How to Optimize Your Enterprise Storage with Oracle Solaris ZFS
by Cindy Swearingen
Published July 2014 (updated July 2015)
How to reduce the footprint of enterprise storage while hosting important data on the fastest storage and archiving other data on standard storage.
Introduction
At a time when cloud data storage needs are exploding, Oracle Solaris ZFS provides integrated features to reduce your storage footprint. ZFS also provides a flexible tiered storage model so that you can host important data on your fastest storage devices as well as compress and archive less-important data on standard storage devices.
Oracle Solaris ZFS provides the following ways to optimize your storage requirements in Oracle Solaris 11:
-
ZFS compression reduces storage footprints by reducing the number of bits that are needed to store data. Enabling LZJB compression, the default ZFS compression algorithm, provides good compression ratios without adversely impacting system performance on enterprise-level systems.
Oracle Solaris 11.3 includes the LZ4 compression algorithm, which has a better compression ratio than LZJB and is generally faster (reduced CPU overhead).
Oracle Solaris customers are reporting ZFS compression ratios in the 2x to 18x range, depending on the compressible workload. If you haven't tried ZFS compression previously because you were concerned about CPU overhead, consider enabling LZ4 (
lz4) compression. - ZFS deduplication. When the deduplication (
dedup) property is enabled on a ZFS file system, duplicate data blocks are removed as they are written to disk. Enabling deduplication consumes system and memory resources, so you must determine whether your data is dedupable and your system has enough resources to support the deduplication process. - ZFS pooled storage flexibility. Consider putting your most-important and active data in ZFS storage pools on your fastest disks. Also consider archiving less-important data in ZFS storage pools on standard storage devices with compression enabled.
Enabling ZFS Data Compression
Use the following procedure to enable the default ZFS compression algorithm (lzjb), which generally reduces storage footprints on enterprise-level systems, as shown in Figure 1, without adversely impacting system performance.

Figure 1. Reducing storage footprints using ZFS compression
-
Determine whether your data is compressible:
-
Create a new file system for a sample data file:
# zfs create tank/data -
Copy a sample data file into the new file system:
# cp file.1 /tank/data/file.1 -
Display the size of the new file system:
# zfs list tank/data -
Display the available compression algorithms:
# zfs help compression compression (property) Editable, Inheritable Accepted values: on | off | lzjb | gzip | gzip-[1-9] | zle | lz4 -
Create another new file system with compression enabled:
# zfs create -o compression=on tank/newdata -
Copy the same sample data file into the new file system that has compression enabled, and display the size of the first new file system:
# cp /tank/data/file.1 /tank/newdata/file.1 # zfs list tank/data -
Display the size of the file system that has compression enabled:
# zfs list tank/newdata -
Compare the sizes shown in the
zfs listoutput for the two file systems:The size of the compressed data should be 2x–3x less than the original size of the file. If your sample data is not compressible, enabling ZFS compression is not a good fit for your data.
-
Create a new file system for a sample data file:
-
If your data is compressible, enable compression on a new file system and copy your data into the new file system, or enable compression on an existing file system:
# zfs create -o compression=on tank/newdataKeep in mind that if you enable compression on an existing file system, only new data is compressed.
Enabling ZFS Data Deduplication
If a ZFS file system has the dedup property enabled, duplicate data blocks are removed as data blocks are written to disk. The result is that only unique data is stored on disk and common components are shared between files, as shown in Figure 2.

Figure 2. Example of how duplicate data blocks are removed when deduplication is enabled
Deduplication can result in savings in disk space usage and cost. However, before enabling deduplication, you must ensure your data is dedupable and your system meets the memory requirements.
If your data is not dedupable, there is no point in enabling deduplication and doing so will waste CPU resources. ZFS deduplication is in-band, which means deduplication occurs when you write data to disk and impacts both CPU and memory resources.
Deduplication tables (DDTs) consume memory and eventually spill over and consume disk space. At that point, ZFS has to perform extra read and write operations for every block of data on which deduplication is attempted. This causes a reduction in performance.
A system with a large data pool and a small amount of physical memory does not perform deduplication well. Some operations, such as removing a large file system with deduplication enabled, severely decrease system performance if the system doesn't meet the memory requirements.
Also, consider whether enabling compression on your file systems would provide a better way to reduce disk space consumption.
-
Run the
zdbcommand to determine whether the data in your file system is dedupable.If the estimated deduplication ratio is greater than 2, you might see space savings. In the example shown in Listing 1, the ratio is less than 2, so enabling deduplication is not recommended.
# zdb -S tankSimulated DDT histogram: bucket allocated referenced ______ ______________________________ ______________________________ refcnt blocks LSIZE PSIZE DSIZE blocks LSIZE PSIZE DSIZE ------ ------ ----- ----- ----- ------ ----- ----- ----- 1 1.00M 126G 126G 126G 1.00M 126G 126G 126G 2 11.8K 573M 573M 573M 23.9K 1.12G 1.12G 1.12G 4 370 418K 418K 418K 1.79K 1.93M 1.93M 1.93M 8 127 194K 194K 194K 1.25K 2.39M 2.39M 2.39M 16 43 22.5K 22.5K 22.5K 879 456K 456K 456K 32 12 6K 6K 6K 515 258K 258K 258K 64 4 2K 2K 2K 318 159K 159K 159K 128 1 512 512 512 200 100K 100K 100K Total 1.02M 127G 127G 127G 1.03M 127G 127G 127G dedup = 1.00, compress = 1.00, copies = 1.00, dedup * compress / copies = 1.00Listing 1
-
Determine whether your system has enough memory to support deduplication operations.
Each in-core DDT block is approximately 320 bytes. So multiply the number of allocated blocks by 320. Here's an example using the data from Listing 1:
In-core DDT size (1.02M) x 320 = 326.4 MB of memory is required.
-
Enable the
dedupproperty.
Be sure you enable
deduponly for file systems that have dedupable data.# zfs set dedup=on mypool/myfs
Optimizing Data Placement Using ZFS Pooled Storage
ZFS provides options for configuring flexible, tiered storage pools to optimize your enterprise storage, as shown in Figure 3.
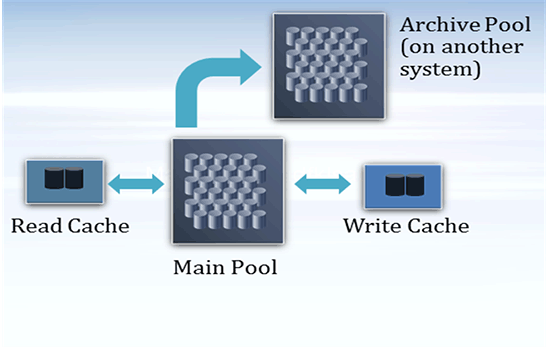
Figure 3. Example of tiered storage pools
Use the following procedure to configure tiered storage pools:
-
Optimize data placement by putting your most-important and active data on the fastest storage devices.
Mirrored pools provide the best performance for most workloads. For example, the following syntax creates a mirrored ZFS storage pool,
tank, with two mirrored components of two disks each and one spare disk:# zpool create tank mirror disk1 disk2 mirror disk3 disk4 spare disk5 -
Place archive data on standard storage devices in a pool on another system.
A RAIDZ pool is a good choice for archive data. For example, the following syntax creates a RAIDZ-2 pool,
rzpool, with one RAIDZ-2 component of five disks and one spare disk. When the snapshot stream is sent to the new pool, we also enable compression on the receiving file system:# zpool create rzpool raidz2 disk1 disk2 disk3 disk4 disk5 spare disk6 # zfs snapshot -r tank/old_data@date # zfs send -Rv tank/old_data@date | ssh sys-B zfs receive -o compression=on rzpool/oldtankdata # zfs destroy -r tank/old_data@dateNote: You must be configured to use
sshon the other system. -
Optimize data performance by putting active data from write or read workloads on high-performance solid-state disks (SSDs), for example:
-
Add SSDs as cache devices to improve read workloads:
# zpool add tank cache ssd-1 ssd-2 -
Add SSDs as log devices to improve synchronous write workloads:
# zpool add nfspool log mirror ssd-1 ssd-2
-
Add SSDs as cache devices to improve read workloads:
Conclusion
This article described the flexible ways that you can use ZFS to reduce your storage footprint and optimize your data storage in Oracle Solaris 11. Consider which one works best for your application data workload and your storage and system resources.
See Also
- Download Oracle Solaris 11
- Access Oracle Solaris 11 product documentation
- Access all Oracle Solaris 11 how-to articles
- Learn more with Oracle Solaris 11 training and support
- See the official Oracle Solaris blog
- Check out The Observatory blogs for Oracle Solaris tips and tricks
- Follow Oracle Solaris on Facebook and Twitter
About the Author
Cindy Swearingen is an Oracle Solaris Product Manager who specializes in ZFS and storage features.
Revision 1.0, 07/14/2014
Updated for Oracle Solaris 11.3