An Introduction to Real-Time Data Integration
by Mark Rittman
A introduction to Oracle Data Integrator, Java-based middleware that uses the database to perform set-based data integration tasks in an SOA.
In these days of complex, “hot-pluggable” systems and service-oriented architecture (SOA), bringing data together and making sense of it becomes increasingly difficult. Although your primary applications database might run on Oracle Database, you may well have other, smaller systems running on databases and platforms supplied by other vendors. Your applications themselves may intercommunicate by using technologies such as Web services, and your applications and data may be hosted remotely as well as managed by you in your corporate data center.
Oracle Data Integrator, a member of the Oracle Fusion Middleware family of products, addresses your data integration needs in these increasingly heterogeneous environments. It is a Java-based application that uses the database to perform set-based data integration tasks but extends this capability to a range of database platforms as well as Oracle Database. In addition, it gives you the ability to extract from and provide transformed data through Web services and messages and to create integration processes that respond to and create events in your service-oriented architecture.
Oracle Data Integrator Product Architecture
Oracle Data Integrator is organized around a modular repository that is accessed by Java graphical modules and scheduling agents. The graphical modules are used to design and build the integration process, with agents being used to schedule and coordinate the integration task. When Oracle Data Integrator projects are moved into production, data stewards can use the Web-based Metadata Navigator application to report on metadata in the repository. Out-of-the-box Knowledge Modules extract and load data across heterogeneous platforms, using platform-specific code and utilities.
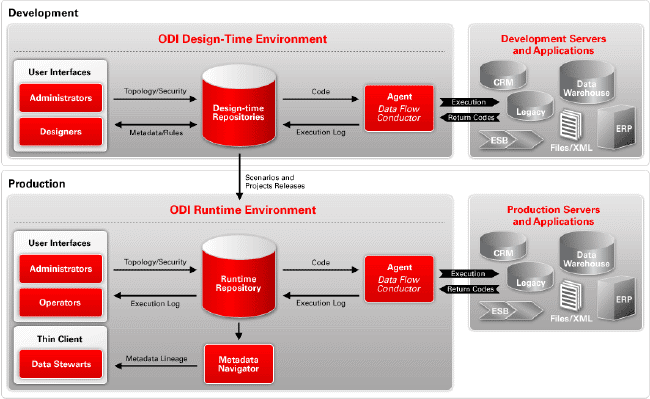
The Oracle Data Integrator repository consists of a master repository, which contains details on users and roles; connections to databases and other datasources; versions of projects; and one or more work repositories that contain details of the data models and mappings used to integrate the data. These repositories can be stored in both Oracle and non-Oracle relational databases and are managed by use of the graphical modules and accessed at runtime by agents.
Four graphical modules are used to create and manage Oracle Data Integrator projects:
- Designer is used to define data stores (tables, files, Web services, and so on), interfaces (data mappings), and packages (sets of integration steps, including interfaces).
- Topology Manager is used to create and manage connections to datasources and agents and is usually restricted so that only administrators have access.
- Operator is used to view and manage production integration jobs.
- Security Manager manages users and their repository privileges.
Being Java-based, these applications run in any Java environment, including Microsoft Windows, Macintosh OS X, and Linux.
Declarative Design
In general, a data integration task consists of two key areas:
- The business rules about what bit of data is transformed and combined with other bits
- The technical specifics of how the data is actually extracted, loaded, and so on
This split in focus means that often the best people to define the business rules are an organization’s technical business or data experts, whereas the technical specifics are often better left to technical staff such as developers and DBAs. With most data integration tools, it is often difficult to split responsibilities in this way, because their data mapping features mix up business rules and technical implementation details in the same data mapping. Oracle Data Integrator takes a different approach, though, and, like SQL, uses a declarative approach to building data mappings, which are referred to within the tool as “interfaces.”
When creating a new interface, the developer or technical business user first defines which data is integrated and which business rules should be used. In this step, tables are joined, filters are applied, and SQL expressions are used to transform data. The particular dialect of SQL that is used is determined by the database platform on which the code is executed.
Then, in a separate step, technical staff can choose the most efficient way to extract, combine, and then integrate this data, using database-specific tools and design techniques such as incremental loads, bulk-loading utilities, slowly changing dimensions, and changed-data capture.
Extensible Knowledge Modules
As Oracle Data Integrator loads and transforms data from many different database platforms and uses message-based technologies such as Web services while being able to respond to events, the technology used to access and load these different datasources needs to be flexible, extensible, and yet efficient. Oracle Data Integrator solves this problem through the use of knowledge modules.
Knowledge modules are “plug-ins” to Oracle Data Integrator that encapsulate a best practice in loading, transforming, or integrating data for a specific datasource or target. Oracle Data Integrator has six types of knowledge module, as shown in the following diagram:
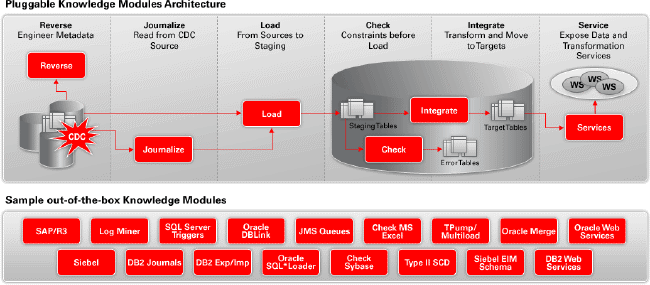
- Reverse-engineering knowledge modulesare used for reading the table and other object metadata from source databases.
- Journalizing knowledge modules record the new and changed data within either a single table or view or a consistent set of tables or views.
- Loading knowledge modules are used for efficient extraction of data from source databases and include database-specific bulk unload utilities where available.
- Check knowledge modules are used for detecting errors in source data.
- Integration knowledge modules are used for efficiently transforming data from staging area to the target tables, generating the optimized native SQL for the given database.
- Service knowledge modules provide the ability to expose data as Web services.
Knowledge modules are also extensible, so you can add functionality not currently provided by Oracle Data Integrator out of the box. For example, it would be a relatively simple task to take the existing set of Oracle-based knowledge modules and extend them to cover the Oracle Data Pump feature in Oracle Database 10g.
Data-Quality Firewalls
If you are the person responsible for loading a data warehouse, one issue you will no doubt have to deal with is an ever-decreasing time window for performing the nightly load. Time becomes especially tight if your source data contains a lot of errors that can’t be detected until it has been loaded into your data warehouse staging area.
Oracle Data Integrator takes an innovative approach to this problem, by using the check knowledge modules to “firewall-off” dirty data at the datasource, allowing only data that complies with your business rules to enter your integration process. Using this approach to efficiently ensure data quality, you would first define one or more constraints on your source objects and then use a check knowledge module to identify any rows that fail these constraints and copy them to an error table.

Then, when you subsequently take data from these source objects and use them in an interface, you can be sure that only data that complies with these constraints is loaded, and you can deal with the dirty data in the error tables as a separate process.
Support for Changed-Data Capture
Another useful technique for minimizing data load times is to load only data that is new or has changed. If you are lucky, the designers of your applications have helpfully provided indicators and dates to identify data that is new or changed, but in most cases, this information is not available and it is up to you to identify the data you are interested in.
Because this is a fairly common requirement, Oracle Data Integrator provides journalizing knowledge modules that monitor source databases and copy new and changed records into a journal, which can then be read from instead of the original source table. Where database vendors such as Oracle provide native support for changed-data capture, these features are used; otherwise, the journalize knowledge module uses techniques such as triggers to capture data manipulation language (DML) activity and make the changes available. Later in this article, you will see how support for the Oracle Change Data Capture feature is provided by Oracle Data Integrator and how it can be used to incrementally load, in real time, a database on a different database platform.
Oracle Data Integrator in Relation to Oracle Warehouse Builder
At this point, regular users of Oracle Warehouse Builder are probably wondering how Oracle Data Integrator relates to it and how it fits into the rest of the Oracle data warehousing technology stack. The answer is that Oracle Data Integrator is a tool that’s complementary to Oracle Warehouse Builder and can be particularly useful when the work involved in creating the staging and integration layers in your Oracle data warehouse is nontrivial or involves SOA or non-Oracle database sources.
For those who are building an Oracle data warehouse, Oracle Warehouse Builder has a strong set of Oracle-specific data warehousing features such as support for modeling of relational and multidimensional data structures, integration with Oracle Business Intelligence Discoverer, support for loading slowly changing dimensions, and a data profiler for understanding the structure and semantics of your data.
Where Oracle Data Integrator provides value is in the initial preparation and integration of your source data, up until the staging area of the data warehouse.
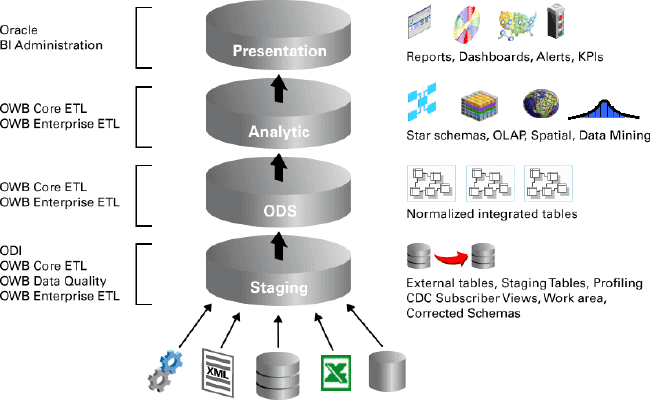
Oracle Data Integrator can integrate and synthesize data from numerous disparate datasources, including Web services and event-based architectures, and, as shown in the figure above, provides a handy graphical interface on top of Oracle Database-specific features such as Oracle Change Data Capture. Once data has been integrated and copied into your data warehouse staging area, Oracle Warehouse Builder can take over and create and populate your operational data store and dimensional warehouse layers.
Now that Oracle Data Integrator has been introduced, this article looks at how it is used in a real-life data integration scenario.
Oracle Data Integrator in Use: Cross-Platform Real-Time Data Integration
In this scenario, you have been tasked with taking some orders and customer data from an Oracle database, combining it with some employee data held in a file, and then loading the integrated data into a Microsoft SQL Server 2000 database. Because orders need to be analyzed as they arrive, you want to pass these through to the target database in as close to real time as possible and extract only the new and changed data to keep the workload as small as possible. You have read about Oracle Data Integrator on the Oracle Technology Network and want to use this new tool to extract and load your data.
You first log in to Oracle Data Integrator and start Topology Manager, as shown in the following figure.
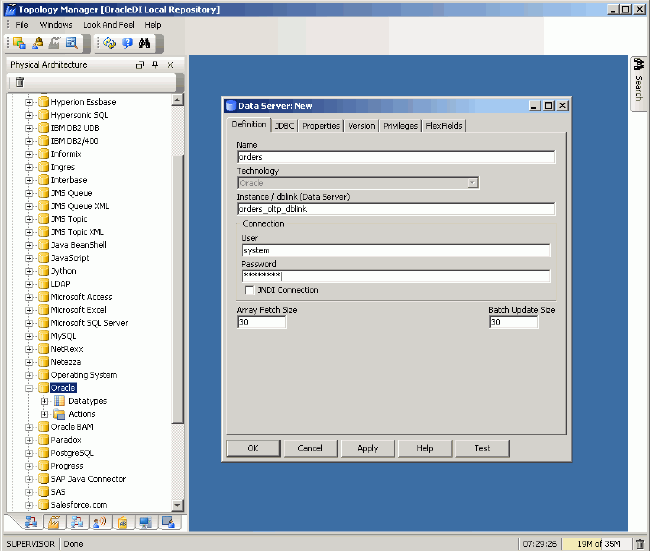
In Oracle Data Integrator, a physical database, a service, or an event-based datasource is known as a data server. Using the Topology Manager, you create three new data servers:
- 1. An Oracle Database data server, set up with the SYSTEM users’ credentials, that maps to the ORDERS and ORDERS_WORKAREA schemas on the database. The ORDERS schema contains the orders data you want to extract, whereas the ORDERS_WORKAREA schema is one you have specially set up, as an empty schema, to hold the working tables Oracle Data Integrator creates. Use the Oracle JDBC driver to make this connection.
- 2. A File data server that maps to a comma-separated file containing details on employees. Use the Sunopsis File JDBC Driver to make this connection.
- 3. A Microsoft SQL Server data server that maps to a database called ORDERS_DATA_MART. Use the Sun JDBC-ODBC Bridge JDBC Driver to create this connection, or use the Microsoft JDBC drivers, which you can download from the Microsoft Web site.
Once the data servers are defined, you leave Topology Manager and start up the Designer. Using Designer, you create data models to represent the Oracle, file, and Microsoft SQL Server tables and files, which are referred to as data stores in Oracle Data Integrator. Create the Oracle and Microsoft SQL Server models first, and then use the Reverse feature to import the table metadata into Oracle Data Integrator’s repository, as shown in the following figure.
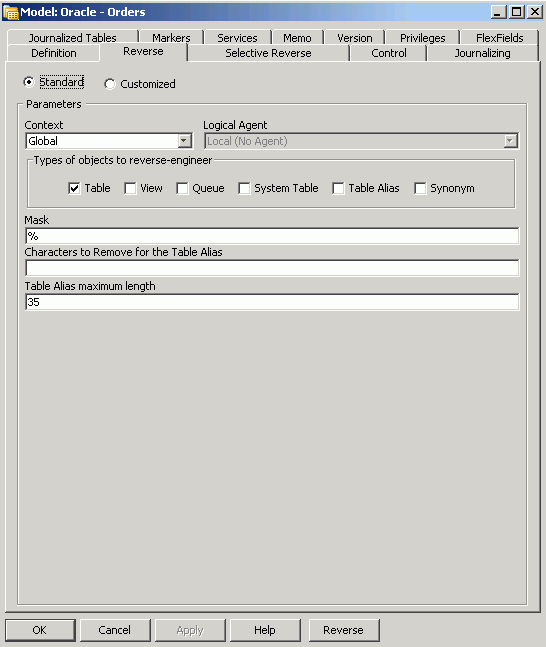
Once all your data models are defined and you have either reverse-engineered or manually entered the details of the source and target tables and files, Designer will display a list of all the data stores you will now use in your project, as shown in the following figure.
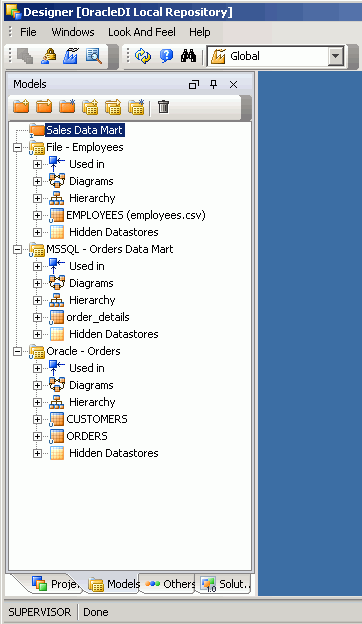
Make sure that if the underlying source tables do not have primary keys defined, you define them, by using the Designer application, and have Oracle Data Integrator enforce them “virtually,” because many of Oracle Data Integrator’s mapping features rely on constraints’ being defined
Now that the data stores are defined, you can start setting up the changed-data-capture process that obtains your source data.
Before you do this, though, you import into your project the knowledge module that provides the changed-data-capture functionality. To do this, you click the Projects tab in the Designer application, right-click the project, and choose Import-> Import Knowledge Modules. From the list, select the following knowledge modules, which provide changed-data-capture functionality and will be used in other parts of the project.
- CKM SQL
- IKM SQL Incremental Update
- JKM Oracle 10g Consistent (LOGMINER)
- LKM File to SQL
- LKM SQL to SQL
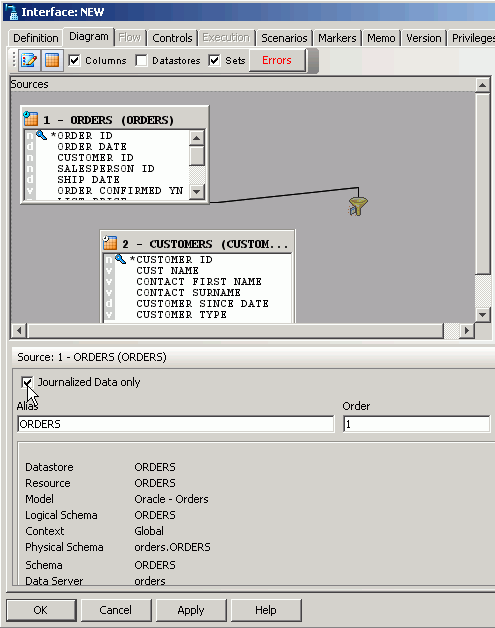
Now that the required knowledge modules are available, you edit the Oracle module created previously and select the Journalizing tab. Because you want to capture changes to the ORDERS and CUSTOMER tables in a consistent fashion, you select the Consistent option and the JKM Oracle 10g Consistent (LOGMINER) knowledge module. This knowledge module, shown in the figure below, will capture new and changed data, using the LogMiner feature of Oracle Database 10g, and will asynchronously propagate changes across a queue using Oracle Streams.
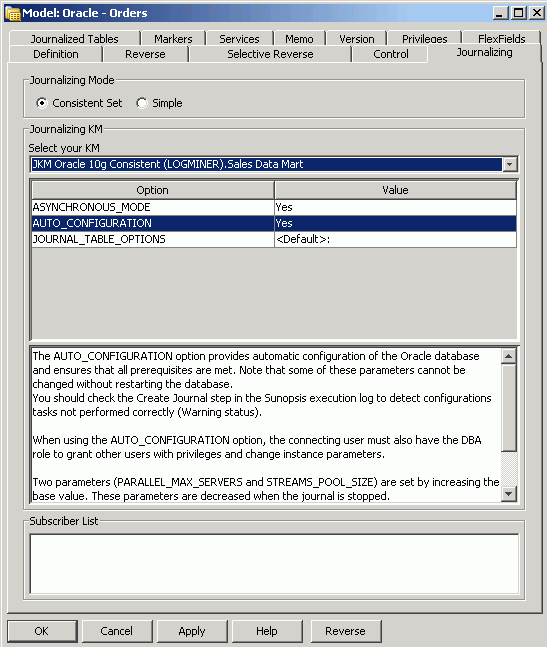
This knowledge module presents three configuration options. You select the following values to configure the module:
- Asynchronous Mode: Yes
- Auto-Configuration: Yes
- Journal Table Options: default
Click Apply to save the changes, and then click OK to complete the configuration. You now need to add tables to the changed-data-capture set.
To do this, you locate the Oracle data server in the Designer list of models, right-click the CUSTOMERS and ORDERS tables in turn, and choose Changed Data Capture -> Add to CDC. Then edit the model again the Journalized Tables tab, and use the up and down arrow keys to place the ORDERS table above the CUSTOMERS table.
You are now ready to create the journal that captures changed data from these two tables. To do this, right-click the model again and choose Changed Data Capture ->Start Journal. Click OK to execute the code locally, and then start up the Operator application to check the progress of the operation. If all has gone well, you will be presented with a list of completed steps similar to the following.
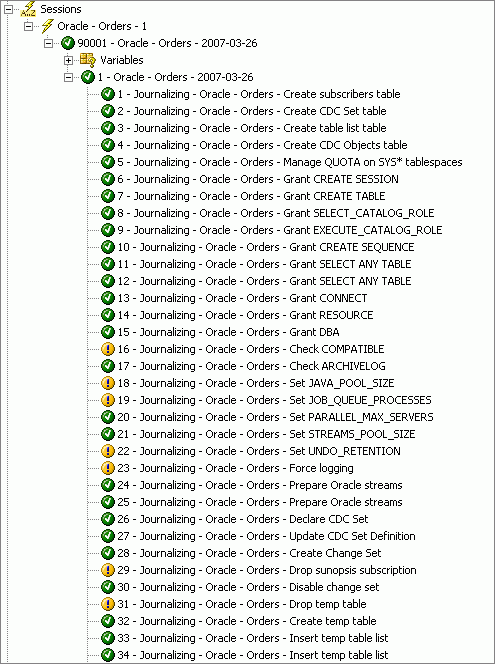
If the process encounters errors, it is usually because you have defined your Oracle connection by using a user account that does not have the required privileges. Check the user details you supplied and the Oracle Data Integrator documentation to resolve any errors before moving on to the remainder of the exercise.
Next you add a subscriber to the journal by returning to the Designer application, right-clicking the Oracle source data server, and choosingChanged Data Capture -> Subscriber-> Subscribe. You add a new subscriber and execute the code locally to ensure that the code executes correctly (some operations may raise warnings, because the required tables were already created in the previous step). Once this step is complete, you have set up the changed-data capture process and you are ready to begin building your interfaces.
This project requires two interfaces, the first of which takes the existing set of data from the Oracle source database, joins it with data in the source file, and loads it into the target Microsoft SQL Server database, as shown in the figure below.
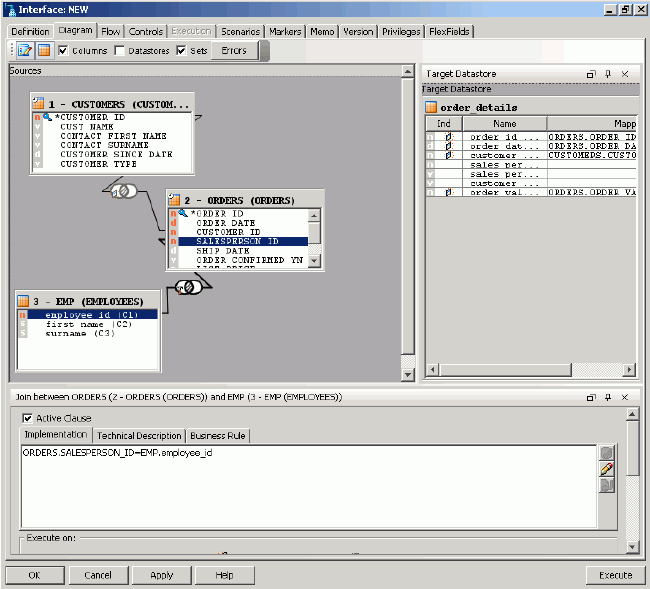
Note that some of the columns in the target table have been automatically mapped but that others, such as SALES_PERSON_ID, SALES_PERSON_NAME and CUSTOMER_NAME, are initially unmapped because the mapping process could not find a matching source column. You will now manually map these other columns, using the expression editor to enter SQL expressions using the syntax of either the source or target databases, depending on where the transformation takes place.
If you click the Flow tab, you will be able to see the actual knowledge modules that are used to load and then integrate your data, as shown in the figure below.
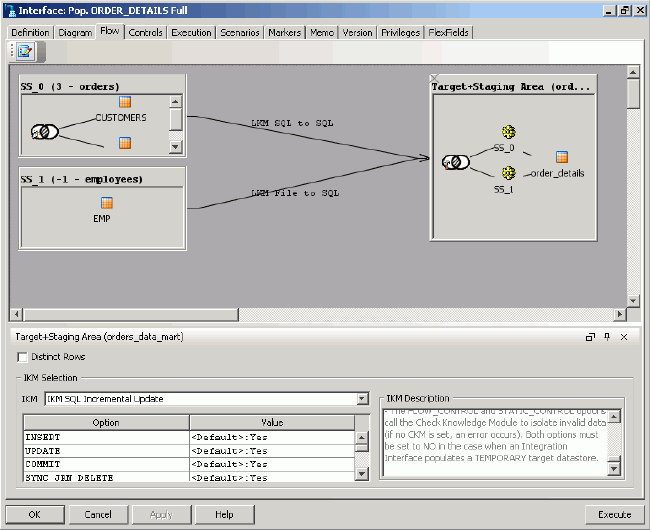
Oracle Data Integrator has chosen default knowledge modules to enable data to be extracted from any database and file and then incrementally loaded into any database. Later you can change these knowledge modules to ones more suited to your particular database and version, but for now you leave these as the default.
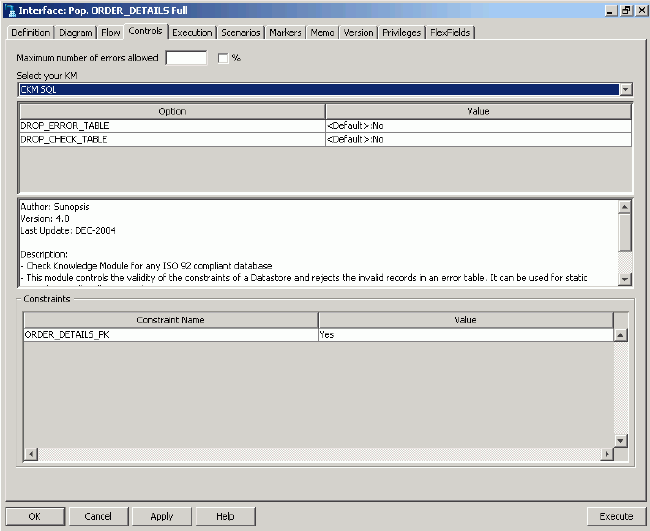
Finally, as shown in the following figure, click the Control tab to select the Control Knowledge Module, used for handling constraint errors in the target table. Select the CKM SQL Knowledge Module, which will handle erroneous data for any ISO-92-compliant database.
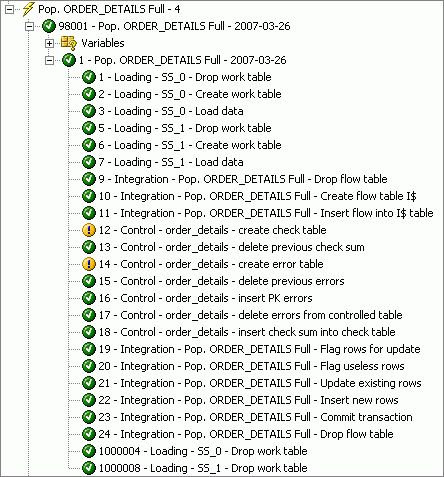
You are now ready to test your interface. To do this, click Execute at the bottom right corner of the interface dialog and then open to the Operator application to check the progress of the interface, which is shown in the figure below.
Because the interface has executed without errors, you navigate to the target data store in the Designer application and view the loaded data, as shown in the following figure.
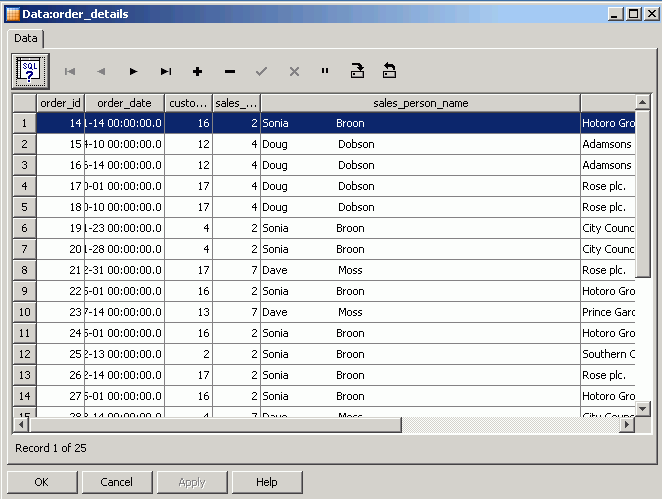
Now that you have set up your initial load, you can define the interface to load new and changed data via the Journal tables you created earlier.
To do this, you create another interface, but this time when you add the CUSTOMERS and ORDERS source tables, click the check box to indicate that journaled data is used rather than the data store contents, as shown in the figure below.
Once the journaled tables are added to the interface, you construct the remainder of the interface in exactly the same way as the previous one, with the only difference being that the second interface sources data from the journalized data instead of the source table.
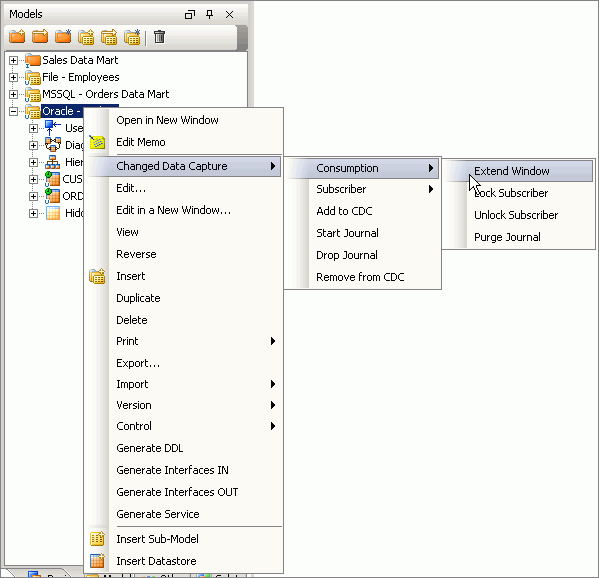
To test this second interface, you insert some new records into the ORDERS and CUSTOMERS tables and then use the Designer interface to extend the journal window; later you will extend the window automatically and then purge it as part of an Oracle Data Integrator package. For now, though, you right-click the Oracle data model and choose Changed Data-> Consumption-> Extend Window from the context menu to make the latest set of new and changed data available to the second interface, as shown in the following figure.
You can quickly check which rows are in the table journals by right-clicking the relevant data store, choosing Changed Data Capture and then Journal Data…, or you can execute the interface by opening it again in the editor and clicking Execute at the bottom right corner of the screen. Note that if you have chosen Asynchronous mode for your JKM, there may be a delay of between a second and a few minutes before your journalized data is ready whilst the data is being transferred asynchronously between the source and target databases. If you require your journalized data to be available immediately, choose Synchronous mode instead and your data will be captured and transferred using internal triggers.
Because you have already loaded the initial set of data into your target data mart, using the first interface you created, you now create a Oracle Data Integrator package to carry out the following steps:
- 1. Check the ORDERS and CUSTOMER journalized data to see if new or changed data records have been added. Once a predefined number of journal records are detected, run the rest of the package or jump to the last step without loading any data.
- 2. If journalized data is detected, extend the journal window.
- 3. Execute the interface to read from the journalized data, join it to the file, and load the target data store.
- 4. Purge the journal window.
- 5. Start this package again.
Creating this package and then deploying it as an Oracle Data Integrator scenario effectively creates a real-time, continuously running ETL process. Using Oracle Data Integrator’s event detection feature, it will start itself, once a set number of changed data records is detected or after a set number of milliseconds has elapsed. By setting appropriate thresholds for the amount of journalized data and the timeout, you can create a real-time integration process with minimal latency.
To create this package, you navigate to the Projects tab in the Designer application, locate the folder containing the interfaces you defined earlier, find the Packages entry, right-click it, and select Insert Package. You give the package a name and then navigate to the Diagram tab in the package details dialog box.
Using the toolbox on the right, you go to the Event Detection folder and add the OdiWaitForLogData tool to the package canvas, as shown in the figure below. This tool will poll the journalized data on a regular basis and then either fail, if no rows are found, or hand off to the next step in the package when a set number of rows has been detected in the journal.
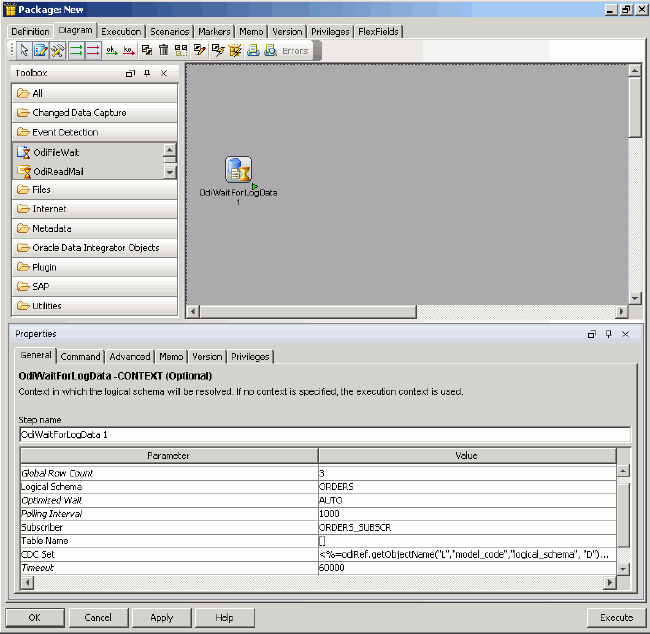
You set the tool properties to check the changed-data-capture set you defined earlier and to exit when either a total of three journal rows is found or one minute has passed since checking began.
Now you add a step to extend the journal window to read in the new data. To do this, you navigate to the list of models and drag and drop the Oracle model onto the canvas. You select the model, view the properties, and then change the Model Type list to Journalizing Model, as shown in the figure below.
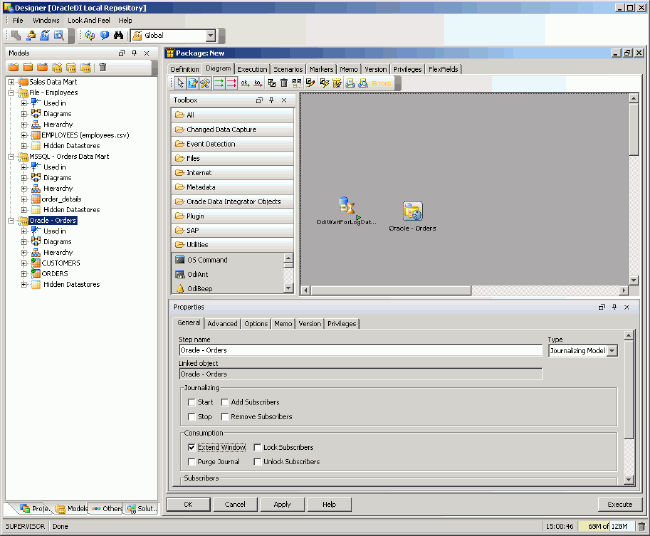
Then you click the Extend Window check box to indicate that the journal step is one that extends the journal window.
Next you add the interface that takes data from the journals to the mapping and then add the Oracle model to the package again, but this time select the Purge Window option to purge the journal after reading it. Finally you add the OdiStartScen tool from the Utilities folder in the toolbox to restart again once it completes and also add connectors to show the flow of steps, as shown in the following figure, depending on whether the first step detects journal rows or not.
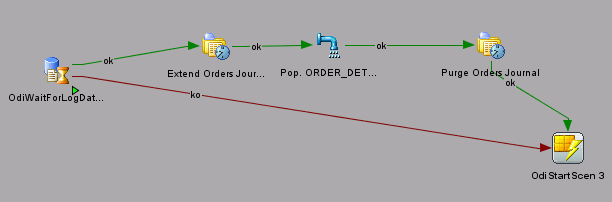
Because the final OdiStartScen step refers to scenarios, which are productionized versions of packages, you locate the package you are working on in the Project tab of the Designer application, right-click it, and select Generate Scenario. Once the scenario is created, you edit the properties of the OdiStartScen step to reference the scenario name you just generated. By adding this final step to the package, you will ensure that it runs continuously, propagating new and changed data from the Oracle source tables across to the target database in real time.
Summary
Oracle Data Integrator, a new addition to the Oracle Fusion Middleware family of products, gives you the ability to perform data, event, and service-oriented integration across a wide number of platforms. It complements Oracle Warehouse Builder and provides a graphical interface for Oracle Database-specific features such as bulk data loading and Oracle Change Data Capture. This article has examined how Oracle Data Integrator can be used to create real-time data integration processes across disparate platforms, and the declarative approach to the integration process allows you to focus on the business rules rather than the details of implementation.
Mark Rittman [ http://www.rittmanmead.com/blog] is an Oracle ACE Director and cofounder of Rittman Mead Consulting, a specialist Oracle Partner based in the U.K. focused on Oracle business intelligence and data warehousing. He is a regular contributor to OTN and the OTN Forums and is one of the authors of the Oracle Press book Oracle Business Intelligence Suite Developers’ Guide, forthcoming in 2008.