Oracle Cloud Infrastructure (OCI)
Le cloud nouvelle génération conçu pour exécuter toutes les applications, plus rapidement et de manière plus sécurisée, avec moins de ressources.


Explore the AI trends that will impact business in 2026
Join our webinar series to learn how your organization can stay prepared.
-
![]() Annonce de la disponibilité générale d'Oracle Database@AWS
Annonce de la disponibilité générale d'Oracle Database@AWS
Migrez facilement et rapidement vos workloads Oracle Exadata vers AWS.
-
![]() Oracle nommé leader dans l'édition 2025 du Gartner® Magic QuadrantTM pour les services Platform Cloud stratégiques
Oracle nommé leader dans l'édition 2025 du Gartner® Magic QuadrantTM pour les services Platform Cloud stratégiques
Oracle est le seul hyperscaler capable de fournir plus de 200 services d'IA et de cloud dans des environnements cloud publics, dédiés et hybrides, partout dans le monde. Lisez le rapport pour découvrir pourquoi Oracle est nommé leader.
-
![]() Maîtriser les complexités de l'IA générative
Maîtriser les complexités de l'IA générative
Une infrastructure cloud appropriée est essentielle pour réussir l'adoption de l'IA générative. Découvrir les recommandations d'IDC.


Oracle est nommé leader dans le MarketScape IDC 2025 pour l'infrastructure de cloud public en tant que service dans le monde entier.
Un cloud distribué disponible partout où vous en avez besoin
L'unique cloud à proposer des services cloud complets à travers le monde, entre les clouds ou dans votre data center.
1. Multicloud
Faites fonctionner plusieurs clouds comme un seul cloud. Oracle propose une intégration directe des bases de données avec Microsoft Azure ainsi qu'une interconnexion à hautes performances.
En savoir plus sur le multicloud2. Cloud public
Le seul et unique cloud avec des services cohérents et des prix bas constants dans les régions de cloud public commerciales et gouvernementales.
En savoir plus sur le cloud public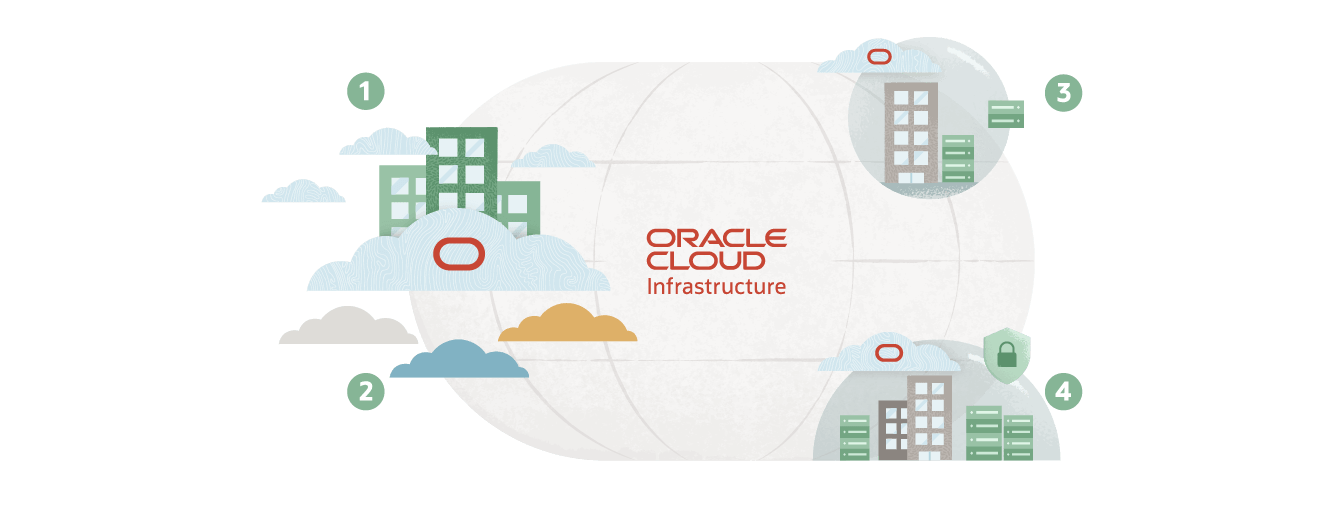
3. Cloud hybride
Solutions cloud fiables pour presque tous les sites, y compris Oracle Exadata Cloud@Customer, une base de données hautement optimisée en tant que service déjà déployée dans plus de 60 pays.
En savoir plus sur le cloud hybride4. Cloud dédié
OCI Dedicated Region et Oracle Alloy sont les seuls produits qui fournissent plus de 100 services cloud à des tarifs de cloud public entièrement dans vos data centers.
En savoir plus sur le cloud dédié Découvrez comment tirer le meilleur parti de l'IA pour votre entreprise
lors d'un forum Oracle sur les données et l'IA.
Services complets d'infrastructure et de plateforme cloud pour toutes les charges de travail
OCI propose un ensemble commun de plus de 150 services cloud dans chaque région cloud. Bénéficiez de tous les services dont vous avez besoin, des conteneurs à l'IA en passant par VMware, pour migrer, moderniser, développer et faire évoluer votre infrastructure informatique. Automatisez l'ensemble de vos charges de travail, y compris les applications existantes et nouvelles, ainsi que les plateformes de données.
Services aux développeurs
Développez, déployez et gérez des applications cloud modernes à l'aide d'outils et de services conviviaux pour les développeurs.
Construire et exécuter
Code minimal
Services d'intégration
Les services d'intégration Oracle Cloud Infrastructure connectent toutes les applications et sources de données afin d'automatiser les processus de bout en bout et de centraliser la gestion. La vaste gamme d'intégrations, avec des adaptateurs préconfigurés et une personnalisation à faible code, simplifie la migration vers le cloud tout en rationalisant les opérations hybrides et multicloud.
Intégration des applications
Data integration
Automatisation des processus
Gestion complète du cycle de vie des API
Basé sur les événements
Analytique et BI
Bénéficiez d'une intelligence économique complète grâce à l'analyse augmentée pour aider votre organisation à se développer grâce à des informations uniques.
IA et machine learning
Ajoutez facilement de l'intelligence à vos applications et à vos charges de travail grâce à des modèles de perception et de décision prédéfinis et à des chatbots prêts à l'emploi, ou créez et formez vos propres modèles à l'aide de nos services de science des données.
IA générative
Services de ML
Services de médias
Mégadonnées et lac de données
Obtenez de nouvelles informations à partir de l'ensemble de vos données grâce à notre plateforme complète de services gérés compatibles avec Spark, Hadoop, Elasticsearch et Kafka, associée à des services de gestion et d'entreposage de données de premier ordre.
Compute
Capacité de calcul sécurisée et élastique dans le cloud, allant des machines virtuelles flexibles (Flex VM) et des serveurs bare metal hautes performances aux serveurs HPC et GPU.
Stockage
Répondez aux principaux cas d'utilisation grâce au stockage local, objet, fichier, bloc et archive à la demande.
Conteneurs et fonctions
Déployez des applications de microservices sur des services Docker, Kubernetes et Fn Functions open source, gérés et hautement performants.
Réseautage
Connectez-vous en toute sécurité à un réseau cloud virtuel (VCN) personnalisable et isolé, qui constituera le cœur de votre déploiement cloud. Transférez vos données à 25 % du coût pratiqué par d'autres fournisseurs de services cloud.
Bases de données Oracle
Exécutez des versions optimisées pour les coûts, à hautes performances et autonomes d'Oracle AI Database, le premier système de gestion de bases de données convergées et multimodèles au monde dans le cloud.
- Autonomous AI Database
- Autonomous AI Database on Exadata Cloud@Customer
- Intégrateur de données
- Sécurité des données
- Gestion de bases de données
- Migration de base de données
- Oracle Database@Azure
- Oracle Database@Google Cloud
- Service de base de données pour Azure
- Service de base de données d'entreprise
- Exadata Cloud@Customer
- Exadata Database Service
- Autonomous AI Database distribuée mondialement
- GoldenGate
- NoSQL
- Ops Insights
- Service de base de données standard
- Service de récupération autonome sans perte de données
Bases de données open source
HeatWave MySQL est un service de base de données entièrement géré, optimisé par l'accélérateur de requêtes en mémoire HeatWave intégré. Il s'agit du seul service de base de données cloud qui combine des services de transactions, d'analyse et de machine learning dans une seule base de données MySQL, offrant ainsi des analyses sécurisées en temps réel sans la complexité, la latence et le coût liés à la duplication ETL.
Sécurité, observabilité et gestion, conformité, gestion des coûts et gouvernance
Protégez vos données les plus précieuses dans le cloud grâce à l'approche axée sur la sécurité et aux programmes de conformité complets d'Oracle. Oracle offre une visibilité et des informations basées sur le machine learning afin de faciliter la gestion à tous les niveaux de la pile, quelle que soit la technologie utilisée et où qu'elle se trouve.
Sécurité de l'infrastructure cloud
Sécurité des bases de données dans le cloud
Sécurité des applications cloud
Observabilité et gestion
- Surveillance des performances des applications
- Connector Hub
- Gestion de bases de données
- Gestion des demandes relatives à la flotte
- Reprise après sinistre complète
- Gestion Java
- Données de connexion
- Log Analytics
- Surveillance
- Surveillance de la pile
- Notifications
- Ops Insights
- Centre de gestion du système d'exploitation
- Gestionnaire de ressources
Gestion des coûts et gouvernance
Infrastructure mondiale de centres de données dans le cloud
Environnements mondiaux, sécurisés et performants pour déplacer, créer et exécuter toutes vos charges de travail. Les offres hybrides et périphériques offrent un déploiement spécialisé, un fonctionnement déconnecté et intermittent, une faible latence et des performances élevées, ainsi que la localisation et la sécurité des données.
Économisez considérablement sur les services de base
OCI propose les mêmes prix bas dans toutes les régions cloud, y compris les régions gouvernementales et dédiées.
50 % de moins
Pour le calcul
70 % de moins
Pour le stockage par blocs
80 % de moins
Pour la mise en réseau
Calcul : comparaison avec le coût d'un AMD (E4) à deux OCPU (4 vCPU) avec 16 Go sur une période d'un mois.
Stockage par blocs : par rapport au coût de 1 To, IOPS 25K et débit de 240 Mo/s sur une période d'un mois.
Sortie de mise en réseau : par rapport au coût de 50 To de sortie sur l'Internet public sur une période d'un mois.
Les prix à la demande sont en date du 13 septembre 2024 dans la région de l'est des États-Unis. Consultez Cloud Economics pour plus de détails.
Des infrastructures et des applications cloud disponibles partout
Oracle Cloud couvre 50 régions cloud commerciales et gouvernementales géographiques interconnectées. Chaque région offre un ensemble cohérent de plus de 150 services Oracle Cloud Infrastructure, avec des tarifs faibles constants dans le monde entier. Pour une prise en charge plus complète des stratégies cloud des clients, Oracle Cloud offre également une suite complète d'applications Oracle Cloud et une interconnexion directe avec Microsoft Azure et Google Cloud.
Découvrez comment Oracle Cloud Infrastructure accélère les workloads d'IA.
Vos premiers pas avec OCI
Testez plus de 20 services cloud Always Free grâce à une période d'essai de 30 jours pour encore plus de services
Oracle propose une offre gratuite sans limite de temps sur plus de 20 services tels que Oracle Autonomous AI Database, Arm Compute et Storage, ainsi que 300 dollars américains de crédits gratuits pour essayer d'autres services cloud. Obtenez les détails et créez votre compte gratuit dès aujourd’hui.
-
Que comprend Oracle Cloud Free Tier ?
- 2 instances Autonomous AI Database, 20 Go chacune
- AMD et Arm Compute VM
- 200 Go de stockage total par blocs
- 10 Go de stockage d'objets
- 10 To de transfert de données sortantes par mois
- Plus de 10 services Always Free
- 300 USD de crédits gratuits pendant 30 heures pour plus de possibilités
Suivez le guide
Découvrez un large éventail de services OCI via des tutoriels et des ateliers pratiques. Que vous soyez développeur, administrateur ou analyste, nous pouvons vous aider à comprendre comment fonctionne OCI. De nombreux ateliers sont disponibles pour Oracle Cloud Free Tier ou dans un environnement d'ateliers gratuits fournis par Oracle.
-
Introduction aux services fondamentaux d'OCI
Les ateliers de cette session présentent les services principaux d'Oracle Cloud Infrastructure (OCI), y compris les réseaux cloud virtuels (VCN) ainsi que les services de calcul et de stockage.
Commencer l'atelier sur les services principaux d'OCI -
Guide de démarrage rapide de Autonomous AI Database
Au cours de cet atelier, vous découvrirez les étapes à suivre pour commencer à utiliser Oracle Autonomous AI Database.
Commencez dès maintenant le laboratoire de démarrage rapide de Autonomous AI Database. -
Créez une application à partir d'une feuille de calcul
Cet atelier vous explique pas à pas comment télécharger une feuille de calcul dans un tableau d'Oracle Database et comment créer ensuite une application à partir de ce nouveau tableau.
Commencer cet atelier -
Déployez une application HA sur OCI
Dans cet atelier, vous apprendrez à déployer des serveurs Web sur deux instances de calcul dans Oracle Cloud Infrastructure (OCI), configurés en mode haute disponibilité grâce à l'utilisation d'un équilibreur de charges.
Commencez l'atelier sur les applications HA
Découvrez plus de 150 modèles de bonnes pratiques
Découvrez comment nos architectes et d’autres clients déploient une large gamme de workloads, des applications d’entreprise au HPC, des microservices aux lacs de données. Comprenez les bonnes pratiques, écoutez d’autres architectes clients de notre série « Développer et Déployer » et déployez même de nombreux workloads avec notre fonctionnalité de déploiement en un clic ou faites-le vous-même à partir de notre dépôt GitHub.
Architectures populaires
- Apache Tomcat avec MySQL Database Service
- Oracle Weblogic sur Kubernetes avec Jenkins
- Environnements de machine learning (ML) et d'IA
- Tomcat sur Arm avec Oracle Autonomous AI Database
- Analyse des journaux avec la pile ELK
- HPC avec OpenFOAM
Parcourez nos séries d'événements informatifs. Vous y découvrirez des annonces sur les nouveautés, des échanges avec nos clients, des analyses orientées produits, des sessions techniques et des ateliers pratiques.
-
Événements Oracle Cloud Infrastructure
Exploitez au maximum OCI avec une large gamme d'événements en direct et à la demande.
En savoir plus sur les événements OCI -
Oracle AI World
Rejoignez-nous à la conférence mondiale des clients et partenaires d'Oracle à propos de l'infrastructure et des applications cloud.
En savoir plus sur Oracle AI World
Contactez l’équipe commerciale
Vous souhaitez en savoir plus sur Oracle Cloud Infrastructure ? Laissez l’un de nos experts vous aider.
-
Il peut répondre à des questions telles que :