Using Caches in Multi-Tier Applications: Best Practices
Learn how the strategic use of caching technology can improve the performance of your multitier applications, as well as how to keep multiple caches in synch across clustered environments.
by Andrei Cioroianu
Published July 2005
Developer: Architecture
Multi-tier architectures help make complex enterprise applications manageable and scalable. Yet, as the number of servers and tiers increases, so does the communication among them, which can degrade overall application performance.
Using caching technology at strategic points across the multi-tier model can help reduce the number of back-and-forth communications. Furthermore, although cache repositories require memory and CPU resources, using caches can nonetheless lead to overall performance gains by reducing the number of expensive operations (such as database accesses and Web page executions). However, ensuring that caches retain fresh content and invalidate stale data is a challenge, and keeping multiple caches in synch, in clustered environments, is even more so.
Downloads for this article:
This article analyzes the types of caches used in multi-tier applications, and discusses ways to solve cache-related problems, such as "stale" data. The article also looks into the caching frameworks provided by Oracle; specifically, Oracle Web Cache, Web Object Cache, Java Object Cache, and Oracle TopLink. You'll also learn about "no-cache" HTTP headers, dynamic content caching, data versioning, and optimistic locking.
Caching Frameworks
For a standalone application, it's fairly easy to implement your own caching mechanisms using the Java Collections Framework, to create a repository for frequently-used objects. For example, the Java Map data structure (available in the java.util package), works fine as long as you have a reasonably small number of objects that don't consume too much memory.
However, creating your own cache for persistent objects or Web content, especially for a large, distributed application, is orders of magnitude more difficult than for a self-contained small application, because you must:
- Limit the cache's size since you can't keep an entire database or every piece of dynamic content in memory
- Update the cached objects and remove the stale content from your cache as appropriate
- Synchronize multiple caches distributed across different servers, for applications deployed across clusters, for example.
Caching frameworks solve these problems, and many others. Let's take a quick look at several caching frameworks available from Oracle, in the context of the typical Web-based application architecture (Figure 1).
Oracle Caching Frameworks Overview
Oracle Web Cache, Web Object Cache, Java Object Cache, and Oracle TopLink are not mutually exclusive, but rather complement each other-they are used in different tiers of an enterprise application, as shown in Figure 1.
Web browsers connect through the Oracle Web Cache (perhaps via a proxy cache) to the Web server that obtains its dynamic content from a JSP container. Servlets and JSPs use Web Object Cache while the application's business logic can cache frequently used objects with the help of Java Object Cache. The business logic tier can access an Oracle Database via Oracle TopLink, which caches data objects.
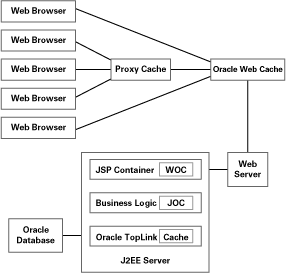
Figure 1: Simple Architecture
A Web caching framework facilitates quick retrieval of content in a Web application environment. Retrieving static content is fairly simplein fact, the HTTP protocol specification ( RFC 1945 ) defines some inherent mechanisms for minimizing the communication between Web browsers and servers, by caching content on HTTP clients, or by using proxy caches.
HTTP caching works well for static content, but it cannot handle dynamic content that is personalized for each user. For caching dynamic content, you need a solution that caches page fragments and assembles documents from those fragments on the fly, which is the functionality provided by Oracle Web Cache, as follows:
Oracle Web Cache is an HTTP-level cache maintained externally to the application. It leverages the built-in caching capabilities of a generic Web server (that is, it is a reverse proxy cache) that supports caching static contentHTML, GIF, or JPG files for examplebut it can also cache dynamic content, including application data (such as SOAP responses).
Oracle Web Cache supports partial-page caching using a standard called Edge Side Includes (ESI), an XML-based language for defining template pages. (An ESI template page is used by an ESI processor, such as Oracle Web Cache, to assemble HTML documents from both cacheable and non-cacheable fragments.)
Unlike proxies and Web browser caches, Oracle Web Cache is designed to run on servers where Web applications and Web administrators can control the cache using APIs and tools. Oracle Web Cache is very fast, but you can't process the cached content (using Java code) before it's delivered. If you need to do that, you can use Oracle Web Object Cache (WOC).
Oracle Java Object Cache (JOC), which is a feature of Oracle Application Server Containers for J2EE (OC4J) 10g, is an easy-to-use, general caching framework that manages Java objects within a process, across processes, and on disk. The application specifies the cache's capacity and the maximum number of objects that can be kept in the cache.
JOC lets you define namespaces called regions, group objects within a region, store objects in the cache, retrieve the cached objects, and replace them at any time. You can specify a time-to-live for each object, and you can use event listeners to be notified when a cached object is invalidated. Since cached objects can be accessed concurrently, you should not modify them directly. Rather, you must create a private copy of a cached object, modify it, and then replace the cached object with the modified copy.
Oracle Web Object Cache (WOC), also an OC4J 10g feature, is a Java framework for caching Web content, serializable Java objects, and XML objects (DOM trees). It's an application-level cache for Java objects, running on the same JVM that runs your Servlets and JSP pages.
WOC provides a Java API and a JSP tag library that you can use to manage the cached dynamic content and objects in the Web tier of your J2EE applications. JOC is the default cache repository of WOC, however, you can plug-in other cache repositories if you like.
Oracle TopLink provides caching and mapping frameworks; caching data retrieved from the database improves the application's performance, while mapping relational data to objects, reduces the amount of handwritten-code needed to query and update the database.
Oracle TopLink provides a Java API that you can use to construct database-independent queries, which the framework translates into SQL statements that take advantage of the features provided by each database server. After executing a query, TopLink retrieves data from the result set, and stores this data into objects, which are cached.
To update the database, you use the Oracle TopLink API to retrieve clones of the objects from the cache, and then you simply update the clones' properties using their get() and set() methods. Oracle TopLink does the heavy lifting, updating cached objects and generating the SQL statements that store the new data into the database.
Clustering Caches
When you scale an application across multiple servers or nodes, as in distributed and clustered environments, you can also scale most of the Oracle caches as well. Figure 2 shows the architecture of an application that is deployed on multiple J2EE servers and is accessed through multiple Oracle Web Cache nodes.
Oracle Web Cache Cluster functions as a single logical cache that partitions cached content across all nodes that comprise the cluster. A regular page will be cached on a single node, while "popular" content is automatically replicated across the cluster. The support for partitioning as well as replication results in better performance and increased reliability for the Web Cache Cluster.
Oracle JOC as well as Oracle TopLink can synchronize multiple caches running on different J2EE servers.
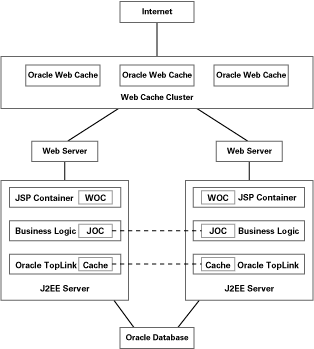
Figure 2: Clustered Architecture
Controlling Web Caches
Suppose two concurrent usersuser A and user Bare trying to update the same piece of data using a Web-based interface. Let's say User A submits the changed information first, and the application stores the information into the database. At this point, it is very possible that user B sees stale data in his Web browser, and changes to this data can override the modifications made by User A. Even if the application prevents concurrent users from accessing the same data, someone may see stale content if the user clicks the browser's Back button. These problems can lead to inconsistent information or loss of data if the application developer ignores them.
In the sections below, I outline a few strategies that ensure freshness of content served, thereby avoid the stale-data problem.
Using No-Cache Headers Web browsers and proxies must cache static pages, JavaScripts, CSS files and images in order to minimize the network traffic. Caching dynamic content, however, can have undesired side effects, especially in the case of Web forms that contain data extracted from a database.
Fortunately, it is very easy to disable the HTTP caching, using the "Pragma: no-cache" and "Cache-Control: no-cache" headers defined by the HTTP/1.0 and HTTP/1.1 standards respectively. These headers can be set, for example, with a simple filter:
package caches;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
public class NoCacheFilter implements Filter {
private FilterConfig config;
public void init(FilterConfig config)
throws ServletException {
this.config = config;
}
public void doFilter(ServletRequest request,
ServletResponse response,
FilterChain chain)
throws IOException, ServletException {
HttpServletResponse httpResponse
= (HttpServletResponse) response;
httpResponse.addHeader("Pragma", "no-cache");
httpResponse.addHeader("Cache-Control", "no-cache");
chain.doFilter(request, response);
}
public void destroy() {
}
}
Using Caches in Other Application Scenarios
Caches are useful in numerous other application scenarios, in addition to those illustrated in Figure 1 and Figure 2. For example, you can consider using caches to minimize Web services overheadthe extensive XML processing that goes on under the covers with Web services is costly, in terms of performance. You could cache SOAP responses and WSDL documents (assuming that the Web services implementation isn't already doing so) to ameliorate the impact.
Another good example of an appropriate use of caching is Oracle BPEL Process Manager, which provides a framework for designing, deploying, monitoring, and administering BPEL processes. Oracle BPEL Process Manager can be deployed in a J2EE cluster, with an Oracle Web Cache as a load-balancing front-end to the cluster, routing requests to various nodes in the cluster. In addition, BPEL Manager uses a cache for the DOM trees that are saved in a "dehydration store" which essentially preserves the state of the long-running processes while they wait for asynchronous callbacks.
The filter can be configured in the web.xml file of your application for all JSP pages, for a subset of them, or just for the Web pages that use JSF and ADF Faces, as in the following example:
NoCacheFilter
caches.NoCacheFilter
NoCacheFilter
FacesServlet
You can modify the filter to set other Cache-Control headers as well as Age, Date, Expires and Last-Modified, depending on how data is updated in your application. See the HTTP specification for more details on these headers.
Caching Dynamic Content As already mentioned, Oracle offers two complementary Web caching frameworks: Web Object Cache (WOC) and Oracle Web Cache. You should use WOC only when your cached content must be post-processed for each request, before delivery, using Java code. In most cases, however, you have page fragments or whole pages, which once generated, don't need any kind of post-processing.
Web Cache is the ideal solution for these, even if the cached content depends on request parameters or cookies. Web Cache will maintain a different content version for each set of parameters and will substitute cookies that are used for personalization or as session IDs. You just have to configure Web Cache properly and to identify the cacheable and non-cacheable fragments, marking them with the ESI tags. In JSP pages, you can use the Java Edge Side Includes (JESI) tag library, which generates the ESI markup.
JESI has two usage models: "control/include" and "template/fragment." When choosing control/include, you set the caching attributes of each page with <jesi:control> and you include content fragments with <jesi:include> . The <jesi:control> tag lets you specify whether the dynamic content generated by a JSP is cacheable or not. If it is cacheable, you can also specify an expiration time expressed in seconds as in the following example:
<%@taglib prefix="jesi"
uri="http://xmlns.oracle.com/j2ee/jsp/tld/ojsp/jesitaglib.tld" %>
<jesi:control cache="yes" expiration="3600"/>
<jesi:include page="header.jsp"/> <br>
<jesi:include page="content.jsp"/> <br>
<jesi:include page="footer.jsp"/>
The control attributes of a cacheable page have no effect on the included pages, which must use the <jesi:control> tag too for specifying their expiration times. Web Cache will invoke the container page and the included pages separately, which means that these pages do not share the JSP request and response objects as in the case of <jsp:include> . Therefore, the container page and the included pages cannot communicate through attributes and beans stored in the JSP request scope.
The "template/fragment" usage model allows you to maintain all cacheable and non-cacheable fragments as well as the markup that glues them within the same JSP page. Web Cache will invoke a page that uses <jesi:template> and <jesi:fragment> multiple times for obtaining the template content and the fragments separately. This model is a bit more difficult to use, but it has the advantage that you don't have to split the content of your pages into multiple files.
Web Cache accepts requests for invalidating the cached content over the HTTP protocol. These requests use an XML-based format, but you don't have to build them yourself since Web Cache provides a Java API and JESI tags that allow you to specify the content from the cache that must be invalidated. You can also perform this operation manually, using the administration tools.
On Data Versioning and Locking Strategies
Browser caches, proxies, WOC and Web Cache improve the Web performance of your applications, but generate stale-data and stale-content problems, which can be minimized by using the NoCacheFilter filter and the cache-invalidation features of the frameworks.
These problems cannot be completely solved in the Web tier because an application running on a server cannot notify Web browsers when the content becomes stale. The best thing you can do is to make sure that stale data is not written into the database, using the optimistic-locking feature of Oracle TopLink, which supports data versioning.
Now that you have an understanding of some of the various caching approaches, let's take a look at some examples of saving versioned objects into a database, retrieve these objects, and update or delete them. You'll also see the SQL statements that are generated and executed by TopLink.
Working with Persistent Objects Oracle TopLink adds persistent objects to a shared session cache when a database query is executed or when a unit of work successfully commits a transaction. The identity maps that hold the cached objects can use strong, weak, or soft references, which determine if and when these objects are garbage-collected. In addition to the objects created by Oracle TopLink when a query is executed, the registerObject() method of UnitOfWork returns object clones that you use in your code to modify the properties of a persistent object.
Web frameworks, such as JSF, create and manage bean instances too. In order to use Oracle TopLink together with JSF, you need a method that copies the properties of a view bean created by JSF to an object clone returned by an Oracle TopLink method and vice versa. Apache's Commons BeanUtils provides such a method, which should be wrapped to make it easier to use:
package caches;
import org.apache.commons.beanutils.PropertyUtils;
import java.lang.reflect.InvocationTargetException;
public class MyUtils {
public static void copy(Object source, Object dest) {
try {
PropertyUtils.copyProperties(dest, source);
} catch (IllegalAccessException x) {
throw new RuntimeException(x);
} catch (InvocationTargetException x) {
throw new RuntimeException(
x.getTargetException());
} catch (NoSuchMethodException x) {
throw new RuntimeException(x);
}
}
}
Using Optimistic Locking There are two ways to prevent concurrent units of work (transactions) from modifying the same persistent object:
- pessimistic locking, which locks an object whenever it is accessed (even when it's only being read), preventing others from reading or updating the object until the lock is released;
- optimistic locking, which doesn't lock an object (or a row) when it's read; TopLink only verifies the row's data when a unit of work commits a change.
With pessimistic locking, a database row is locked while somebody uses a Web form to update it. One of the problems with pessimistic locking is that rows can be locked for an indefinite amount of timefor example, a user leaves a page without clicking the submit button, the browser crashes, or there's a network problem.
With optimistic locking, Oracle TopLink verifies if the row's data was modified since it was retrieved from the database. One way to do that is to compare all or some of the original object's fields with the row's data. This solution ensures that nobody else modified the object during the unit of work, which works well if the object is modified in the business logic tier without the involvement of any user interface.
When a Web-based interface is used to update the object, a unit of work can't wait until the user clicks a submit button for the same reasons that make pessimistic locking impractical. The only solution is to use a version field that is incremented each time the row is updated. The application gets the current version when it reads the object, and then it passes the version to the Web browser as a hidden form field. This can be done very easily with JSF:
<h:inputHidden id="version" value="#{myBean.version}"/>
When the Web browser submits the from-data, JSF stores it into a view bean together with the version from the hidden form field. Then, Oracle TopLink compares the version of the modified data with the row's version. If they don't coincide, Oracle TopLink throws an OptimisticLockException . Otherwise, the row is updated and the version is incremented. The following examples show how this works, using a simple bean that has an id property acting as a primary key, a version property, and a single data property:
package caches;
public class MyBean {
private String id;
private int version;
private String data;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
...
}
In your own applications, you can use as many data properties as you need, and you can rename the id and version properties as you like.
Saving New Objects To store a bean into a database with Oracle TopLink, you have to acquire a client session and a unit of work. Then, you create a new bean instance and you register it to the unit of work with the registerObject() method, which returns a clone that can be used for editing.
After copying the view bean's properties to the clone with MyUtils.copy() , you call the commit() method, which saves all changes of the clone into the database. This means that Oracle TopLink inserts the view bean's properties into the database. In addition, Oracle TopLink sets the version of the clone object and saves the new version number. Therefore, you have to update the version property of the view bean:
public void insert(MyBean viewBean) {
ClientSession session = server.acquireClientSession();
UnitOfWork uow = session.acquireUnitOfWork();
MyBean newBean = new MyBean();
MyBean beanClone = (MyBean) uow.registerObject(newBean);
MyUtils.copy(viewBean, beanClone);
uow.commit();
viewBean.setVersion(beanClone.getVersion());
}
Oracle TopLink generates and executes a single INSERT statement:
INSERT INTO MyTable (id, version, data)
VALUES ('someID', 1, 'someData')
Retrieving Objects You can use Oracle TopLink's query API to read a persistent object from the database. The ReadObjectQuery method lets you select a single object, while ReadAllQuery allows you to obtain a collection of objects. In both cases, an expression builder can be used to define the WHERE clause of the SELECT statement. In this example, the id field must be equal to the id parameter:
private MyBean read(Session session, String id) {
ReadObjectQuery query
= new ReadObjectQuery(MyBean.class);
ExpressionBuilder myBean = new ExpressionBuilder();
query.setSelectionCriteria(
myBean.get("id").equal(id));
return (MyBean) session.executeQuery(query);
}
The read() method is used to select an object from the database, but it's also helpful when you want to update or delete an existing object. The select() method acquires a client session and calls read() :
public MyBean select(String id) {
ClientSession session = server.acquireClientSession();
return read(session, id);
}
Oracle TopLink tries to get the persistent object from the cache. If the cache doesn't contain the object, the following SELECT statement is used to retrieve the persistent object from the database:
SELECT id, version, data FROM MyTable
WHERE (id = 'someID')
Updating Existing Objects When you want to update a persistent object, you can use the same read() method that you use to select the object. Then, you acquire a unit of work and obtain a clone of the persistent object. Now you can modify the clone's properties, using for example MyUtils.copy() .
As explained earlier, commit() throws an OptimisticLockException if the object's version isn't the same as the version of the row from the database. In this case, you can refresh the properties of the bean with refreshObject() :
public void update(MyBean viewBean) {
ClientSession session = server.acquireClientSession();
MyBean cachedBean = read(session, viewBean.getId());
UnitOfWork uow = session.acquireUnitOfWork();
MyBean beanClone = (MyBean) uow.registerObject(cachedBean);
MyUtils.copy(viewBean, beanClone);
try {
uow.commit();
viewBean.setVersion(beanClone.getVersion());
} catch (OptimisticLockException x) {
Object staleBean = x.getObject();
Object freshBean = session.refreshObject(staleBean);
MyUtils.copy(freshBean, viewBean);
throw x;
}
}
Oracle TopLink executes the following UPDATE statement:
UPDATE MyTable SET data = 'modifiedData', version = 2
WHERE ((id = 'someID') AND (version = 1))
At the next update, the SQL statement looks like this:
UPDATE MyTable SET data = 'changedData', version = 3
WHERE ((id = 'someID') AND (version = 2))
If an OptimisticLockException occurs, you can signal the error to the user with the JSF API
import oracle.toplink.exceptions.OptimisticLockException;
import javax.faces.application.FacesMessage;
import javax.faces.context.FacesContext;
...
try {
myDAO.update(myBean);
}
catch (OptimisticLockException x) {
FacesContext context
= FacesContext.getCurrentInstance();
FacesMessage message
= new FacesMessage(x.getMessage());
message.setSeverity(FacesMessage.SEVERITY_FATAL);
context.addMessage(null, message);
}
Resources
- Oracle TopLink
- OC4J JSP Tag Libraries and Utilities Reference (JESI, WOC, ...)
- Oracle BPEL Process Manager
- RFC 2068: HTTP/1.1 Specification
- ESI Specification
- JSR 128: JESI - JSP Tag Library for ESI
- Caching In on the Enterprise Grid (PDF)
- Overview of Oracle TopLink Caching and Locking
- Building Database-driven Applications with JSF
This code shows the exception's message in the Web page, which is useful for verifying that optimistic locking works. Before deploying the application on a production server, you would have to replace the exception's message with an error message that users can understand.
Deleting Objects It is very easy to delete persistent objects. You just have to get them as in the previous examples, and then you call deleteObject() :
public void delete(MyBean viewBean) {
ClientSession session = server.acquireClientSession();
UnitOfWork uow = session.acquireUnitOfWork();
MyBean cachedBean = read(uow, viewBean.getId());
uow.deleteObject(cachedBean);
uow.commit();
}
Here is the DELETE statement executed by Oracle TopLink:
DELETE FROM MyTable
WHERE ((id = 'someID') AND (version = 3))
Summary
Caches allow you to deploy complex enterprise applications with large user bases on commodity hardware. Managing caches, however, is not a trivial task. Therefore, instead of building your own caching mechanisms, you should use reliable caching frameworks that are easy-to-use.
This article presented some of the frameworks developed by Oracle, explaining where and when to use each of them. Java Object Cache is a general solution that can be used in the business logic tier, but it is also useful in a JSP container as a cache repository for Web Object Cache. Specialized solutions, such as Oracle TopLink and Web Cache, provide many additional benefits in the persistence and presentation tiers, such as object-relational mapping and Web monitoring. Keep in mind that you don't have to use all these frameworks within the same application. In many cases, only one or two of them provide enough performance gains.
Andrei Cioroianu ( devtools@devsphere.com ) is the founder of Devsphere , a provider of Java frameworks, XML consulting services, and Web development services. Cioroianu has written many Java articles published by Oracle Technology Network, ONJava , JavaWorld , and Java Developer's Journal . He also coauthored the books Java XML Programmer's Reference and Professional Java XML (both from Wrox Press).