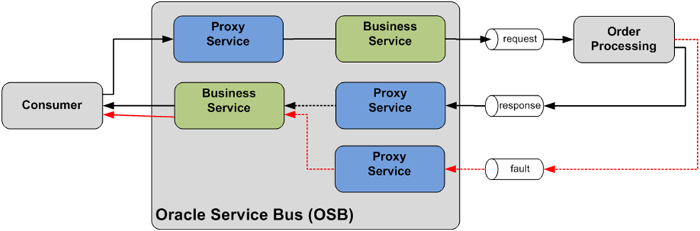
Figure 19: Returning an asynchronous fault message to the consumer using a second Proxy Service that consumes fault messages from a dedicated fault queue
These different implementations of Solution C1 - Returning a fault message have one thing in common. They assume that the consumer, who sent the request, is still waiting for a response. This is natural in a synchronous request/response interaction in which the consumer has to wait for the answer. In an asynchronous scenario, however, the request might have been sent minutes, days, or even weeks before the answer is known. The consumer might long have been gone and there is no point in sending a fault as a callback message. In this case Solution C2 - Storing fault in a persistent store might be used instead. However, in our scenario, the consumer is the BPEL process, which will wait until a callback message is received (either the successful or the fault message). That process, too, will be addressed in the third article in this series.
Fault action type:
- Balk (fault handling)
- Appeal to higher authority (fault handling)
- Exception shielding (fault handling)
Application and considerations:
- In a synchronous scenario we have a blocking call, and the consumer has to wait for either the positive response or the negative (fault) message.
- In an asynchronous scenario the original consumer or another consumer (acting on behalf of the original consumer) must be ready to accept the fault message.
- Only faults that can't be re-tried should be directly returned to the consumer. If an error can be re-tried, a better strategy would be to use retry mechanisms first, returning a fault message only if the number of retry attempts has been reached.
Impact:
- A fault message returned by the service provider delegates the responsibility for handling the fault to the service consumer. The service provider is released from the responsibility to prevent or handle the fault.
- In a synchronous scenario, on the consumer side, a fault message is usually automatically converted into an exception, so that the consumer is forced to handle the exception by implementing an exception handler.
- In an asynchronous scenario, a fault message is just another callback message, one that the service consumer must be prepared to accept. In contrast to the synchronous message exchange, a fault message is not converted automatically into an exception. So it's often best to convert it immediately into an exception and throw it, so that the exception handling logic can be kept separate from the happy flow.
A best practice is to always signal errors to service consumers by designing good interfaces and using the fault messages available in the service definition (WSDL) of a SOAP-based Web Service, instead of using custom error codes in "normal" response messages. This way an error is caught automatically by a fault handler on the consuming side using error handling constructs available in any modern programming language as well as on the service infrastructure level, such as OSB.
Solution C2 - Storing faults in a persistent store
In an asynchronous scenario the consumer sending the initial request may no longer be available, or may no longer be interested in the fault message. Often the only alternative in such a scenario is to store the fault in a persistent store (error hospital) to be (manually) handled later.
Figure 20 shows fault messages being stored in a database by invoking a separate Business Service using a DB adapter.
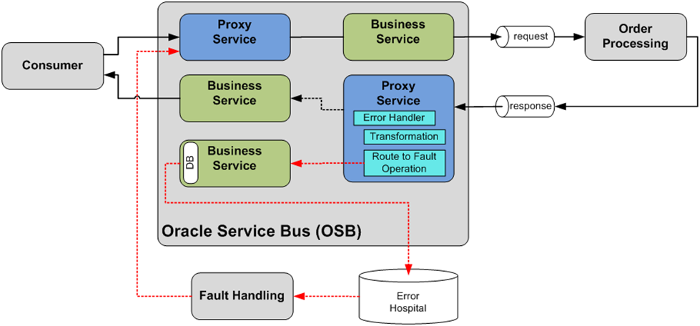
Figure 20: Fault Handling in an asynchronous message exchange by using a Proxy Service to send fault messages to a persistent store (Error Hospital)
Fault handling in an Error Hospital mostly involves errors that require manual activities to resubmit at a later time. Somebody has to analyze the fault situation and decide what should happen with the faulted message. Can the situation be fixed by re-submitting the message? By changing the message payload? Or should the message be dropped completely, resulting in having to inform the consumer that his order cannot be processed? One strategy is to use the Human Task service, which is available in Oracle SOA Suite.
An Error Hospital typically contains a persistent store that is often transactional, such as a database table or JMS queue. A database table might offer an advantage when resubmitting faulted messages, because it allows the desired fault messages to be easily retrieved and placed in the appropriate order(SQL SELECT), probably arranged in the order of occurrence. The fault handling logic might want to feed the (corrected) messages back into the processing logic by calling the same Proxy Service as the consumer.
Fault action type:
- Balk (fault handling)
- Appeal to higher authority (fault handling)
- Exception shielding (fault handling)
- Recovery/alternative (fault prevention)
- Resign (fault handling)
- Guarded suspension (fault handling)
Application and considerations:
- Works best in an asynchronous message exchange pattern
- Should only be used for technical errors that cannot be re-tried, and not for business errors. Business errors are best handled by the business process (service consumer) itself
Impact:
- Some additional human intervention is necessary
- Availability of an Error Hospital
Alternative implementations:
- Enable the service consumers to receive fault callback messages
- Let the service consumers discover that there was (probably) a fault situation on the provider side, for example, because a successful callback message never arrives on the consumer side, which would trigger a timeout event.
(D) Guarantee message processing
The integration between OSB and Order Processing back-end system is done asynchronously through two queues. One rationale could be a desire for additional decoupling so that orders can still be accepted even if the back-end system is unavailable. Another rationale could be because limitations in the legacy-type of the system don't allow for direct linking with external systems.
As shown in Figure 21, the asynchronous nature of the integration between the business process and the Order Processing system adds the danger of losing messages. Errors during message handling can occur in the external system or in the integration layer, for example, if a message transformation fails because of an invalid request message or if a callback message cannot be delivered to the consumer.
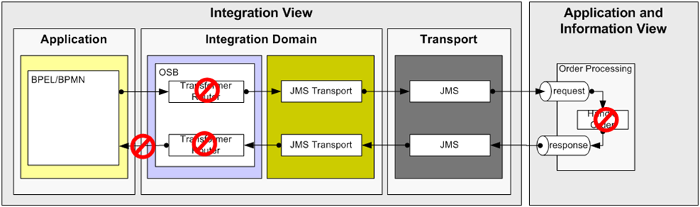
Figure 21: Integrating with the Order Processing back-end system and possible risks of loosing messages
In all these cases we have to guarantee that under no circumstances will we ever lose a message.
Solution D1 - Include message processing in a distributed transaction
One way to achieve reliable messaging is by making sure that the message processing logic is executed in an active transaction, and that the message to be processed is retrieved from a transactional resource and stored in a transactional resource after the message has been processed. If the processing is successful, the transaction ends successfully. If an error occurs, the transaction is rolled back. In that way we can separate the processing into discrete, independent steps, each one working in an-all-or-nothing fashion. The active transaction has to be a distributed transaction, because multiple resources—such as the JMS server and the BPEL process manager with its database persistence (dehydration store)—are involved. This means that you can only use transactional resources as source and target systems.
In our case the source and target systems of the message processing logic are either the BPEL process manager or the JMS queues, so we only deal with transactional resources. As shown in Figure 22, we can split the processing logic into three separate distributed transactions:
- T1: this transaction is started in the BPEL process itself and ends with the enqueue operation on the request queue.
- T2: this transaction is started and ended by the Order Processing system itself.
- T3: this transaction is started by OSB with the dequeue operation on the response queue and ended by the BPEL process after receiving the callback message.
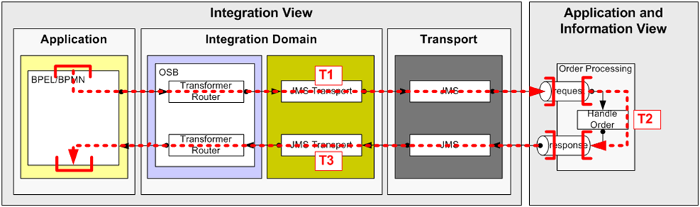
Figure 22: Using three distributed transactions for the asynchronous message flow to and from the Order Processing system
With that setup, we ensure that the BPEL process passes its active transaction context to the OSB, so that the message flow of the request message is executed in the same transaction as BPEL. If no error occurs, the transaction will end with a new message in the request queue. After that, the back-end system consumes the message in a new transaction and executes its message processing logic. If successful, the transaction will end with a message in the response queue. In the third transaction, the response processing mes
sage flow on OSB consumes the message from the request queue, processes it, and sends the callback message to the BPEL process, passing the active transaction context so that the BPEL process will continue and reuse this third transaction until it reaches the next dehydration point and the transaction is committed. By using the right transaction boundaries we can make sure that messages don't get lost.
For inbound messages Oracle Service Bus can either start a new transaction or participate in an already active distributed transaction. This is as simple as setting an option on the Proxy Service. The same is true for outbound messages using the configuration of the Business Service. Figure 23 shows the setup for this case on Oracle Service Bus.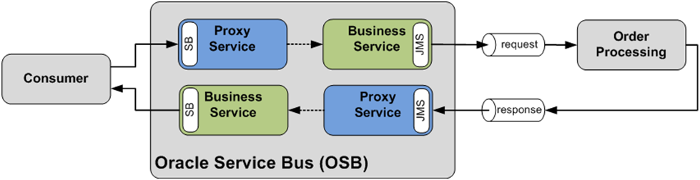
Figure 23: Using the Service Bus and JMS transports to participate in distributed transactions
Using the Service Bus (SB) protocol from and to the service consumer (this is the BPEL process running on Oracle SOA Suite) we can guarantee that the transaction context is propagated from BPEL to OSB for the request processing and from OSB back to BPEL for the response processing. On the BPEL side, a SOA-direct binding has to be used, which we will discuss in third article in this series. This mechanism to participate in global transactions isn't possible for all transports - when using SOAP, for example.
An important consideration is where to place the two queues. For fault prevention reasons, the queues should at least be as reliable and available as the integration layer itself, i.e. OSB. Only then can we guarantee that OSB is able to write to the queues, even if the Order Processing system is unavailable. If the queues are less available you have to worry about not being able to write a message to the request queue. The easiest way to reach the same availability is to place the queues on the same Oracle WebLogic Server as the one on which OSB is running. Oracle WebLogic JMS is a very reliable JMS server and is therefore a good choice.
In case external systems cannot be integrated with Oracle WebLogic JMS, or the system already provides its own queuing service,OSB might have to integrate with external queues residing on the Order Processing system.
Fault action type:
- Provisional action (fault prevention): the message in the queue will only be visible when the message processing is complete
- Guarded suspension (fault handling): if the queues are on a more reliable server than the backend systems
- Throttling (fault prevention): if the request queue acts as a buffer
Application and consideration:
- Only works with transactional resources that can participate in XA transactions
- Try to place the queues on a system that has at least the same availability as Oracle Service Bus, e.g. Oracle WebLogic JMS on the same server
Impact:
- A transaction on a single resource might take a bit longer than the same activity executed in a non-distributed transaction.
- A distributed transaction is more expensive than a non-distributed transaction in terms of computing resources.
Alternative implementations:
- Web Service Reliable Messaging (WS-RM), if supported by the infrastructure and all the participating services
- Use a database table instead of the queues in the setup above and replace the JMS transport with DB adapters. However, this requires more boiler-plate coding.
This concludes the fault prevention and handling measures that we implemented in OSB to cover the different fault situations in the integration layer. In the next article of this series you will learn what you can do on the process layer in Oracle SOA Suite to handle and prevent the possible fault situations of our sample scenario.
Sources
- Service Oriented Architecture: An Integration Blueprint, by Guido Schmutz, Peter Welkenbach, Daniel Liebhart (Packt Publishing 2010)
- Trivadis Integration Architecture Blueprint by Guido Schmutz
About the Authors
Guido Schmutz is Technology Manager for SOA and Emerging Trends at Trivadis and an Oracle ACE Director.
Ronald van Luttikhuizen is Managing Partner and Architect at Vennster and an Oracle ACE Director.