Oracle Machine Learning for Spark
Oracle Machine Learning for Spark is supported by Oracle R Advanced Analytics for Hadoop and provides massively scalable machine learning algorithms via an R API for Spark and Hadoop environments for data scientists and application developers to build and deploy machine learning models.
Oracle Machine Learning for Spark
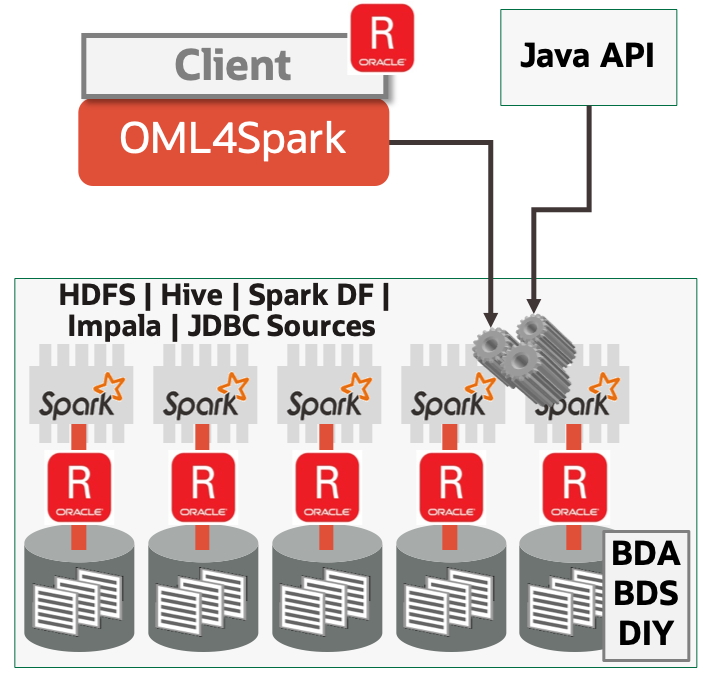
OML4Spark R API provides functions for manipulating data stored in a local File System, HDFS, HIVE, Spark DataFrames, Impala, Oracle Database, and other JDBC sources. OML4Spark takes advantage of all the nodes of a Hadoop cluster for scalable, high performance machine learning modeling in Big Data environments. OML4Spark machine learning algorithms use the expressive R formula object optimized for Spark parallel execution.
OML4Spark brings custom Linear Model (LM), Generalized Linear Model (GLM), and MLP Neural Networks algorithms that execute on Spark infrastructure. OML4Spark provides interfaces to Apache SparkML algorithms, but note that OML4Spark algorithms scale and perform better than SparkML. R functions wrap SparkML algorithms within the OML4Spark framework using the R formula specification and Distributed Model Matrix data structure.
Oracle Cloud SQL and OML4Spark can be combined from Oracle Database or Autonomous Database to address large, complex data-driven problems where the source data and patterns to be discovered may lie in big data, relational data, or some combination of the two. OML4Spark provides options for machine learning processing outside the database or as a powerful component of larger, complex machine learning pipelines.
Product Details
Open all Close allFeatures Overview
- Use scalable and distributed machine learning algorithms, data preparation, data exploration, and statistical analysis from a natural R API
- Parallel and distributed machine learning algorithms that leverage all the nodes of a Hadoop cluster for scalable, high performance modeling on big data
- Custom Spark-based Linear Model, Generalized Linear Model, and MLP Neural Network algorithms
- Interfaces to Apache SparkML that use the R formula and Distributed Model Matrix infrastructure
- Functions that make use of the expressive R formula object optimized for parallel Spark execution
- Store models and results in HDFS or File System to load and execute in other Big Data clusters, like production
Business Benefits
- Use a Big Data Cluster as a high performance compute environment through an R interface
- Make use of HIVE, Impala and SparkSQL to process large datasets from a simplified R API
- Minimize data movement
- Use R packages contributed by the R community
- Integrate data from Oracle Database via OCI and other environments via JDBC
Core Features
Transparency layer - Leverage R data.frame proxy objects so data remains as HIVE/Impala tables and views. Overloaded R functions translate select R functionality to equivalent SQL for processing in the cluster, taking advantage of parallelism, scalability and security. Data scientists can use familiar R syntax to manipulate database data that remains in the cluster.
Machine Learning Algorithms - R users can take advantage of Oracle Machine Learning for Spark library of parallel distributed algorithms using the R language, in addition to select Spark ML algorithms. Users can specify machine learning models using the familiar R formula syntax. Algorithms support classification, regression, clustering and feature extraction.
Spark Data Frame manipulation - Manage and invoke special functions (including SQL) directly on the Spark Data Frame proxy objects in R, for execution in the cluster. From random sampling and data splits to data listing and printing, the interface offers unique capabilities to manipulate, create and push/pull data into Spark.
Additional Features
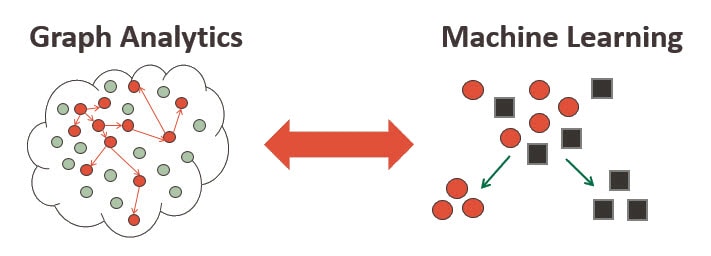
OAAgraph - For those interested in leveraging the powerful graph analytics present in Oracle Spatial and Graph, Oracle Machine Learning for Spark is compatible with the package OAAgraph that eases working with both Spark-based machine learning algorithms and the Parallel Graph AnalytiX (PGX) engine. Prepare your data using R in Oracle Machine Learning for Spark, build models and score data to augment graph data and analysis, and compute graph metrics to augment data provided to Spark machine learning algorithms, all with the goal to boost model quality and graph analytics.
What's New in Oracle Machine Learning for Spark
Tutorial and Demo on OML4Spark

BOOK: Using R to Unlock the Value of Big Data (PDF)

Bringing R to the Enterprise (PDF)
Documentation
Release 2.8.2
- Installation Guide for ORAAH 2.8.2 (PDF)
- Change List for ORAAH version 2.8.2 (PDF)
- Reference Documentation for ORAAH version 2.8.2 (PDF)
- Release Notes for ORAAH version 2.8.2 (PDF)
- ORAAH R Formula engine and data preprocessing version 2.8.2 (PDF)
- HIVE and Impala support details and connectivity for ORAAH version 2.8.2 (PDF)