Technical Article
Basic Java Persistence API Best Practices
Developer: Java
By Dustin Marx, Published May 2008
Consider and employ these simple approaches to make your Java Persistence API applications more maintainable.
The Java Persistence API (JPA), which is part of the Enterprise JavaBeans (EJB) 3.0 spec and is now the standard API for persistence and object/relational mapping for the Java EE platform, provides several advantages to Java developers for data-binding purposes. First, it provides a common API for persistence in both the standard and enterprise Java worlds. Second, the JPA provides a standard API that can be used for multiple different data stores. Third, JPA provides object-relational mapping technology that can be applied in the same manner to these various contexts (standard Java, enterprise Java, and various databases).
This article provides an overview of how to fully enjoy these advantages of the Java Persistence API.
Common Themes Behind These Recommendations
A few general themes permeate most of the recommended approaches outlined in this article:
- The approaches outlined here focus on the readability and maintainability of JPA-based application code.
- Portability between JPA provider implementations is generally desirable. Even when implementation portability cannot be maintained, provider-specific functionality should be easily identifiable and isolated from common functionality.
- JPA code should be portable across datasources. When database-specific features must be used, they should be isolated in configuration files rather than tainting the code.
- JPA-based code should usually work in Java SE and Java EE contexts.
- The most important characteristic of maintainable and readable code is the quality of the code itself. Clean code that speaks for itself is preferable to annotations. Self-explanatory code and annotations are preferable to comments that are necessary to explain convoluted code.
- The practices discussed in this article generally require very little extra effort to implement and provide long-term maintenance benefits at little or no cost in initial development time.
With the general themes listed above in mind, we move on to some recommended practices for effective JPA-based applications.
Favor Conventions over Exceptions
In an ideal world, the default configuration settings would always be exactly what we wanted. Our use of “configuration by exception” would not require any exceptions to be configured. We can approach this ideal world by minimizing the frequency and severity of our deviations from the assumed configuration. Although there is nothing inherently wrong about providing specific exceptions to the default configuration settings, doing so requires more effort on our part to denote and maintain the metadata describing the exceptions to the default configuration.
Carefully Consider and Select a Metadata Configuration Strategy
For many organizations, it makes the most sense to use annotations in the code during development, because in-code configuration is significantly more convenient for developers. For some of these organizations, it may be preferable to use external XML files during deployment and production, especially if the deployment team is different from the development team.
JPA enables XML-based configuration data to be used as an alternative to annotations, but it is even more powerful to use the XML configuration approach to override the annotations. Using the override process enables developers to take advantage of annotations during source code development while allowing these in-code annotations to be overridden outside the code at production time.
As I discussed in significantly greater detail in my OTN article “ Better JPA, Better JAXB, and Better Annotations Processing with Java SE 6,” Java SE 6 provides built-in annotation processing that can be used to build the mapping XML file from the in-code annotations. This approach is appropriate for organizations whose development staff benefits from in-code annotations but whose deployment staff benefits from external configuration.
For configuration that is likely to change often for various deployments of the software, external configuration makes the most sense. For configuration that is fairly static across multiple deployments, in-code annotations can be defined once and there is no need to change them often.
There are some configuration settings that must be expressed in the XML configuration files rather than via in-code annotations. One example of such configuration is the definition of default entity listeners that cover all entities within a persistence unit.
Another situation in which external configuration should be used instead of in-code annotations is for vendor-specific settings. Placing implementation-specific settings in external configuration files keeps the code portable and clean. Generally, JPA vendor-specific properties should be declared with name/value properties in the persistence.xml file rather than within source code.
SQL statements that are specific to a particular database can also be placed outside the source code, in the XML descriptor file. If database-specific SQL statements must be used, it is best to specify them as native named queries and annotate them in XML for the general persistence unit rather than in a particular entity’s Java source code file.
JPA 1.0 specification co-lead Mike Keith covered many of the trade-offs associated with an XML metadata strategy (XML strategy) versus an in-source metadata strategy (annotations strategy) in the OTN column “To Annotate or Not” (see “Additional Resources”).
Access Fields Rather Than Properties
I prefer to specify object-relational mapping by annotating entity fields directly, rather than annotating get/set methods (properties), for several reasons. No single reason overwhelmingly favors specifying persistence via fields rather than via properties, but the combined benefits of field persistence specification make it the more attractive approach.
Because persistence is all about storing, updating, and retrieving the data itself, it seems cleaner to denote the persistence directly on the data rather than indirectly via the get and set methods. There is also no need to remember to mark the getter but not the setter for persistence. It is also cleaner to mark a field as transient to indicate that it should not be persisted than to mark a get() method as transient. By using fields rather than properties, you don’t need to ensure that the get and set methods follow the JavaBeans naming conventions related to the underlying fields. I prefer the ability to look at a class’s data members and determine each member’s name, each member’s datatype, comments related to each data member, and each member’s persistence information all in one location.
The order of business logic and persistence in get/set methods is not guaranteed. Developers can leave business logic out of these methods, but if fields are annotated instead, it does not matter if business logic is added to the get or set methods later.
A developer may want methods that manipulate or retrieve more than one attribute at a time or that do not have “get” or “set” in their names. With field annotations, the developer has the freedom to write and name these methods as desired without the need to place the @Transient annotation or the “transient” keyword in front of methods not directly related to persistence.
Favor @EmbeddedId for Composite Keys
I prefer using @EmbeddedId to designate composite keys, for three main reasons:
1. Use of @EmbeddedId is consistent with use of the @Embedded annotation on embedded Java classes that are not primary keys.
2. @EmbeddedId enables me to represent the composite key as a single key in my entity rather than making me annotate multiple data members in my entity with the @Id annotation.
3. The @EmbeddedId approach provides encapsulation of any @Column or other column mapping on the primary key columns in a single Java class. This is better than forcing the containing entity to handle object-relational mapping details for each column in the composite key.
In short, I prefer the @EmbeddedId approach for composite primary keys because of the grouping of primary-key-related details within the single @Embeddable class. This also makes it simple to access the primary key class as a single, cohesive unit rather than as individual pieces inside an entity.
The ideal approach is to use a single-value key, because this generally requires the least extra effort on the part of the JPA developer.
Use Only Exact Datatypes for Primary Keys
The JPA specification warns against using approximate types, specifically floating types (float and double). In general, my preference with JPA is to use surrogate primary keys that are integers, whenever possible.
Strive for Standard JPA Code
The following general guidelines for maintaining portable JPA code are based on warnings in the JPA specification regarding features that are optional or undefined.
Generally Relate Tables by References to Primary Keys
The JPA specification allows implementations to have columns from one table reference non-primary-key columns of another table, but JPA implementations are not required to support this. Therefore, for applications portable across different JPA implementations, it is best to relate tables via references from one table to the primary key column(s) of the other table. I prefer this as a general database principle anyway.
Use Portable Inheritance Mapping Strategies
Even if your JPA provider does implement the optional “table per concrete class” inheritance mapping strategy, it is best to avoid this if you need JPA provider portability.
It is also best to use a single inheritance mapping strategy within a given Java entity class hierarchy, because support for mixing multiple mapping inheritance strategies within a single class hierarchy is not required of JPA implementations.
Other JPA Implementation Portability Issues
Beyond what is discussed here, the JPA specification points out additional issues to keep in mind when developing portable JPA-based applications. In general, anything cited in the specification as optional, undefined, or ambiguous or specifically called out as nonportable across JPA implementations should be avoided unless absolutely necessary. In many of these cases, the exceptions to portability are not difficult to avoid. (A good resource regarding portable JPA applications is the 2007 JavaOne conference presentation “Java Persistence API: Portability Do’s and Don’ts.” Another good resource on portable JPA applications is the article “Portable Persistence Using the EJB 3.0 Java Persistence API.” Both of these are listed under “Additional Resources.”)
Effectively Use Implementation-Specific Features
There are occasions when a JPA implementation might provide nonstandard features (“extensions”) that are highly useful.
Although it is generally desirable for applications to be as standards-based as possible to improve the ability to migrate them between various implementations of the standard, this does not mean that implementation-specific features should never be used. Instead, the costs and benefits of using an all-standards approach should be compared with the costs and benefits of employing the vendor-specific features.
The following issues should be considered when determining whether to use features and extensions specific to a particular JPA implementation.
- Does the JPA specification outline extension points that allow the vendor option to be used without loss of portability?
- Does the implementation-specific feature provide a significant benefit (better performance, easier development, or extra functionality) over using a more-standard approach?
- What is the likelihood of needing to use a different JPA implementation in the future for this application? Factors to consider include the implementation vendor’s support and future viability, licensing fees, and general experience with the product.
One example of making a trade-off decision by answering these questions is the use of Oracle TopLink Essentials’ logging mechanism in JPA-based applications. I am comfortable using this provider-specific feature, for the following reasons:
- Setting Oracle TopLink Essentials’ logging level to FINE allows SQL statements to be logged, which is invaluable for debugging.
- Oracle TopLink Essentials is the JPA reference implementation.
- JPA provides an extension mechanism for properties such as logging that keeps the provider-specific setting in the external persistence.xml file rather than in source code. This mechanism also ensures that other providers will simply ignore properties specific to Oracle TopLink.
Another example of a highly useful but provider-specific function is the use of the second-level cache, which is often vital to acceptable performance. Information on the reference implementation’s extensions is available in the “TopLink Essentials JPA Extensions Reference” (see “Additional Resources”).
Strive for Standard SQL and Database Use
Using features specific to a certain database is riskier than using features specific to a certain JPA provider, because the database specifics are not typically handled as elegantly as the JPA provider specifics are.
Maintain database independence with standard JPA query language statements. A red flag for database-specific SQL statements in your code is the use of the @NamedNativeQuery and @NamedNativeQueries annotations (or their corresponding XML descriptor elements). Similarly, EntityManager.createNativeQuery method calls also indicate dependence on a specific database.
Effectively Use Database-Specific Features
Even when use of vendor-specific features is warranted, you can take steps to obviously identify and isolate these vendor specifics from the standardized database access.
I prefer to place database-specific queries in the XML deployment descriptors (one or more named-native-query elements) in an attempt to keep my actual code (including annotations) as free from vendor-specific code as possible. This enables me to isolate proprietary database code to the external descriptors rather than mingling it with my standards-oriented code. I also prefer to include my named-native-query XML elements as subelements of the root element of the object-relational mapping file(s), rather than as subelements of any particular entity.
Native named queries are scoped to the entire persistence unit, even when a particular native named query is defined in a particular entity’s Java class, so it is also considered a best practice to include some other unique identifier in the native named query’s name. If you place the native named queries together under the root element in the external XML mapping file, it is easier to visually detect naming collisions. A disadvantage of this approach is that it is less obvious which entity is returned from a query, but you can address this issue by including the returned entity’s name as part of the native named query.
Design JPA Code for Both the Java SE and Java EE Environments
An advantage of finally having a consistent API that works with both standard and enterprise Java is that we can write Java-based persistence layers that work with both standard and enterprise applications.
Effective layering can be used to ensure that our JPA-based database access (DAO) code can be used in both standard and enterprise Java contexts. To do this properly, entity classes and DAO layers should not perform transaction handling, because doing so would conflict with transactions provided by the enterprise Java application server. Transactions need to be pushed out of the entity classes to the client for standard Java environments.
The figure below demonstrates how the same entity class can be used for both standard and enterprise Java environments. Structuring the entities this way requires only a small amount of effort but allows a high degree of reuse of the entity class.
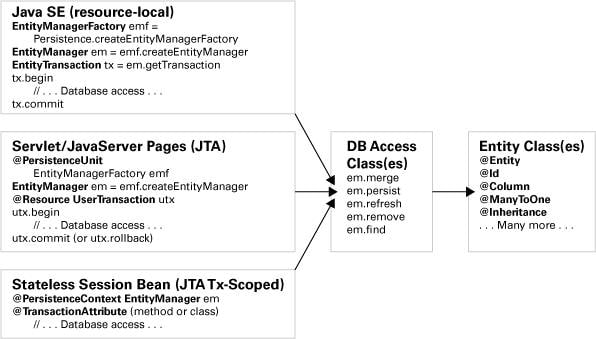
Moving the access of the entity manager back to the layer specific to its host environment and moving the transaction handling back to the same layer specific to the host environment enable the JPA entity classes and the database access layer to be reusable in standard Java environments, in Java EE Web containers, and in Java EE EJB application servers.
Although the graphic above shows JPA transactions and entity manager handling within the Web tier, I typically prefer to keep this functionality in a stateless session bean that is accessible from the Web tier. The graphic shows JPA in the Web tier simply to demonstrate how transactions and entity manager handling can be separated from common JPA and DAO code.
It is important to note that different types of entity managers (application managed and container managed) should not be used at the same time or interchangeably. Also, a single entity manager should not be used across concurrent transactions.
Use JPA Code in the Appropriate Layer
Because the Java Persistence API is intended for database access, it generally should not be used in application tiers other than the business tier. Placing JPA code in the presentation layer typically renders it unusable by any other Java-based application outside of that layer and diminishes one of the key advantages of JPA.
Favor Self-Describing Code over Metadata and Comments
Although comments and annotations can be useful for describing what code needs to do or is expected to do, it is even better when the code can speak for itself.
The “transient” keyword has been a built-in part of the Java programming language for many years and provides a mechanism, in standard Java code, to express that a field should not be persisted. I prefer to denote this exception from persistence with this keyword rather than with the @Transient annotation or XML entry. The one exception is when an entity class needs to have a field be serializable but not persistable. In such a situation, the @Transient annotation (or XML equivalent) is the only appropriate choice.
Use Naming Conventions for More-Readable JPA Code
Naming conventions enable developers to more easily read, maintain, and enhance other developers’ code. Use of JPA-related naming conventions complements use of JPA-related defaults.
Naming conventions can supply a unique label to each named query, to ensure that all named queries within a given persistence context have unique names. The easiest method for doing this is to use an entity class name to prefix the name of each named query associated most closely associated with that entity. The JPA blueprints recommend similar use of naming conventions for named queries and other aspects of JPA-based code.
Leverage Features of J2SE SE 5 (and Beyond)
Because you will be using J2SE 5 (or a later version) with your JPA-based applications, you can apply J2SE 5’s features in your own code.
Generics enable JPA developers to specify one-to-many and many-to-many relationships between entities without the need to express the targetEntity attribute. This makes possible self-describing code rather than accomplishing the same functionality with in-source annotations or external XML configuration.
The enum cannot be used as an entity, but it can be used for a data member of a persisted entity to provide type safety and control of the finite range of values for a data member.
Performance Does Matter
The focus of this article has been on developing highly maintainable JPA-based applications, but the JPA specification provides many useful “hooks” for tweaking performance without necessarily making the JPA code less portable. JPA providers are supposed to ignore any provider properties in the persistence.xml file with an unrecognized property name. Query hints are ignored by JPA providers to which they do not apply, but I still prefer to place them in external XML rather than in the Java code.
These JPA provider “hooks” should be used when necessary to improve performance, but I prefer to keep the code free from them and declare as many of these as possible in external XML descriptor files rather than in the code.
Leverage the Latest Tools
Major integrated development environments (IDEs) now bundle several JPA-related tools. JDeveloper offers a wizard that can easily create JPA-based entity classes with appropriate annotations directly from specified database tables. With just a couple more clicks, the JDeveloper user can similarly create a stateless session bean to act as a facade for these newly created entity beans. NetBeans 6.0 offers similar JPA wizards, and the Eclipse Dali project supports JPA tools for the Eclipse IDE.
It is likely that many more highly useful JPA-related tools will continue to emerge.
Add Spring to Your JPA
A developer can use Spring to write JPA-based applications that can be easily run in standard Java environments, web containers, and full application server EJB containers with no changes necessary to the source code. This is accomplished via the Spring container’s ability to inject datasources configured outside of the code and to support transactions via aspect-oriented programming also configured outside of the code. The Spring framework enables JPA developers to isolate specifics of handling JPA in the various environments (Java SE standalone, Java EE web containers, and Java EE EJB containers) in external configuration files, leaving transparent JPA-based code.
Another feature Spring 2.0 offers JPA developers is the @Repository annotation, which is helpful in assessing database-specific issues underlying a JPA PersistenceException.
Finally, the Spring framework provides a convenient mechanism for referencing some of the JPA provider extensions that are common across the JPA providers.
The article “ Using the Java Persistence API with Spring 2.0” (see “Additional Resources”) has more information on use of the Spring Framework with JPA.
Apply Java EE 5 and EJB 3.0 Best Practices
The most effective use of JPA in a Java EE environment results from following effective EJB practices. Appropriate use of EJB 3.0 features such as dependency injection ensures that JPA use in Java EE environments is most effective. Another example of applying EJB best practices to JPA is use of a stateless session bean as a facade to JPA entities in Java EE applications.
Learn and Apply Best Practices of Related Technologies
The Java Persistence API is closely related to many other technologies, and much can be learned from the identified best practices for those technologies. These related technologies include relational databases, SQL, object-relational mapping (ORM) tools, and JDBC. For example, the JDBC best practice of using named or positional parameters with a PreparedStatement is mirrored in JPA. JPA supports named or positional parameters in the JPA Query Language for security and potential performance benefits.
Become Familiar with the JPA Standard
The Java Persistence API specification is fairly readable. It explains which JPA features are optional for implementations and are therefore not portable. The specification also discusses some likely trends or future directions that may be taken and warns against doing anything that might conflict with the anticipated change or addition.
Mike Keith has pointed out that “distilling and properly explaining the usage of features in correct contexts” is not part of the specification’s mandate. Therefore, a more efficient approach to gaining familiarity with the JPA standard is to access references that clearly explain correct and appropriate application of JPA. Several of these resources are included in the “Additional Resources” section.
Become Familiar with JPA Blueprints
The Java Persistence API blueprints documentation is another good source of information on practices for effective use of JPA.
Take Advantage of Oracle Resources on JPA
Oracle has been a major player in developing the Java Persistence API, having co-led the JPA 1.0 expert group, and has been involved heavily with the JPA reference implementations. Besides providing the JPA 1.0 reference implementation (Oracle TopLink Essentials), Oracle is leading the EclipseLink project to provide the JPA 2.0 reference implementation. Oracle also provides Oracle TopLink 11g as a JPA implementation with more features than those that come with the reference implementation.
OTN also features a large set of JPA resources. Two of my favorite resources available there are “JPA Annotation Reference” and the OTN Technical Article “ Taking JPA for a Test Drive”.
Learn from the Experience of Others (JPA-Related Blogs)
Additional and more complex JPA best practices and techniques will continue to be identified as more experience with JPA is gained. Online resources can be especially timely and relevant. Blogs vary in terms of quality, but the better JPA-oriented blogs provide invaluable tips and insight into JPA development. There are several blogs about JPA that I have consistently found to be useful in my JPA work. Some of these are listed in “Additional Resources.”
Conclusion
The Java Persistence API provides Java SE and Java EE developers with a single, standardized mechanism for database persistence. The practices outlined in this article help them develop JPA-based code that realizes the advantages provided by the JPA specification.
Additional Resources
EclipseLink www.eclipse.org/eclipselink/
“Java Persistence API: Best Practices and Tips” (2007 JavaOne conference)
“Java Persistence API: Portability Do’s and Don’ts” (2007 JavaOne conference)
“Java Persistence 2.0” (2007 JavaOne conference)
Dustin Marx is a senior software engineer at Raytheon Company.