Monitoring Performance Using the WebLogic Diagnostics Framework
A quick tour of your options for gathering server and application performance data from Oracle WebLogic Server
By Mike Cico
Published August 2009
The WebLogic Diagnostics Framework (WLDF) is a suite of services and APIs designed to provide the ability to collect and surface metrics that provide visibility into server and application performance. WLDF was first released in WebLogic Server version 9.0, and in the releases since we then have been continuing to add value to its features in line with these themes.
While WLDF has a large number of features, in this article you will explore a subset of those features geared at using WLDF to instrument an application and monitor its performance. If you are looking for more of a general introduction to WLDF, you can find a nice introduction to the WLDF feature set in this article by Rebecca Sly. At the end of this article you will find references to that and other articles, to other documentation of interest on WLDF, as well as links to all sample code and scripts used in this article.
Demonstration Use Cases
In this article, we will explore using WLDF services for performing the following monitoring activities.
- Monitoring for SLA violations
- Monitoring CPU load
- Graphing method and MBean data
- Finding bottleneck methods
In doing so, you will learn:
- How to configure WLDF and your application to utilize WLDF services
- How to use WLST (WebLogic Scripting Tool) and the WLDF Runtime MBean API for extracting and using the data generated by WLDF
- How to use the WLDF Dashboard console extension to visualize diagnostic data
WLDF Features Involved
The tasks outlined above will primarily involve using the following WLDF features
- Instrumentation framework. The Instrumentation subsystem is an implementation of an AOP (Aspect Oriented Programming) system that can be used to declaratively instrument server and application classes at the bytecode level with diagnostic code, or "monitors" in WLDF parlance. These monitors can be dynamically enabled or disabled, and can be configured with one or more actions to take when triggered. These actions are by design a closed set, and can range from simple trace events when a joinpoint is exercised, to tracing the elapsed time of execution around a joinpoint, to capturing method invocation statistics in memory.
- Watches and Notifications framework. The Watch & Notifications (W&N) system consumes data generated by other parts of WLDF (MBean data through the Harvester, as well as data from Instrumentation and/or Log events) and applies configured rules against that data. If a rule evaluates to true, W&N can generate a notification over SNMP, SMTP, JMX, JMS, or any combination therein.
- WLDF Archive. The Archive is a logical entity containing the generated diagnostic data, consisting of log files, collected MBean metrics, and generated instrumentation events. It maintains the history of server and application performance.
- WLDF Dashboard console extension. The WLDF Dashboard is a WLS Console extension Applet that provides the ability to build custom collections of charts to graph both WLS RuntimeMBean and WLDF Instrumentation data.
In addition, WLST is used to set up our examples, and in some of the demonstrations. WLST is a Jython-based scripting environment that can be used to configure a WLS domain and interact with its runtime MBeans. You can find out more about WLST here.
MedRec Setup
The MedRec sample application will also be used as our test application. You can use the the MedRec sample application that ships with the Oracle WebLogic Server distribution out-of-the-box, or use the ConfigurationWizard to create your own standalone MedRec domain. Both the out-of-the-box application and the MedRec Configuration Wizard template default settings include a sample WLDF configuration.
In this article, I have created my own MedRec domain using the WLS Configuration Wizard with the MedRec domain extension JAR. For details on how to configure your own MedRec domain, you can find documentation on the Configuration Wizard here, configuring a base domain here, and on extending a base domain here. The MedRec extension template is documented here. If you choose to use the extension template and create your own MedRec domain, just accept all the default options when installing the MedRec application extension template to a base domain.Monitoring Application SLA Violations
In this use case, an administrator needs to be notified when an application is in violation of a hard SLA requirement. Typically this would require hard-coded or third-party solutions to monitor the application response times. However, utilizing WLDF Instrumentation and the W&N framework, we can automatically trigger a notification when a violation occurs, without extra programming.
We will configure a Watch rule to send an SNMP alert whenever a MedRec Servlet does not respond within 1 ms. While this is an unrealistically low threshold, it will provide an effective demonstration of this capability. When the Watch rule triggers, it will transmit an SNMP notification to any listening trap monitors.
This will require:
- Configuring the Watch rule
- Configuring an SNMP notification and assigning it to the new rule
- Enabling the SNMP agent and configuring an SNMP Trap Destination.
Configuring the SLA Watch
The MedRec WLDF configuration comes with a deployed Servlet_Around_Service instrumentation monitor, which is configured to record the elapsed time in nanoseconds for any invoked Servlet or JSP when the IP address of the client is "localhost". This leverages the WLDF "dye filtering" capability, where instrumentation monitors can be configured to only fire when certain properties of a request match configured properties on the WLDF DyeInjection monitor. Therefore, for the purposes of our demonstration when invoking the MedRec application we will be using the "localhost" address to connect to the MedRec server with the browser.
cd ("edit:/WLDFSystemResources/"+wldfResourceName+"/WLDFResource/"+
\ wldfResourceName+"/WatchNotification/"+ wldfResourceName) startEdit() cmo.setEnabled(1);
#Set a watch on the Average CPU load using the JRockitRuntimeMBean
#and configure it with an SNMP notification
#SNMP notification snmp_notif = cmo.createSNMPNotification ("demoSNMP")
slaWatch =cmo.createWatch ("MedRec SLA")
slaWatch.setRuleType ("EventDatat")
slaWatch.setEnabled(1)
slaWatch.setRuleExpression(\"MONITOR = 'Servlet_Around_Service' AND MODULE = 'medrec' " +
\"AND TYPE LIKE 'TraceElapsedTimeAction-After%' AND PAYLOAD > 1000000")
slaWatch.addNotification(snmp_notif) slaWatch.setAlarmType("None")
Listing 1 Configuring the MedRec SLA Watch using WLST
Listing 1 contains a snippet of a WLST script used to create the Watch "SLA Watch" on the Servlet_Around_Service monitor bundled with the MedRec application. This Watch will examine generated instrumentation events and trigger when the payload value in the event from Servlet_Around_Service monitor in the medrec application indicates a value above 1 ms.
When triggered, an SNMP trap will be generated containing the Watch that was triggered, the rule it was configured with, and the data that caused it to trigger.
Configuring SNMP and Starting an SNMP Trap Monitor
Before we can see the SNMP notifications in action, we must first
- Enable an SNMP agent (in this case, the domain-wide SNMP agent)
- Configure an SNMP Trap Destination on the SNMP Agent
- Run an SNMP trap monitor on same port as configured for the trap destination.
The MedRec administration server has a domain-wide SNMP Agent configured in a disabled state. As part of our setup, we will run a WLST script that configures the domain-wide agent and then creates an SNMP Trap Destination on port 4000. This will allow the SNMP agent to send SNMP traps to a trap receiver listening on port 4000.
The WLST functions shown in the following figures are used in the script used to setup the W&N examples for this article. The steps in these functions can also be performed using the WLS Console.
###########################################################################
# Enable or disable the domain-wide SNMP agent.
#
# Params:
# enable Boolean that will enable or disable the agent (default is true)
#
# return Returns the agent instance to the caller
###########################################################################
def enableDomainSNMPAgent(enable=Boolean.TRUE):
agent = None
currentDrive=currentTree()
try:
cd ("edit:/")
agent = cmo.getSNMPAgent()
if not cmgr.isEditor():
startEdit()
agent.setEnabled(enable)
save()
activate()
finally:
if cmgr.isEditor():
stopEdit("y")
currentDrive()
return agent
Listing 2 WLST helper function that enables the domain-wide SNMP agent
###########################################################################
# Enable or disable the domain-wide SNMP agent, and create an SNMP
# trap destination.
#
# Params:
# enable Boolean that will enable or disable the agent (default is true)
# trapDestName The name of the trap destination configuration object,
# default is "mydest" trapPort The port number for the trap destination,
# default is 4000
#
# return Returns the agent instance to the caller
###########################################################################
def findOrCreateSNMPTrapDestination(trapDestName="mydest", trapPort=4000, enable=True):
currentDrive=currentTree()
dest = None
isEdit = Boolean.FALSE
try:
cd ("edit:/")
agent = enableDomainSNMPAgent(enable)
dest = agent.lookupSNMPTrapDestination(trapDestName)
if dest is None:
if not cmgr.isEditor():
startEdit()
isEdit = Boolean.TRUE
dest = agent.createSNMPTrapDestination(trapDestName)
dest.setPort(trapPort)
save()
activate()
finally:
if isEdit and cmgr.isEditor():
stopEdit("y")
currentDrive()
return dest
Listing 3 WLST function that creates an SNMP trap destination
Starting a Trap Monitor
Oracle WebLogic Server provides an SNMP command-line tool that can be used to perform a full suite of SNMP commands, including spawning a trap monitor. In order to start up a trap monitor to receive our notifications, open a shell, set up the WLS environment variables, and run the following command:
java weblogic.diagnostics.snmp.cmdline.Manager SnmpTrapMonitor –p 4000
This will start an SNMP trap monitor on the "localhost" address on port 4000.
Springing the Trap
In order to see the SNMP Notification in action, from the MedRec start screen, login to the MedRec Patient application using any valid MedRec patient user, and begin navigating around. When a watch rule fires, the server will emit a log entry:

Figure 1 WLDF Watch Rule Log Entry
Correspondingly, you will see the received SNMP trap notification in the SNMP trap monitor window:

Figure 2 Received SNMP Trap Notification
As you can see, the notification that is sent contains information about what server sent the alert, what the rule was configured for the alert, and the contents of the instrumentation event that cause the alert to fire.
Monitoring CPU Load
Using the W&N framework, WLDF can monitor metrics for any MBean registered in the ServerRuntime MBeanServer. This includes all the supported WLS Runtime MBeans, as well as any custom MBeans registered by applications.
For example, say you wanted to trigger an alert if the average load on the host machine where your WLS instance is running goes above 80%. If you are running WLS on JRockit, you can monitor the average load on all CPUs on the host machine using the AllProcessorsAverageLoad attribute on the JRockitRuntimeMBean. WLDF can be configured to set a Watch rule on this attribute using this criterion.
Listing 4, a snippet from the WLST setup script used in this article, shows how to create such a Watch, and assign an SNMP Notification to it.
cd("edit:/WLDFSystemResources/"+wldfResourceName + "/WLDFResource/" + \
wldfResourceName + "/WatchNotification/" + wldfResourceName)
startEdit()
…
cpuWatch=cmo.createWatch("CPULoad")
cpuWatch.setEnabled(1)
cpuWatch.setRuleExpression(\
"${ServerRuntime//[weblogic.management.runtime.JRockitRuntimeMBean]" + \
"//AllProcessorsAverageLoad} > 0.8 > 0")
cpuWatch.addNotification(snmp_notif)
cpuWatch.setAlarmType("AutomaticReset")
cpuWatch.setAlarmResetPeriod(30000)
Listing 4 Configuring the CPULoad Watch
Unlike the SLA watch, we’ve configured this watch to not trigger more than once every 30 seconds. Normally, if no "alarm" period is set, the notification will fire on every sampling cycle. The configured WLDF sampling cycle for MedRec (configured on the "Collected Metrics" tab of the WLDF Module configuration page) is set to 6 seconds. Setting this alarm period will throttle the alert notifications so that the network is not overloaded by the server sending out alerts every Harvester cycle. (Note that by default, the Harvester cycle is set to 5 minutes, or 300 seconds).
Triggering the CPULoad Watch
In order to simulate the system under stress, a short Java program was run performing simple calculations in a tight loop using several concurrent threads (to ensure all CPU cores were being taxed) for several minutes. While running this program, all CPU cores on the test machine were pegged at 100% utilization.
/**
* Simple program to load up the CPU and trigger
* the CPULoad Watch.
*/
public class Load {
public static void main(String[] args) {
for (int i=0; i < 3; i++) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Thread " +
Thread.currentThread().getName() + " started");
double val=10;
for (;;) {
Math.atan(Math.sqrt(Math.pow(val, 10)));
}
}
}).start();
}
}
}
Listing 5 Simple test program to trigger the CPULoad Watch
Looking at the server output window, we can see the Watch rule alert notices being recorded in the log:

Figure 3 Throttled CPULoad Watch Notices
As you can see in the image above, each notice contains the details regarding what rule triggered, and what data caused it to trigger. Looking at the timestamps of the log entries, we can see that the alerts shown were triggered 35 seconds apart, indicating that the alert throttling is working as expected. As MedRec is configured for 6 second sampling rates, we would expect each alert to trigger within a 36 second window (30 second alarm reset period + 6 second sampling rate).
And, we can see the SNMP traps recording the events as well:

Figure 4 "CPULoad" Watch SNMP Trap Notification
Graphing Data With the Dashboard
WLDF provides a WLS Console extension, the WLDF Dashboard, for visualizing Runtime MBean and Instrumentation data. To enable it, go to the preference page on the Console, click the Extensions tab, and select "diagnostics-console-extension". Enabling a console extension requires the administration server to be restarted. Fortunately, the MedRec domain comes with the Dashboard enabled by default. When enabled, you will see a tab in the upper left corner of the WLS Console labeled WLDF Console Extension.
Visualizing Event Data
Visualizing Instrumentation data is done via the Request Browser tab on the Dashboard. The Request Browser displays a "call tree" constructed from TraceElapsedTimeAction events; using this tree (shown in Figure 5), you can see what requests have been handled by the server within a specific time frame, organized hierarchically by a unique context identifier associated with the request, and subsequently by order of invocation. This context identifier is generated when a request enters the server and is known as the Diagnostic Context ID (DCID). The DCID will travel with a request through the server, and across VM boundaries (in most circumstances), so it is possible to track a request across multiple server instances. The Dashboard, however, only shows request data for a single-server at a time.

Figure 5 WLDF Dasbhoard Request Browser
When you select the Request Browser, it by default will populate the last 5 minutes worth of request data (this can be customized). The left hand side shows the request tree, and below the call tree is a pane showing the details of the selected node in the tree; each colored bar on the tree shows the amount of time spent in that node relative to its siblings in the tree.
As show in Figure 6, if the selected node is a request node, the bottom pane shows the call sequence of the request in linear form. If an individual method is selected, it will show the details of that particular instrumentation event record.

Figure 6 Expanded request call tree in the Request Browser
In addition, you can graph method performance data by dragging a method in a call tree onto the View pane on the right (shown in Figure 7). Note the tooltip appearing over the data point; this conveys the raw data about that point. In general the Dashboard tries to convey as much information as possible via tooltips, so when in doubt – hover!

Figure 7 Expanded request call tree in the Request Browser
Visualizing Runtime MBean Data
The Dashboard can also be used to view live and/or archived Runtime MBean data. The MetricBrowser (shown in Figure 8) shows the list of possible and available WLS Runtime MBean types. A type-node is in bold and expandable, if instances of it are available; if not, it is not selectable or expandable. In addition, if instances of a custom MBean are available, its type and instances are displayed in the tree as well.
MBean metrics can be graphed by dragging an attribute node over onto the View on the right hand side of the Dashboard. As with Method graphs, detailed information on a particular data point can be obtained through a tooltip by doing a mouse-hover over a point in the graph.
Figure 8 shows an example of the Metric Browser graphing the JRockitRuntimeMBean’s AllProcessorsAverageLoad attribute, which has also been configured for Harvesting. The same View is also showing the previously created method graph shown in Figure 7.

Figure 8 Dashboard MetricBrowser Tree with active metrics chart
By default, the Dashboard can track 15 minutes worth of live data, and the chart will show the most recent 5 minutes by default. If the metric is being archived in the WLDF Archive by the Harvester, the historical data will also be available to the chart. You can use the scrollbar (ALT-S) to scroll back the graph to view any recorded data for the metric. In addition, you can zoom in or out on a chart using the mouse (SHIFT-left-mouse-drag), or the keyboard (ALT-Z to zoom in, ALT-O to zoom out). In Figure 9 below, the method graph is zoomed in to narrow down to a few select points, while the metrics chart has been zoomed out to include nearly 30 minutes worth of data in the view.

Figure 9 Dashboard scrolling and zooming
To reset a chart to its default viewport settings, select it and press the "r" key.
Other Dashboard Features
This represents the basic functionality of the Dashboard; it also supports
- the ability to customize many features of each chart
- the ability to create and persist custom "views", or collections of charts
- Drag-and-drop of metrics between charts
- Dag-and-drop of charts within a view
- "Custom" metrics, which are a set of simple functions that can be used to apply arbitrarily complex expressions to a data stream
All customized views and custom metrics are persisted in the logged-in user’s console preferences. For a full discussion on the WLDF Dashboard’s features, please consult the WebLogic Server documentation on this subject (see References section).
Finding Bottleneck Methods
At times it can be useful to know where you are spending the most time in your application. If you are experiencing slowdowns, you will want to know which parts of your application you are spending the most time in.
In the 10.3 release, Oracle WebLogic Server introduced a new instrumentation action, the MethodInvocationStatisticsAction. Unlike the other instrumentation actions, which record one or more events in the WLDF Archive, this action will capture performance metrics around a joinpoint in memory. Without the overhead of recording events to the Archive, it provides way of capturing common statistics with minimal overhead.
Some of the statistics that can be captured about a particular joinpoint include:
- Number of invocations
- Average execution time (in nanos)
- Standard deviation in observed execution time
- Minimum execution time
- Maximum execution time
These statistics, and a few others, are then made available through an attribute on the WLDFInstrumenationRuntimeMBean called MethodInvocationStatistics. The MethodInvocationStatistics attribute is organized as a hierarchy of Map objects, keyed in the following manner:
- Full class name
- Method name
- Method signature (distinguishes overloaded instances of the same name)
- Method statistics
Figure 10 shows these relationships.

Figure 10 MethodInvocationStatistics attribute structure
Because the MethodInvocationStatisticsAction only captures information in memory, it does not incur the I/O penalty of other instrumentation actions. This makes it a more lightweight mechanism for capturing performance statistics, and can help identify bottlenecks in your application. You can navigate through the map structures and identify the low performing parts of your application.
Configuring a New Monitor with MethodInvocationStatisticsAction
In a departure from our WLST-driven setup examples, we will use the WLS Console to configure WLDF instrumentation for the MedRec application. The WLS Console has an intuitive assistant that easily guides the user through the process of modifying application configurations using deployment plans. Once created, the deployment plans can also be used with WLST scripts.
The basic steps using the WLS Console are:
- Select Deployments on the domain navigation tree, then select the medrec application in the list of deployed applications.
- Navigate to the application’s Configuration tab.
- Select the Instrumentation tab.
- Click on the Add Custom Monitor button above the monitors table at the bottom of the page.
- Enter "MethodStatsMonitor" for the monitor name.
- Enter a description for the monitor if desired in the Description box.
- Choose Around in the Location Type selector.
- Enter the following text for the pointcut:
execution(public * com.bea.medrec.* *(...)) AND NOT
(execution(public * com.bea.medrec.* get*(...)) OR
execution(public * com.bea.medrec.* set*(...)) OR
execution(public * com.bea.medrec.* __WL_*(...)));
When finished, the screen should look as shown below in Figure 11.

Figure 11 Creating an application instrumentation monitor using the WLS Console.
The pointcut for this monitor essentially says, "instrument all public methods for classes where the package name starts with ‘com.bea.medrec’, except for all accessor methods and methods where the name begins with ‘__WL_’. This allows us to cast a wide net, while also eliminating a lot of uninteresting methods such as simple getters and setters, and WLS-generated code.
The next few steps will save the changes as an application deployment plan to be merged by the deployment subsystem at runtime:
- Click on OK.
- On the "Save Deployment Plan" screen, you may choose an alternate path for the saved deployment plan, or select OK for the default location.
At this point, the new monitor is in the deployment plan, but not yet applied to the running application. Before applying it, however, we need to assign an action to the new monitor. From the instrumentation configuration page:
- Select the Configuration tab and then the Instrumentation sub-tab
- Select MethodStatsMonitor in the table at the bottom
- In the Actions chooser section, assign MethodInvocationStatisticsAction to the monitor, as shown below:
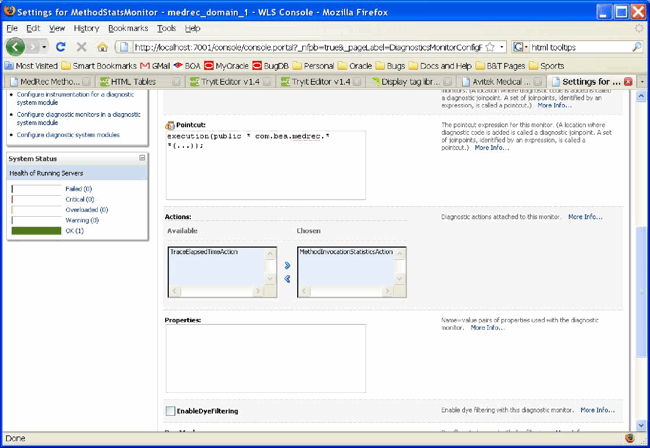
Figure 12 Assigning the MethodInvocationStatisticsAction
- Then click the Save button.

Now with the plan in place, we need to apply it to the "medrec" application:
- Select Deployments.
- Check the box next to the "medrec" application.
- Click on Update.
- Click on the radio button next to Redeploy this application….
- Click on Next.
- Click on Finish.
At this point, the application has been redeployed and the new monitor is active.
A Note About HotSwap
In this case, without HotSwap enabled, we needed to redeploy the application to cause the new monitor to weave into the application code, as we added a new pointcut to the configuration. However, you can modify most of an application’s monitor configuration without requiring a redeploy. This includes changes to the Actions, Properties, EnableDyeFiltering, and Description attributes (basically, anything that does not require bytecode weaving). With Java HotSwap enabled, however, you can change any monitor attribute and update the application in-place (without a redeploy).
To enable HotSwap using WLDF Instrumentation, set the following environment variable prior to running the MedRec startup script:
For Unix:
JAVA_OPTIONS=-javaagent:$WL_HOME/server/lib/diagnostics-agent.jar
export JAVA_OPTIONS
For Windows:
set JAVA_OPTIONS= -javaagent:%WL_HOME%\server\lib\diagnostics-agent.jar
Examining Method Statistics
Once deployed, the MethodInvocationStatisticsAction begins capturing statistics as the instrumented code is executed. The statistics shown in this section were generated quite quickly by simply navigating around the MedRec patient application with the instrumentation monitor we defined previously enabled. These statistics can be examined through WLST, as well as programmatically through your own applications.
Using WLST
Using WLST, you can interact with the WLDFInstrumentationRuntimeMBean instances as you can with any other WLS MBean. Each application will have its own instance, so for the "medrec" application, you will need to navigate to
cd('serverRuntime:/WLDFRuntime/WLDFRuntime/WLDFInstrumentationRuntimes/medrec')
If you do an "ls" at this point, you may get a large amount of information displayed, as the full MethodInvocationStatistics values will be displayed to the WLST console as shown in Figure 13:

Figure 13 Listing the MethodInvocationStatistics map in WLST
In addition to access to the statistics map structure, you can also request specific values through the following operation on the WLDFInstrumentationRuntimeMBean:
/**
* Drills down into the nested MethodInvocationStatistics Map
* structure and returns the object at the specified level.
* @param expr Expression conforming to the harvester syntax
* for the MethodInvocationStatistics property without the attribute name prefix.
* @operation
*/
public Object getMethodInvocationStatisticsData(String expr) throws ManagementException;
This method will allow you to provide an expression to lookup a subset of values from the map structure. This can be done programmatically using a Java JMX client, or interactively through WLST, as shown in Figure 14 below.

Figure 14 Using getMethodInvocationStatisticsData(String ) in WLST
The expression syntax used here can also be used to configure both the WLDF Harvester and the W&N framework to monitor values from the MethodInvocationStatistics attribute. See the WLDF MethodInvocationStatisticsAction documentation for more details on the expression language and its usage here.
Method Statistics Sample Webapp
Programmatically accessing the invocation statistics is the same as through WLST. Once you have access to the WLDFInstrumentationRuntimeMBean instance for an application, it’s quite easy to write some code that can exploit this information.
Figure 15 below shows the output of a simple web application consisting of a simple JSP and a utility class, which uses the MethodInvocationStatistics data to render a list of method statistics sorted by execution time in descending order. This shows the "hot methods" for the application, using data generated by the MethodStatsMonitor we configured for the MedRec application. Using the open source DisplayTag library, we are able to quickly create an application for viewing and exporting the statistics data from around the domain.

Figure 15 MethodStats app showing method statistics sorted by execution time.
The application, which is deployed on the administration server, builds this table by finding all active WLDFInstrumentationRuntime instances for all running servers via the DomainRuntime MBeanServer. You can find the sample code for this application here.
Conclusion
WLDF provides many powerful features, and in this article we introduced you to a small (albeit extremely useful) fraction. Using the Instrumentation and W&N frameworks can provide you with an easy way to view how your application is performing, and to signal alerts based on criteria you define over a number of standard communication technologies. When combined with the other features of WLDF, such as the Harvester, you can get a complete current and historical picture of your server environment. You can also use the WLDF Dashboard console extension, which provides you with a flexible way to visualize your data.
We are very excited about the tools we have provided thus far, and we have plans for expanding and building upon these features in upcoming releases. If this article piques your curiosity about WLDF, please examine the references section to learn more. Lastly, we are always looking for feedback, so please send us your questions and suggestions (including your own interesting use cases!). We rely upon our customers to help us shape our plans for the future.
References
- WLS 10.3.1 documentation
- WLST Documentation
- Configuring and Using the Diagnostics Framework
- Using the Diagnostic Framework Console Extension
- Configuration Wizard Documentation
- MedRec Configuration Wizard Extension Template Documentation
- DisplayTag Tag Library
Mike Cico is a senior developer on the WebLogic Server Diagnostics Framework team with Oracle. When not doing that, he has been known to spend time with his family camping, bike riding, and skiing; when not doing those things, he's usually lifting weights down at his local gym.