Technical Article
Improving Java Application Performance and Scalability by Reducing Garbage Collection Times and Sizing Memory Using JDK 1.4.1
by Nagendra Nagarajayya and J. Steven Mayer , November 2002
New Parallel and Concurrent Collectors for Low Pause and Throughput applications
Abstract
As Java technology becomes more and more pervasive in the enterprise and telecommunications (telco) industry, understanding the behavior of the garbage collector becomes more important. Typically, telco applications are near-real-time applications. Delays measured in milliseconds are not usually a problem, but delays of hundreds of milliseconds, let alone seconds, can spell trouble for applications of this kind -- applications compromise on throughput to provide near-real-time performance. Enterprise applications are transaction oriented and tolerate delays better. They need to crunch as many transactions as possible in the shortest time i.e., the more compute time and resources available, the better. This means, faster and multiple CPUs, lots of memory, increases performance. A garbage collector that can make use of the extra resources, enhances performance.
Garbage collection limitations, which affected the performance of telco and enterprise applications is in the process of being eliminated with the introduction of new parallel and concurrent collectors. The collectors can be used to reduce delays to milliseconds for telco applications -- SIP servers, Call Processing applications --, while increasing throughput by providing more compute time to enterprise applications -- J2EE, OSS/BSS, MOM type of applications.
Analytical and modeling suggestions are presented along with features available in J2SE 1.4.1. A new tool, GC Analyzer, is available to model application behavior and try out the performance tuning suggestions.
Table of Contents
- 1.Introduction
- 2.New Garbage Collectors in JDK 1.4.1
- 3.Heap Layout in JDK 1.4.1
- 4.Using JDK 1.4.1 - Different options
- 5.Problems with earlier JDK versions, and how they are now getting solved with the new collectors
- 6.How GC Pauses Affect Scalability and Execution Efficiency
- 7.A SIP Server, the Benchmark Application
- 8.Modeling Application Behavior to Predict GC Pauses
- 9.Modeling Application Behavior Using "verbose:gc" Logs
- 10.Using the GC Analyzer Script to Analyze "verbose:gc" Logs
- 11.Reducing Garbage Collection Times
- 12.Reducing the Frequency of Young and Old GCs
- 13.Detection of Memory Leaks
- 14.Finding the Optimal Call-Setup Rate by Using the Rates of Creation and Destruction
- 15.Learning the Actual Object Lifetimes
- 16.Sizing the Young and Old Generations' Heaps
- 17.Determining the Scalability and Execution Efficiency of a Java Application
- 1.8Other Ways to Improve Performance
- 19.On the Horizon & Research Ideas
- 20.Conclusion
- 21.Acknowledgments
- 22.References
- Appendix A
This paper is an update to our previous paper "Improving Java Application Performance and Scalability by Reducing Garbage Collection Times and Sizing Memory Using JDK 1.2.2" [ 1]. That paper focussed on improving performance of telecommunication (telco) applications by optimizing garbage collection using collectors like the concurrent garbage collector. The paper also introduced application modeling, and its use to make application behavior deterministic.
The paper builds on the earlier paper and introduces new collectors and options in J2SE 1.4.1. The new collectors can be used to tune performance of both telco and enterprise applications. Garbage collection (GC) delays can be successfully lowered to be in milliseconds with the help of the parallel and the concurrent collector -- size the young-generation to about 64 MB, and the older generation to about 500 MB. So GC, a sizable contributor to performance degradation can be tuned, improving application efficiency to 90+%.
A new tool, GC Analyzer that works with the JDK 1.4.1 verbose GC logs can be downloaded to model application behavior and try out the performance tuning suggestions, (see Appendix A3 for download instructions).
1.1 Introduction to Garbage Collection, And Existing Garbage Collectors
The previous paper also introduced garbage collection, different collectors like the copy collector, mark-sweep-compact collector, incremental collector, generational collection and the advanced concurrent collector.
JDK 1.4.1 has all of the above collectors, and in addition offers new collectors.
2. New Garbage Collectors in JDK 1.4.1
The Java platform now provides new collectors like the young generation parallel collector and the old generation concurrent collector. In fact, there are two parallel collectors, one, which works in conjunction with the old generation concurrent collector, and is for near real-time or pause dependent applications, while the second is for enterprise or throughput oriented applications - J2EE, billing, payroll, OSS/BSS, MOM apps. The parallel collectors make use of multiple threads to parallelize and scale young generation collections on SMP architectures, speeding up the scavenging ¹. The difference between the two collectors is that the low-pause parallel collector works with the new concurrent older collector and with the traditional mark-compact collector, while the throughput parallel collector, at the moment, works only with the mark-compact collector.
2.1 Low Pause Collectors
2.1.1 Parallel Copying Collector
The Parallel Copying Collector is similar to the Copying Collector [ 1], but instead of using one thread to collect young generation garbage, the collector allocates as many threads as the number of CPUs to parallelize the collection. The parallel copying collector works with both the concurrent collector and the default mark-compact collector.
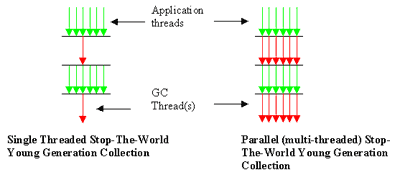
Figure 1 - Single Threaded & Parallel Collection
The parallel copying collection is still stop-the-world, but the cost of the collection is now dependent on the live data in the young generation heap, divided by the number of CPUs available. So bigger younger generations can be used to eliminate temporary objects while still keeping the pause low. The degree of parallelism i.e., the number of threads collecting can be tuned. This parallel collector works very well from small to big young generations.
The figure (Fig. 1) illustrates the difference between the single threaded and parallel copy collection. The green arrows represent application threads, and the red arrow(s) represent GC threads. The application threads (green arrows) are stopped when a copy collection has to take place. In case of the parallel copy collector, the work is done by n number of threads compared to 1 thread in case of the single threaded copy collector.
2.1.2 Concurrent Collector
The concurrent collector uses a background thread that runs concurrently with the application threads to enable both garbage collection and object allocation/modification to happen at the same time. The collector collects the garbage in phases, two are stop-the-world phases, and four are concurrent and run along with the application threads. The phases in order are, initial-mark phase (stop-the-world), mark-phase (concurrent), pre-cleaning phase (concurrent), remark-phase (stop-the-world), sweep-phase (concurrent) and reset-phase (concurrent). The initial-mark phase takes a snapshot of the old generation heap objects followed by the marking and pre-cleaning of live objects. Once marking is complete, a remark-phase takes a second snapshot of the heap objects to capture changes in live objects. This is followed by a sweep phase to collect dead objects - coalescing of dead objects space may also happen here. The reset phase clears the collector data structures for the next collection cycle. The collector does most of its work concurrently, suspending application execution only briefly.

Figure 2 - Concurrent Collection
The figure (Fig. 2) illustrates the main phases of the concurrent collection. The green arrows represent application threads, and the red, GC thread(s). The small red arrow represents, the brief stop-the-world marking phases, when a snapshot of the heap is made. The GC thread (big red arrow) runs concurrently with application threads (green arrows) to mark and sweep the heap.
Note: If "the rate of creation" of objects is too high, and the concurrent collector is not able to keep up with the concurrent collection, it falls back to the traditional mark-sweep collector.
2.2 Throughput Collectors
2.2.1 Parallel Scavenge Collector

Figure 3 - Parallel Collection
The parallel scavenge collector is similar to the parallel copying collector, and collects young generation garbage. The collector is targeted towards large young generation heaps and to scale with more CPUs. It works very well with large young generation heap sizes that are in gigabytes, like 12GB to 80GB or more, and scales very well with increase in CPUs, 8 CPUs or more. It is designed to maximize throughput in enterprise environments where plenty of memory and processing power is available.
The parallel scavenge collector is again stop-the-world, and is designed to keep the pause down. The degree of parallelism can again be controlled. In addition, the collector has an adaptive tuning policy that can be turned on to optimize the collection. It balances the heap layout by resizing, Eden, Survivor spaces and old generation sizes to minimize the time spent in the collection. Since the heap layout is different for this collector, with large young generations, and smaller older generations, a new feature called "promotion undo" prevents old generation out-of-memory exceptions by allowing the parallel collector to finish the young generation collection.
The figure (Fig. 3) illustrates the application threads (green arrows) which are stopped when a copy collection has to take place. The red arrow represents the n number of parallel threads employed in the collection.
2.2.2 Mark-Compact Collector
The parallel scavenge collector interacts with the mark-sweep-compact collector, the default old generation collector. The mark-compact collector is the traditional mark-compact collector, and is very efficient for enterprise environments where pause is not a big criterion. The throughput collectors are designed to maximize the younger generation heap while keeping the older generation heap to the needed minimum - old generation is intended to very long-term objects only.
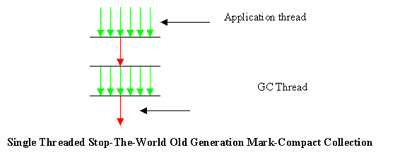
Figure 4 - Mark-Compact Collection
The figure (Fig. 4) illustrates a stop-the-world, old generation mark-sweep-compact collection. The application threads (green arrows) are stopped during the collection. The old generation collection single threaded.
3.1 Young Generation Heap
In JDK 1.4.1, the heap is divided into 3 generations, young generation, old generation, and permanent generation. Young generation is further divided into an Eden, and Semi-spaces.

Figure 5 - Heap layout
The size of the Eden and semi-spaces is controlled by the SurvivorRatio and can be calculated roughly as:
Eden = NewSize - ((NewSize / ( SurvivorRatio + 2)) * 2) From space = (NewSize - Eden) / 2 To space = (NewSize - Eden) / 2NewSize is the size of the young generation and can be specified on the command line using -XX:NewSize option. SurvivorRatio is an integer number and can range from 1 to a very high value.
The young generation can be sized using the following options:
- -XX:NewSize
- -XX:MaxNewSize
- -XX:SurvivorRatio
For example, to size a 128 MB young generation with an Eden of 64MB, a Semi-Space size of 32MB, the NewSize, MaxNewSize, and SurvivorRatio values can be specified as follows:
java -Xms512m -Xmx512m -XX:NewSize=128m -XX:MaxNewSize=128m \ -XX:SurvivorRatio=2 application
3.2 Old Generation Heap
The old generation or the tenured generation is used to hold or age objects promoted from the younger generation. The maximum size of the older generation is controlled by the -Xms parameter.
For the previous example to size a 256 MB old generation heap with a young generation of 256 MB the -mx value can be specified as:
java -Xms512m -Xmx512m -XX:NewSize=256m -XX:MaxNewSize=256m \ -XX:SurvivorRatio=2 application
The young generation takes 256 MB and the old generation 256 MB. -Xms is used to specify the initial size of the heap.
3.3 Permanent Generation Heap
The permanent generation is used to store class objects and related meta data. The default space for this is 4 MB, and can be sized using the -XX:PermSize, and -XX:MaxPermSize option.
Sometimes you will see Full GCs in the log file, and this could be due to the permanent generation being expanded. This could be prevented by sizing the permanent generation with a bigger heap using the -XX:PermSize and -XX:MaxPermSize options.
For example:
java -Xms512m -Xmx512m -XX:NewSize=256m -XX:MaxNewSize=256m \ -XX:SurvivorRatio=2 -XX:PermSize=64m -XX:MaxPermSize=64m application
Another way of disabling permanent generation collection is to use the -Xnoclassgc option. This is should be used with care since this disables class objects from being collected. To use this, size the permanent generation bigger so that there is enough space to store class objects, and a garbage collection is not needed to free up space.
For example:
java -Xms512m -Xmx512m -XX:NewSize=256m -XX:MaxNewSize=256m \ -XX:SurvivorRatio=2 -XX:PermSize=128m -XX:MaxPermSize=128m \ -Xnoclassgc application
4. Using JDK 1.4.1 - Different options
4.1 Default usage
A java application can be started using the following command:
java application
By default, the young generation uses 2 MB for the Eden, and 64KB for the semi-space. The older generation heap starts from about 5MB and grows up to 44MB. The default permanent generation is 4MB.
4.2 Using The -Xms and -Xms Switches
The old generation, default heap size can be overridden by using the -Xms and -Xmx switches to specify the initial and maximum sizes respectively:
java -Xms <initial size> -Xmx <maximum size> program
For example:
java -Xms128m -Xmx512m application
4.3 Using the :XX Switches to Enable the New Low Pause or Throughput Collectors
4.3.1 Using the Low Pause Collectors
The young generation, parallel copying collector can be enabled by using the -XX:+UseParNewGC option, while the older generation, concurrent collector can be enabled by using the -XX:+ UseConcMarkSweepGC option.
For example:
java -server -Xms512m -Xmx512m -XX:NewSize=64m -XX:MaxNewSize=64m \ -XX:SurvivorRatio=2 -XX:+ UseConcMarkSweepGC \ -XX:+UseParNewGC application
Note:
- If -XX:+UseParNewGC is not specified, the young generation will make use of the default copying collector [ 1].
- If -XX+UseParNewGC is specified on a single processor machine, the default copy collector is used since the number of CPUs is 1. You can force the parallel copy collector to be enabled by increasing the degree of parallelism.
4.3.1.1 Controlling the Degree of Parallelism ²
By default, the parallel copy collector will start as many threads as CPUs on the machine, but if the degree of parallelism needs to controlled, then it can be specified by the following option:
-XX:ParallelGCThreads=<desired parallelism>
Default value is equal to number of CPUs.
For example, to use 4 parallel threads to process young generation collection:
java -server -Xms512m -Xmx512m -XX:NewSize=64m -XX:MaxNewSize=64m \ -XX:SurvivorRatio=2 -XX:+UseParNewGC -XX:ParallelGCThreads=4 \ -XX:+UseConcMarkSweepGC application
4.3.1.2 Simulating The "promoteall" Modifier In JDK 1.4.1
"promoteall" is a modifier available in JDK 1.2.2 that enables promotion of all live objects at a young generation collection to be promoted to the older generation without any tenuring. There is no "promoteall" modifier in JDK 1.4.1, but similar behavior can be achieved by controlling the tenuring distribution. The number of times an object is aged in the young generation is controlled by the option MaxTenuringThreshold. Setting this option to 0 means objects are not copied, but are promoted directly to the older generation. SurvivorRatio should be increased to 20000 or a high value (see 3.1 for heap calculations) so that Eden occupies most of the Young Generation Heap space.
-XX:MaxTenuringThreshold=0 -XX:SurvivorRatio=20000
For example:
java -server -Xms512m -Xmx512m -XX:NewSize=64m -XX:MaxNewSize=64m \ -XX:SurvivorRatio=20000 -XX:MaxTenuringThreshold=0 \ -XX:+UseParNewGC -XX:+UseConcMarkSweepGC application
4.3.1.3 Controlling the Concurrent collection initiation
The concurrent collector background thread starts running when the percentage of allocated space in the old generation goes above the -XX:CMSInitiatingOccupancyFraction, default value is 68%. This value can be changed and the concurrent collector can be started earlier by specifying the following option:
-XX:CMSInitiatingOccupancyFraction=<percent>
For example:
java -server -Xms512m -Xmx512m -XX:NewSize=64m -XX:MaxNewSize=64m \ -XX:SurvivorRatio=20000 -XX:MaxTenuringThreshold=0 \ -XX:+UseParNewGC -XX:+UseConcMarkSweepGC \ -XX:CMSInitiatingOccupancyFraction=35 application
4.3.2 Using the Throughput Collectors
The young generation, parallel scavenge collector, can be enabled by using the -XX:UseParallelGC option. The older generation collector need not be specified since the mark-compact collector is used by default.
For 32 bit usage:
java -server -Xms3072m -Xmx3072m -XX:NewSize=2560m \ -XX:MaxNewSize=2560m XX:SurvivorRatio=2 \ -XX:+UseParallelGC application
For 64 bit usage:
java -server -d64 -Xms8192m -Xmx8192m -XX:NewSize=7168m \ -XX:MaxNewSize=7168m XX:SurvivorRatio=2 \ -XX:+UseParallelGC application
Note:
- -XX:TargetSurvivorRatio is a tenuring threshold that is used to copy the tenured objects in the young generation. With large heaps and a SurvivorRatio of 2, survivor semi-space might be wasted, as the TargetSurvivorRatio by default is 50. This could be increased to maybe 75 or 90, maximizing use of the space.
4.3.2.1 Controlling the Degree of Parallelism
Again, by default, the parallel scavenge collector will start as many threads as CPUs on a machine, but if the degree of parallelism needs to controlled, then it can be specified by the following switch:
-XX:ParallelGCThreads=<desired parallelism>
Default value is equal to number of CPUs.
For example, to use 4 parallel threads to process young generation collection:
java -server -Xms3072m -Xmx3072m -XX:NewSize=2560m \ -XX:MaxNewSize=2560m XX:SurvivorRatio=2 \ -XX:+UseParallelGC -XX:ParallelGCThreads=4 application
4.3.2.2 Adaptive Sizing for Performance
The Parallel scavenge collector performs better when used with the -XX:+UseAdaptiveSizePolicy. This automatically sizes the young generation and chooses an optimum survivor ratio to maximize performance. The parallel scavenge collector should always be used with the -XX:UseAdaptiveSizePolicy.
For example:
java -server -Xms3072m -XX:+UseParallelGC \ -XX:+UseAdaptiveSizePolicy application
5. Problems with earlier JDK versions, and how they are now getting solved with the new collectors
The biggest problem with JDK 1.2.2_08 was stop-the-world collection, which introduced serialization. Serialization directly affects scalability and throughput (see next section 6). Even though the GC pause, in JDK 1.2.2_08, was reduced to less than 100 ms range - using the concurrent collector and sizing the younger generation smaller, about 12-16MB --, any increase in load would increase the frequency and pause, as the young generation collection was single threaded. This problem is now solved with JDK 1.4.1, as the young generation collection is parallel (multi-threaded) and run on multiple CPUs at the same time. The collection is still stop-the-world but happens in parallel, resulting in smaller pauses even with bigger young generations. The decreased frequency of the collection and pause, reduces the serialization problem as application threads run for a longer duration increasing the scalability and throughput. So GC serialization, which was one of the biggest factors affecting scalability, especially with increased loads, will be less of a factor.
6. How GC Pauses Affect Scalability and Execution Efficiency
Linear scalability [ 28] of an application running on an SMP (Symmetrical Multi Processing)-based machine is directly limited by the serial parts of the application. The serial parts of a Java application are:
- Stop-the-world GC
- Access to critical sections
- Concurrency overhead such as scheduling, context switching, ...
- System and communication overhead
The percentage of time spent in the serial portions determines the maximum scalability that can be achieved on a multi-processor machine and in turn the execution efficiency of an application. Because the young- and old-generation collectors all have at least some single-threaded stop-the-world behavior, GC will be a limiting factor to scalability even when the rest of the application can run completely in parallel. Using the concurrent collector will help reduce this effect, but will not completely remove it.
The scalability and execution efficiency of an application can be calculated using Amdahl's law.
6.1 Amdahl's Law & Efficiency calculations
If S is the percentage of time spent (by one processor) on serial parts of the program and P is the percentage of time spent (by one processor) on parts of the program that could be done in parallel , then:
|
|||
| where N is the number of processors. | |||
| This can be reduced to: | |||
|
|||
| where F is the percentage of time spent in the serial parts of the application and N is the number of processors. | |||
|
|||
| when N is very large. | |||
So if F = 0 (i.e., no serial part), then speedup = N (the ideal value). If F = 1 (i.e., completely serial), then speedup = 1 no matter how many processors are used.
The effect of the serial fraction F on the Speedup when N = 10:

Figure 6 - Speedup
6.1.1 Scaled Speedup
Assuming that the problem size is fixed, then Amdahl's Law can predict the speedup on a parallel machine:
Speedup = (S + P) / (S + (P / N)) -> (4)
Speedup = 1 / (F + ((1 - F) / N)) -> (5)
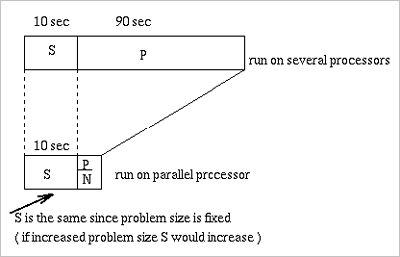
Figure 7 - Scaled Speedup
More details on Amdahl's Law and scaled speedup can be obtained from [ 22] .
6.1.2 Efficiency
Execution efficiency is defined as:
E = Speedup / N -> (6)
Execution efficiency translates directly to the CPU percentage used by an application. For a linear speedup this is 1, or 100%. The higher the number, the better, because it translates to higher application efficiency.
7. A SIP Server, the Benchmark Application
Our previous paper had used a SIP server to gather research data. This time, most of the work has been done with a simple Java program that simulated creation of different type of objects. The idea was that this program could be extended to emulate different kinds of application behavior from near real time applications (telco) to throughput applications (enterprise). From a macroscopic view of the collector, every application has the same behavior, n number of objects are created / second, of these, a certain percentage is temporary, some intermediate, and the remaining long term. The ratios and the lifetime of these are the most important factor. Next would be the types of objects, object complexity, and relationships between the objects and how these affect the collection. Once this can be emulated, most application behavior can be simulated. The prototype is extremely primitive at the moment, and is available on request.
7.1 Using SIP To Test Real Time Requirements
Session Initiation protocol (SIP) [ 21] is a protocol defined by the Internet Engineering Task Force (IETF), used to set up a session between two users in real time. It has many applications, but the one focussed in here is setting up a call between users. After a call setup is completed, the SIP portion is complete. The users are then free to pass real-time media (such as voice) between the two endpoints. Note that this portion, the call, does not involve SIP or the servers that are routing SIP call setups.
If this protocol is still unfamiliar, it might help to think of it as akin to Hyper Text Transfer Protocol (HTTP) [ 24]. It is a similar, text-based protocol founded on the request/response paradigm. One of the key differences is that SIP supports unreliable transport protocols, such as UDP. When using UDP, SIP applications are responsible for ensuring that packets reach their destination. This is accomplished by retransmitting requests until a response is received.
One problem that arises from the model of application-level reliability is retransmission storms. If an application does not respond quickly enough (within 500 ms by default in the specification), the request will be retransmitted. This retransmission continues until a response is received. Each retransmit makes more work for the receiving server. Hence, retransmissions can cause more retransmissions, and thrashing can ensue.
A GC cycle that takes longer than 500 ms will cause retransmissions. One that takes several seconds will ensure many retransmissions. These, in conjunction with the new requests that arrive at the server during garbage collection, will make even more work for the server and it will fall further behind.
Even absent the overburdening problems just described, other constraints make garbage collection pauses unacceptable. There are carrier grade requirements that state acceptable latencies from the moment an initiating side begins a call to the moment it receives a response from the terminating side. These are typically sub-second times, so a multiple-second pause in a SIP server for GC is unacceptable.
7.2 Call Setups
"Call setup" [ 22] is a concept used throughout this paper. A call setup is simply the combination of an originating side stating that it wishes to initiate a session (a call in this case) and a terminating side responding that it is interested as well. In SIP, there is also the concept of an acknowledgement being sent back to the terminating side after it accepts.
After a call setup is complete, the server must maintain call setup state for 32 seconds in order to handle properly any application-level retransmissions that might occur. This specification is the reason the value of 32 seconds is used as an active duration1 throughout the paper.
8. Modeling Application Behavior to Predict GC Pauses
Modeling Java applications makes it possible for developers to remove unpredictability attributed to the frequency and duration of pauses for GC.
The frequency and pause duration of GC are directly related to the following factors:
- Incoming call-setup rate
- Number and total size of objects created per call setup
- Average lifetime of these objects
- Size of the Java heap
Developers can construct a theoretical model to show application behavior for various call-setup rates, numbers of objects created, object sizes, object lifetimes, and heap sizes. A theoretical model reflects the extremities of the application behavior for the best conditions and the worst. Once developers know these extremities, they can model a real-life scenario that helps predict the maximum call-setup rate that can be achieved with acceptable pauses, and that shows what can happen when call-setup rates exceed the maximum and application performance deteriorates.
8.1 Best-Case Scenario
Assumptions:
- Calculations are for a SIP application, but could be applied to any generic client-server application that has a request, a response, and an active time that request state is maintained
- For simplicity, only call setups are modeled (call tear-downs are not considered)
- The young collector is configured to use the promoteall modifier
- The old generation uses a concurrent collector
-
The variables that change from scenario to scenario are listed in a table preceding the results
Parameter Assumed value Time call-setup state is maintained - active duration of call setup 0 ms Time between call setups 10 ms Young semi-spacgeneration Eden e size 5 MB Young GC Eden thresholdthreshold 100100% Oldheap size N/A Old GC threshold N/A Total size of objects per call setup 50 KB Lifetime of objects 0 ms
|
A young generation GC (GC[0], see 9.2 Snapshot of a GC Log) occurs when the 5-MB Eden semi-sspace is 100% full. |
|
||
|
Ideal objects space taken / call setup: = (semi-spaceEden size / total size of each call setup's objects) = 5 MB / 50 KB = 102.4 call setups / semi-space |
->(10) | ||
|
So a GC occurs every: frequencyperiod = (call setups * time between call setupscall-setup rate) = 102.4 * 10 = 1,024 ms |
->(11) | ||
| Remember, in this scenario, we are not accumulating any garbage, because we assume that all objects are very short-lived and they are all collected every young GC. Hence, nothing is ever promoted to the old heap. So, assume that each young GC takes 50 ms. | |||
|
So in an hour of execution the application spends roughly this muchtime in young GC: = (seconds per hour * (GC pause in ms / 1000)) = 3600 * (50 / 1000) = 180 seconds, or 3 minutes |
->(12) |
||
| Because no objects are promoted to the older generation, the concurrent collector is not activated, and its cost on the application performance is assumed to be zero. | |||
|
Total processing time available / hour: = (Minutes in a hour) - (time lost to young generation collection) = 60 - 3 = 57 minutes. |
|||
|
Total call setups per hour @ 100 calls / second: = (call setups per second) * (seconds per minute) * (numberof valid minutes in a hour, available to the application) = 100 * 60 * 57 = 342,000 call setups / hour on 1 CPU |
|||
|
Serial portion from (12) is 3 minutes lost to GC every hour. = 3 / 57 = 0.0526 |
|||
|
Scalabilitywith a four-CPU machine:
|
|||
|
So at 86.37% efficiency, we can process: (342,000 * 0.8637) * 4 = 1,181,542 call setups / hour |
8.2 Worst-Case Scenario
Assumptions:
| Parameter | Assumed value |
|---|---|
| Time call-setup state is maintained - active duration | Infinite |
| Time between call setups | 10 ms |
| Young Edensemi-space size | 5 MB |
| Young GC Eden thresholdthreshold | 100100% |
| Old heap size | 512 MB |
| Old GC threshold | 68% |
| Total size of objects per call setup | 50 KB |
| Lifetime of objects | Infinite |
|
Because all objects in this scenario are long-lived and the promoteall option has been specified, at every young-generation GC all the objects are promoted. Because the young GC threshold is 100%, 5 MB of objects will be promoted. |
->(20) | |
|
So to fill up a 5 MB semi-space: From (#10), we should have received about 102.4 calls |
|
|
|
A GC occurs every: frequencyperiod= (cps * time between call setupscall-setup rate) = 102.4 * 10 = 1,024 ms |
->(21) | |
|
Each collection promotes 5 MB, 5,242,880 Bytes |
->(22) |
|
|
So if the application is run with an old heap of 512 MB: The old heap should fill up in about: = (heap size) / (size of objects being promoted) = 512 MB / 5 MB = 536,870,912 / 5,242,880 = 102 promotions |
->(23) | |
|
So if promoting 5 MB of objects to the old generation takes the young GC collector about 200 ms (because young GC is more expensive when promotion takes place, we assume a higher value than before), thenwe have: total pause duration = (number of promotions * pause duration) = 102 * 200 = 20,400 ms = 20.4 seconds |
->(24) | |
|
A promotion takes place every 1,024 ms, so for 102 promotions: time for promotions = (number of promotions * (frequencyperiodicity + pause duration)) = 102 * (1,024 + 200) = 124,848 ms = 2.08 minutes |
->(25) | |
|
With one CPU the heap should fill up in about 2.08 minutes. |
||
|
Serial percentage due to young-generation GC: = ((total pause duration * 100) / (60 * (total time for promotions)) = 20.4 * 100 / (60 * 2.08) = 16.34% |
->(26) | |
|
Note: The serial percentage due to the old generation collector is assumed to be zero, because the amount of time spent in stop-the-world GC for the concurrent collector is negligible compared to the amount of time spent in stop-the-world young GC. |
||
|
With four CPUs: Speedup= 1 / (.1634 + (1 - .1634) / 4) = 2.673 |
->(27) | |
| Execution Efficiency = (2.673 / 4) * 100 = 66.93% | ->(28) | |
|
So with 4 CPUs, we should fill up the heap in about: = (#23) * (#26) = (2.08 * 0.6693) = 83.52 seconds |
->(29) |
8.3 A Real Scenario with Each Call Setup Active for 32 Seconds
(Calculated for Concurrent GC)
Assumptions:
| Parameter | Assumed value |
|---|---|
| Time call-setup state is maintained - active duration | 32,000 ms |
| Time between call setups | 10 ms |
| Young Edensemi-space size | 5 MB |
| Young GC threshold | 100% |
| Old heap size | 512 MB |
| Old GC threshold | 68% |
| Total size of objects per call setup | 50 KB |
| Lifetime of objects | 50% = 0 ms 50% = 32,000 ms |
|
Each young-generation GC promotes about 2.5 MB of live objects, becausehalf the objects are short-lived and half long-lived. |
->(30) |
|
|
To fill up the 5-MB semi-space Eden: From (10), 102.4 call setups |
|
|
|
A GC occurs every: = (call setups received * time between callsetupscall-setup rate) = 102.4 * 10 = 1,024 ms |
->(31) |
|
|
A promotion promotes: = 2.5 MB of live data <- assumption (30) = 2,621,440 Bytes |
->(32) |
|
|
So a promotion occurs every 1,024 ms, so in 32,000 ms, the number of promotions: = (active duration of call setup / frequencyperiodicity) = 32,000 / 1,024 = 31 promotions |
->(33) |
|
|
32,000 ms is the active duration of a call setup; the first call setup will be released at the end of the 32,000 ms so in 32,000 ms the number of call setups that can be received: = (active duration of a call setup / call-setup ratetime between call setups) = 32,000 / 10 = 3,200 calls
So one active-duration segment is made up of 3,200 calls. |
->(34) |
|
|
At the end of 64,000 ms, all call setups from the first active duration will be dead. At the end of 96,000 ms, call setups from two active durationsduration's will be dead. At the end of 128,000 ms, call setups from three active durationsduration's will be dead. At the end of 160,000 ms, call setups from four active durationsduration's will be dead. |
||
|
In each young GC we promote: = 2,621,440 Bytes <- from (32), |
||
|
So total promotion in bytes every 32 seconds is: = (#32) * (#33) = 2,621,440 * 31 = 81,264,640 or 79.36 MB |
->(35) |
|
|
Theinitial mark GC initial mark phase will occur when the heap is 68% fullonly 32% of the heap is free: = (6832% * 512 MB) = 163.84 MB free = 512 MB - 163.84 MB = 348.16 MB used |
->(36) |
|
|
Time when an initial mark GC initial mark phase might occur is: = (initial mark size in MB / promotion size in MB) * frequencyperiodicity of promotion = (348.16 MB / 2.5 MB) * 1,024 ms = 142,606 ms |
->(37) |
|
|
After an initial mark GCInitial mark phase, a remark GCremark phase takes place; assume that this happens when the heap is at 7228%full: = ((100% - 28%) * 512 MB) = 368.64 MB used |
->(38) |
|
|
Time when a remark GCremark phase might occur is: = (remark size in MB / promotion size in MB) * frequencyperiodicity of promotion = (368.64 MB / 2.5 MB) * 1,024 = 150,995 ms |
->(39) |
|
|
Number of active durationsduration's present in the old heap at remark GCremark phase: = ((#38) / (#35)) = 368.64 / 79.36 = 4.6 |
->(40) |
|
|
Time to fill up an active-duration segment: = (#33) * (#31) = 31 * 1,024 = 31,744 ms |
->(41) |
|
|
Time to fill up 4.6 active durationsduration's: = 31,744 * 4.6 = 146,022 ms |
||
|
Thetime when a sweepresize GC phase can take place is soon after a remark GCremark phase: = (#39) = 150,995 ms(assume sweep phase takes almost 0 ms to free the heap) |
->(42) |
|
| The number of active-duration segments that will be freed at the end of the sweep a resize phaseGC can clean up: = ((#42) / active duration of a call setup) - (adjust factor for current active-duration segment) = (150,995 / 32,000) - 1 = 3.72 Active-duration segments |
->(43) |
|
|
The sweep phase should free 3.72 active duration's: = (#43) * (#35) = 3.72 * 79.36 = 295.22 MB |
->(44) |
|
|
A young-generation GC should occur every 1,024 ms, and an old-generation Initial mark phase should occur every 142,606 ms |
9. Modeling Application Behavior Using "verbose:gc" Logs
The model above is theoretical and relies on a lot of assumptions; but developers can use the "verbose:gc" log from an actual application run to construct a real-world model. The model will allow one to visualize the runtime behavior of both the application and the garbage collector. The verbose:gc logs contain valuable information about garbage-collection times, the frequency of collections, application run times, number of objects created and destroyed, the rate of object creation, the total size of objects per call, and so on. This information can be analyzed on a time scale, and the behavior of the application can be depicted in graphs and tables that chart the different relationships among pause duration, frequency of pauses, and object creation rate, and suggest how these can affect application performance and scalability. Analysis of this information can enable developers to tune an application's performance, optimizing GC frequency and collection times by specifying the best heap sizes for a given call-setup rate (see 16. Sizing the Young and Old Generations' Heaps).
9.1 Java "verbose:gc" Logs
Logs containing detailed GC information are generated when a Java application is run with the -verbose:gc flag turned on. With earlier JDK versions, specifying this twice on the command line, increased the GC info printed out, and this could then be analyzed. Similar and more richer output is available with JDK 1.4.1 VM, but instead of specifying the -verbose:gc option twice, the below options provide a more detailed output that can be analyzed:
Note:
- Using -XX:+PrintHeapAtGC generates lot of information. If there are a lot of GCs, and log size is a concern, then this option might be omitted. The collected information is not self-explanatory but can still be processed by the analyzer (see pattern 2, and pattern 7 under Appendix A4.1).
- -Xloggc is a new option available with J2SE 1.4. This option logs verbose:gc data into a log file. But it does not log the data ouput with the above switches. So it is mentioned here.
For example:
java -server -Xms512m -Xmx512m -XX:NewSize=64m -XX:MaxNewSize=64m \ -XX:SurvivorRatio=2 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC \ -XX:+PrintGCDetails -XX:+PrintGCTimeStamps \ -XX:+PrintHeapAtGC application
9.2 Snapshot of a GC Log
The snapshot below is of a verbose:gc log entry generated by the JDK 1.4.1 VM with the above options. Highlighted phrases with superscript numbers are footnoted below.
0.548403 GB: [GC {Heap before GC invocations=1:
Heap
par new generation total 18432K, used 12826K [0xf2800000, 0xf4000000, 0xf4000000)
eden space 12288K, 99% used 1 [0xf2800000, 0xf33ff840, 0xf3400000)
from space 6144K, 8% used 2 [0xf3a00000, 0xf3a87360, 0xf4000000)
to space 6144K, 0% used 3 [0xf3400000, 0xf3400000, 0xf3a00000)
concurrent mark-sweep generation total 40960K, used 195K 4 [0xf4000000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 40960K, 0% used [0xf4000000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K 5 [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000)
0.549364 DC: [ParNew: 12826K 6-> 1086K 7( 18432K 8), 0.02798039 secs] 13022K->1282K(59392K)
Heap after GC invocations=2:
Heap
par new generation total 18432K, used 1086K [0xf2800000, 0xf4000000, 0xf4000000)
eden space 12288K, 0% used 10 [0xf2800000, 0xf2800000, 0xf3400000)
from space 6144K, 17% used 11 [0xf3400000, 0xf350fbc0, 0xf3a00000)
to space 6144K, 0% used 12 [0xf3a00000, 0xf3a00000, 0xf4000000)
concurrent mark-sweep generation total 40960K, used 195K 13 [0xf4000000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 40960K, 0% used [0xf4000000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K 14 [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000)
} , 0.0297669 GE secs] Before GC snapshot
- Eden Space, usually 100% occupied for a young generation GC
- From Space, % occupancy before GC To Space, should be 0% occupancy Old generation heap space, total space 40MB, occupied 195K. Change here from last snapshot indicates direct creation of objects in the older generation
- Permanent generation, % occupancy
During GC snapshot
- So much of Eden + From Space occupied at GC
- After garbage collection, From Space now has this occupancy
- Eden + 1 Semi-space size
- Time for GC
After GC snapshot
- Eden space after GC
- From space after GC (From and To space have been flipped, look at the addresses)
- To space is 0
- Old generation heap occupancy, if objects got promoted, this should show an increase
- Permanent heap space, should not show a change
GB - GC Begin Time stamp GE - Collection time DC - During GC Time stamp
Some derivations:
Total GC time = GE Time to stop the threads = GB - DC Time to restart the threads = GE - 9 (above) GC overhead = GB - DC + GE - 9 (above)
10. Using the GC Analyzer Script to Analyze "verbose:gc" Logs
The GC analyzer is a perl script that analyzes the verbose:gc log file, and reconstructs the application behavior by building a mathematical model. The input to the script is a verbose:gc log file generated using the above options. It provides as output:
-
GC-related information
- Young and old generation pause
- Periodicity
- Application times
- Serial Part of the Application
- Scalability factor
- Application Efficiency or CPU utilization
- Call-setup information
- Active-duration information
- Application-behavior information
- Various verifications
Here is snapshot of its output:
Processing 12_12_60_60_1_par_tenure_concgc.log ...
Call rate = 90 cps ...
Active call-setup duration = 32000 ms
Number of CPUs = 4
---- GC Analyzer Summary : 12_12_60_60_1_par_tenure_concgc.log ----
Application info:
Application run time = 101590.05 ms
Heap space = 60 MB
Eden space = 6144 KB
Semispace = 3072 KB
Tenured space = 49152 KB
Permanent space = 4096 KB
Young GC --------- (Copy GC + Promoted GC ) ---
Copy gc info:
Total # of copy gcs = 94
Avg. size copied = 1789429 bytes
Periodicity of copy gc = 992.845278723404 ms
Copy time = 87 ms
Percent of pause vs run time = 8%
Promoted gc info:
Total number# of promoted GCs = 216
Average size promoted = 262859 bytes
Periodicity of promoted GC = 428.59 ms
Promotion time = 41.73 ms
Percent of pause vs run time = 8.87 %
Young GC info:
Total number# of young GCs = 310
Average GC pause = 55.73 ms
Copy/Promotion time = 55.73 ms
Overhead(suspend,restart threads) time = -9.08 ms
Periodicity of GCs = 271.98 ms
Percent of pause vs run time = 17.01 %
Avg. size directly created old gen = 6868.17 KB
Old concurrent GC info:
Heap size = 49152 KB
Avg. initial-mark threshold = 76.96 %
Avg. remark threshold = 77.29 %
Avg. Resize size = 277.81 KB
Total GC time (stop-the-world) = 735.20 ms
Concurrent processing time = 18924.00 ms
Total number# of GCs = 120
Average pause = 6.13 ms
Periodicity of GC = 840.46 ms
Percent of pause vs run time = 0.72 %
Percent of concurrent processing vs run time = 18.63 %
Total (young and old) GC info:
Total count = 430
Total GC time = 18011.80 ms
Average pause = 41.89 ms
Percent of pause vs run time = 17.73 %
Call control info:
Call-setups per second (CPS) = 90
Call rate, 1 call every = 11 ms
Number# call-setups / young GC = 24.4780986483871
Total call throughput = 7588.21
Total size of short lived data / call-setup = 246285 bytes
Total size of long live data / call-setup = 10738 bytes
Average size of data / call = 257023
Total size of data created per young gen GC = 6291456 bytes
Execution efficiency of application:
GC Serial portion of application = 17.73%
Actual CPUs = 4
CPUs used for concurrent processing = 3.25
Application Speedup = 2.33
Application Execution efficiency = 0.58
Application CPU Utilization = 58.13 %
Concurrent GC CPU Utilization = 7.15 %
--- GC Analyzer End Summary ----------------
The detailed output is shown in Appendix A.
The information generated by the analyzer can be used to tune application performance in the following ways:
- Reducing GC collection times
- Reducing the frequency of the young and old GCs
- Detecting memory leaks
- Detecting the rate of creation and destruction of objects, and using it to optimize the call setup rate
- Knowing the actual lifetimes of objects
- Sizing of the young and old generation heaps
- Modeling application and GC behavior
- Determining the scalability and execution efficiency of an application
- Reducing serial part of the application
11. Reducing Garbage Collection Times
Java applications have two types of collections, young-generation and old-generation.
11.1 Young-Generation Collection Times
A young-generation collection occurs when the Eden space is full. A copying collector - could be a parallel copy collector -- is used to copy the live objects in the Eden to the To semi-space, while also copying any live objects in the From semi-space. If the To semi-space is small or almost full, the live objects could be promoted - either from the From space or the Eden --- to the old generation, if they have been aged sufficiently. When developers inspect the GC logs they will find two types of young-generation GCs, copy GCs and promotion GCs.
11.1.1 Snippet from a Copy GC
1.75013: [GC {Heap before GC invocations=2:
Heap
par new generation total 18432K, used 13373K [0xec800000, 0xee000000, 0xee000000)
eden space 12288K, 99% used [0xec800000, 0xed3ff840, 0xed400000)
from space 6144K, 17% used 1 [0xed400000, 0xed50ff40, 0xeda00000)
to space 6144K, 0% used [0xeda00000, 0xeda00000, 0xee000000)
concurrent mark-sweep generation total 139264K, used 195K [0xee000000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 139264K, 0% used [0xee000000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000)
1.75102: [ParNew: 13373K->1440K(18432K), 0.0379632 secs] 13569K->1635K(157696K)
Heap after GC invocations=3:
Heap
par new generation total 18432K, used 1440K [0xec800000, 0xee000000, 0xee000000)
eden space 12288K, 0% used [0xec800000, 0xec800000, 0xed400000)
from space 6144K, 23% used 2 [0xeda00000, 0xedb68230, 0xee000000)
to space 6144K, 0% used [0xed400000, 0xed400000, 0xeda00000)
concurrent mark-sweep generation total 139264K, used 195K [0xee000000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 139264K, 0% used [0xee000000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000)
} , 0.0395186 secs] The above snippet shows tenuring (aging) of temporary objects in the younger generation. No promotions are done in a copy GC. Live objects are copied back and forth between the Eden and the two semi-spaces, allowing the short-term objects (intermediate objects) more time to die. In the above snippet, the size of the tenure goes from 17% to 23%.
- Before GC part, size of objects being aged in the younger generation is about 17%
- After GC part, size of objects being aged in the younger generation is about 23%
11.1.2 Snippet from a Promotion GC
3.61664: [GC {Heap before GC invocations=8:
Heap
par new generation total 18432K, used 15568K [0xec800000, 0xee000000, 0xee000000)
eden space 12288K, 99% used [0xec800000, 0xed3ff800, 0xed400000)
from space 6144K, 53% used [0xed400000, 0xed734a58, 0xeda00000)
to space 6144K, 0% used [0xeda00000, 0xeda00000, 0xee000000)
concurrent mark-sweep generation total 139264K, used 390K 1 [0xee000000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 139264K, 0% used [0xee000000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000)
3.61775: [ParNew: 15568K->3126K(18432K), 0.0592143 secs] 15959K->4018K(157696K)
Heap after GC invocations=9:
Heap
par new generation total 18432K, used 3126K [0xec800000, 0xee000000, 0xee000000)
eden space 12288K, 0% used [0xec800000, 0xec800000, 0xed400000)
from space 6144K, 50% used [0xeda00000, 0xedd0d8c0, 0xee000000)
to space 6144K, 0% used [0xed400000, 0xed400000, 0xeda00000)
concurrent mark-sweep generation total 139264K, used 892K 2 [0xee000000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 139264K, 0% used [0xee000000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000)
} , 0.0610121 secs] The above snippet shows promotion of long-term objects. Live objects, which survive aging in the younger generation, are copied to the old-generation heap space. For a promotion GC, the increase in the old generation space from the Before GC line to After GC line shows the size of the promotion to the older heap.
- Before GC part, old generation heap occupancy is about 390 KB
- After GC part, old generation heap occupancy is about 892 KB
The young-generation collection time is directly proportional to the size of the live data in the Eden and the From semi-space. A collection, and hence a pause, occurs when the Eden space is full. Live objects are copied, or promoted if the objects have aged sufficiently. The cost of a copy GC is the time to copy live objects to the To semi-space, while the cost of a promotion GC is the time to promote or copy live objects to the old generation. The cost of promoting is a little higher than that of copying, because the young collector has to interact with the old collector's heap.
Decreasing the young generation size, increases the frequency of young-generation collection and decreases the collection duration, as less live data has accumulated. Similarly, increasing the young generation size, decreases the frequency of young-generation collection and increases the duration of each collection, as more live data accumulates. Note, though, that less frequent collection also provides more time for the short-term data to die. It also partly offsets system overhead like thread scheduling, done at every collection cycle. The net result is a slightly longer collection but at a decreased frequency.
To tune the young generation collection time, developers must determine the right combination of frequency, collection time, and heap size. These three parameters are directly affected by the number of objects created per call setup and the lifetimes of these objects. So in addition to sizing the heap, the code may need to change, to reduce the number of objects created per call setup, and also to reduce the lifetimes of some objects.
The following output from the GC analyzer helps with this task:
- Average pause per young-generation GC
- Rate of promotion
- Average promotion size
- Number of copy GCs
- Frequency or periodicity of copy GCs
- Number of promotion GCs
- Frequency or periodicity of promotion GCs
- Size of data directly created in the older generation
See Appendix A for the detailed output.
11.1.3 Using This Information to Tune an Application
11.1.3.1 Using the simulated promoteall Modifier
Three categories of object lifetime are important to the decision whether to use the promoteall modifier:
- Temporary objects - die before encountering even one young GC
- Intermediate objects - survive at least one young GC, but are collected before promotion
- Long-term objects - live long enough to get promoted
Temporary objects are never copied or promoted because they die almost instantly. Long-term objects are always promoted because they live through multiple young GCs. Only intermediate objects benefit from copying. After the first time they are aged or copied, they usually die and are collected in the next cycle, sparing the collector the cost of promoting them.
If the application has few intermediate objects, using the promoteall modifier decreases the amount of time that the application spends in young GC. This saving comes from not copying long-term objects from one semi-space to the other before promoting them to the old heap anyway.
Intermediate objects that are promoted take slightly more time to promote than to age. Also, the old-heap collector collects these objects, so it again uses slightly more time to collect them when they do die. However, the old-heap collection happens concurrently rather than in the young collector's stop-the-world fashion, so scalability should improve.
Note: The promoteall modifier could be more suited for real-time apps which have pause as a criteria but it could be used with throughput oriented enterprise apps too.
11.1.3.2 Simulated promoteall Modifier Usage
java -server -Xms512m -Xmx512m -XX:NewSize=64m \
-XX:MaxNewSize=64m
XX:SurvivorRatio=100 \
-
XX:MaxTenuringThreshold=0 -XX:+UseParNewGC \
-XX:+UseConcMarkSweepGC application
11.1.3.3 Snippet of a Promotion GC with the promoteall Modifier
0.714029: [GC {Heap before GC invocations=1:
Heap
par new generation total 12224K, used 12129K [0xf2800000, 0xf3400000, 0xf3400 000)
eden space 12160K, 99% used 1 [0xf2800000, 0xf33d8700, 0xf33e0000)
from space 64K, 0% used 2 [0xf33f0000, 0xf33f0000, 0xf3400000)
to space 64K, 0% used [0xf33e0000, 0xf33e0000, 0xf33f0000)
concurrent mark-sweep generation total 53248K, used 932K 3 [0xf3400000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 53248K, 1% used [0xf3400000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000)
0.714918: [ParNew: 12129K->0K(12224K), 0.0119368 secs] 13062K->1362K(65472K)
Heap after GC invocations=2:
Heap par new generation total 12224K, used 0K [0xf2800000, 0xf3400000, 0xf3400000)
eden space 12160K, 0% used 4 [0xf2800000, 0xf2800000, 0xf33e0000)
from space 64K, 0% used 5 [0xf33e0000, 0xf33e0000, 0xf33f0000)
to space 64K, 0% used [0xf33f0000, 0xf33f0000, 0xf3400000)
concurrent mark-sweep generation total 53248K, used 1362K 6 [0xf3400000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 53248K, 2% used [0xf3400000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000)
} , 0.0134874 secs]
Before GC, Eden space is 100% almost full
Before GC, From space is 0%
Before GC, Old heap space has about 932KB
After GC, Eden space is 0%
After GC, From space is 0%
After GC, Old heap space has about 1362KB, about 430KB has been promoted
11.1.3.4 Tracking Young GCs that Copy Objects (Throughput apps)
A review of the numbers in " 11.1.1 Snippet from a Copy GC" through " 11.1.3.3 Snippet of a Promotion GC with the promoteall Modifier" will reveal how the copy percentage changes from young GC to young GC. Without the promoteall modifier, this percentage reduces until there are more live objects in the semi-space than are allowed. At that time, these objects are promoted to the old heap, and the threshold is reset to its starting value. This can now be seen by enabling the - XX:+PrintTenuringDistribution option.
11.1.3.4.1 Using the PrintTenuring Distribution
java -server -Xms512m -Xmx512m -XX:NewSize=64m \
-XX:MaxNewSize=64m XX:SurvivorRatio=2 \
-
XX:+UseConcMarkSweepGC
-XX:+UseParNewGC \
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps \
-XX:+PrintHeapAtGC -XX:+PrintTenuringDistribution application
0.729752: [GC {Heap before GC invocations=1:
Heap
par new generation total 18432K, used 12827K [0xf2800000, 0xf4000000, 0xf4000000)
eden space 12288K, 99% used [0xf2800000, 0xf33ff840, 0xf3400000)
from space 6144K, 8% used [0xf3a00000, 0xf3a87780, 0xf4000000)
to space 6144K, 0% used [0xf3400000, 0xf3400000, 0xf3a00000)
concurrent mark-sweep generation total 40960K, used 195K [0xf4000000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 40960K, 0% used [0xf4000000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000) 0.730717: [ParNew
Desired survivor size 3145728 bytes, new threshold 31 (max 31)
- age 1: 600176 bytes, 600176 total 1
- age 2: 512592 bytes, 1112768 total 2
: 12827K->1088K(18432K), 0.0275376 secs] 13023K->1283K(59392K) Heap after GC invocations=2:
Heap
par new generation total 18432K, used 1088K [0xf2800000, 0xf4000000, 0xf4000000)
eden space 12288K, 0% used [0xf2800000, 0xf2800000, 0xf3400000)
from space 6144K, 17% used [0xf3400000, 0xf3510078, 0xf3a00000)
to space 6144K, 0% used [0xf3a00000, 0xf3a00000, 0xf4000000)
concurrent mark-sweep generation total 40960K, used 195K [0xf4000000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 40960K, 0% used [0xf4000000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000)
} , 0.0291855 secs]
- Lot 1, size 600K
- Lot 2, size 500K
There are times when tenuring can help application performance. When intermediate objects are given enough time that they become temporary objects, they are collected before they are ever promoted to the old heap. It is for this reason that tenuring is used in the first place. This strategy works well for many classes of application. Determining whether an application will benefit from copying, or from promoting all live objects to the old heap, will help developers configure applications for optimal behavior.
The throughput collector works with very well with large young generation heaps, and works on the idea that copy collection is very efficient. Copy collection is directly proportional to the size of the live objects, and heap is automatically compacted with every collection decreasing locality and fragmentation problems. Since the collector is parallel, pause times are divided by the degree of parallelism, and are lower. The frequency of collection decreases as heap sizes are larger. So the effect is low pause with decrease in frequency.
11.1.3.4.2 Using AdaptiveTenuring
When this is enabled, -XX:+UseAdaptiveSizePolicy, the throughput collector automatically sizes the young generation heap and selects an optimal survivor ratio to bring down the pause and frequency. This should always be turned on, until unless the developer has analyzed the application behavior with the GC analyzer and is sizing the heap manually.
11.1.3.5 Reducing The Size Of Promoted or Tenured Objects
Depending on the application's behavior, merely increasing the size of the young generation may help by allowing long-term objects to become intermediate objects, and intermediate objects to become temporary objects (see 11.1.3.4 Tracking Young GCs that Copy Objects). Increasing the young generation may help, but it does increase the time that each young collection takes. This might be alleviated now with the parallel collectors, and bigger young generations can be used with out comprising on the collection time.
The next step is code inspection. There are a few ways to reduce the time it takes to tenure or promote objects.
The easiest is to find objects that are kept alive longer than necessary, and to stop referring to them as soon as they are no longer needed. Sometimes, this is as simple as setting the last reference to null as soon as the object is no longer needed.
Also look for objects that are unnecessary in the first place, and simply don't create them. If, as is typical, these are temporary objects, avoiding their creation will help indirectly, by reducing the frequency of young GCs. If they are long-term or intermediate objects, the benefit is more direct: they need not be copied or promoted.
Sometimes it is not as simple as just not creating an object. Developers may be able to reduce object sizes by making non-static variables static, or by combining two objects into one, thus reducing tenure or promotion time.
11.1.3.6 Disadvantages of Pooling Objects
In general, object pooling is not usually a good idea. It is one of those concepts in programming that is too often used without really weighing the costs against the benefits. Object reuse can introduce errors into an application that are very hard to debug. Furthermore, retrieving an object from the pool and putting it back can be more expensive than creating the object in the first place, especially on a multi-processor machine, because such operations must be synchronized.
Pooling could violate principles of object-oriented design (OOD). It could also turn out to be expensive to maintain, in exchange for benefits that diminish over time, as garbage collectors become more and more efficient and collection costs keep decreasing. The cost of object creation will also decrease as newer technologies go into VMs.
Because pooled objects are in the old generation, there is an additional cost of re-use: the time required to clean the pooled objects readying it for re-use. Also, any temporary objects created to hold newer data are created in the younger generation with a reference to the older generation, adding to the cost of young GCs .
Additionally, the older collector must inspect pooled objects during every collection cycle, adding constant overhead to every collection.
11.1.3.7 Advantages of Pooling Objects
The main benefit of pooling is that once these objects are created and promoted to the old generation, they are not created again, not only saving creation time but also reducing the frequency of young-generation GCs. There are three specific sets of factors that may encourage adoption of a pooling strategy.
The first is the obvious one: pooling of objects that take a long time to create or use up a lot of memory, such as threads and database connections.
Another is the use of static objects. If no state must be maintained on a per-object basis, this is a clear win. A good general rule is to make as many of the application's objects and member variables static as possible.
When it is not possible to make an object static, imposing a policy of one object per thread can work just fine. Such cases are good opportunities to take advantage of a static ThreadLocal variable. These are objects that enable each thread to know about its own instance of a particular class.
11.1.3.8 Seeking Statelessness
An application can achieve its maximum performance if the objects are all or mostly short-lived, and die while still in the young generation. To achieve such short lifetimes, the application must be essentially stateless, or at least maintain state for only a brief period. Minimizing statefulness helps greatly because the young generation's copying collector is very efficient at collecting dead objects. It expends no effort, just skips over them and goes on to the next object. By contrast any object that must be tenured or promoted imposes the cost of copying to a new area of memory.
11.1.3.9 Watching for References that Span Heaps
Developers should avoid creating ephemeral or temporary objects after objects are promoted to the old generation. If the application creates temporary objects that are referenced from objects in the old generation, then the cost of scanning these objects is greater than the cost of scanning the references when they are in the young generation.
11.1.3.10 Flattening Objects
Keeping objects flat, avoiding complex object structures, spares the collector the task of traversing all the references in them. The fewer references there are, the faster the collector can work - but note that trade-offs between good OOD and high performance will arise.
11.1.3.11 Watching for Back References
Look for unnecessary back references to the root object, as these can turn a temporary object into a long-lived one - and can lead to a memory leak, as the reference may never go away.
11.1.3.12 Direct Creation Of Objects In Older Generation
Objects are now directly created in the older generation if the size of the young generation is small, and the size of objects are big. The option - XX:PretenureSizeThreshold=<byte size> in the concurrent collector that can be enabled to indicate the threshold for direct creation in the older generation. This could effectively be used for creation of caches, lookup tables, etc. which are long lived and do not have to go through a promotion cycle of being created in the younger generation and then being copied to the older generation. Use this option with care, since it can degrade performance instead of improving it. The default value is 0 i.e., no objects are created directly in the older generation.
11.1.3.12.1 Snippet showing direct creation of objects in the older heap
Snippet 1
2.23256: [GC {Heap before GC invocations=5:
Heap
par new generation total 9216K, used 7395K [0xec800000, 0xed400000, 0xed400000)
eden space 6144K, 99% used [0xec800000, 0xecdf7fe0, 0xece00000)
from space 3072K, 41% used [0xed100000, 0xed240cd0, 0xed400000)
to space 3072K, 0% used [0xece00000, 0xece00000, 0xed100000)
concurrent mark-sweep generation total 151552K, used 195K [0xed400000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 151552K, 0% used [0xed400000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000)
2.23348: [ParNew: 7395K->1445K(9216K), 0.0459140 secs] 7590K->1641K(160768K)
Heap after GC invocations=6:
Heap
par new generation total 9216K, used 1445K [0xec800000, 0xed400000, 0xed400000)
eden space 6144K, 0% used [0xec800000, 0xec800000, 0xece00000)
from space 3072K, 47% used [0xece00000, 0xecf697a8, 0xed100000)
to space 3072K, 0% used [0xed100000, 0xed100000, 0xed400000)
concurrent mark-sweep generation total 151552K, used 195K [0xed400000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 151552K, 0% used [0xed400000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000)
} , 0.0475033 secs] Snippet 2
2.40279: [GC {Heap before GC invocations=6:
Heap
par new generation total 9216K, used 7557K [0xec800000, 0xed400000, 0xed400000)
eden space 6144K, 99% used [0xec800000, 0xecdf8020, 0xece00000)
from space 3072K, 47% used [0xece00000, 0xecf697a8, 0xed100000)
to space 3072K, 0% used [0xed100000, 0xed100000, 0xed400000)
concurrent mark-sweep generation total 151552K, used 390K [0xed400000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 151552K, 0% used [0xed400000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000)
2.40399: [ParNew: 7557K->1441K(9216K), 0.0249896 secs] 7948K->1832K(160768K)
Heap after GC invocations=7:
Heap
par new generation total 9216K, used 1441K [0xec800000, 0xed400000, 0xed400000)
eden space 6144K, 0% used [0xec800000, 0xec800000, 0xece00000)
from space 3072K, 46% used [0xed100000, 0xed2687e8, 0xed400000)
to space 3072K, 0% used [0xece00000, 0xece00000, 0xed100000)
concurrent mark-sweep generation total 151552K, used 390K [0xed400000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 151552K, 0% used [0xed400000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000)
} , 0.0268922 secs] Walking through the two snippets above, from snippet 1 -- snippet 1 is GC invocation number 5 -- the After GC component shows old generation occupancy is 195K. In snippet 2 -- snippet 2 is GC invocation number 6 --, the Before GC component shows that the old generation size has increased to 390K. This means that objects have been directly created in the older generation. This happens if the size of the objects are quite big compared to the younger generation, so instead of creating them in the young generation, the allocator directly creates them in the older generation.
11.1.3.13 Using NIO
New IO is new way of doing IO operations with JDK 1.4. NIO supports multiplexed IO, a more efficient way of performing IO operations, and this should help bring down the number of threads used to process socket connections. Formerly, every socket connection used to be processed with a dedicated thread. Multiplexed IO allows many socket connections to be polled by a fewer threads. So a thread pool could be used to process the connections. Decreasing the number of threads brings down the number of objects, reduces memory footprint, decreases scheduling contention, while increasing performance.
NIO offers direct buffers which maybe used to create storage outsdie of the Java heap - means avoiding GC --, and can be used to store long life objects like lookup tables, caches, etc. Also, with a direct buffer, the JVM will try to perform native IO operations directly, and this should avoid multiple copies - means reduction in the number of objects created.
NIO also offers MappedByteBuffer, an implementation of a direct buffer, but memory mapped. MappedByteBuffer enables mapping file contents directly to physical memory areas. This should speed large IO operations, and avoid multiple copies between various buffers, meaning less number of objects, and so reduced GC frequency.
11.1.3.14 Making immutable objects mutable like using StringBuffers
Immutable objects serve a very good purpose but might not be good for garbage collection since any change to them would destroy the current object and create a new objects i.e., more garbage. Immutables by description, are objects which change very little overtime. But a basic object like String is immutable, and String is used everywhere. One way to bring down the number of objects created would be to use something like StringBuffers instead of Strings when String manipulation is needed.
11.1.3.15 RMI Initiated Distributed GC
RMI's distributed garbage collection (DGC) algorithm depends on the timeliness of local garbage collection (GC) activity to detect changes in the local reachability states of live remote references, and thus ultimately to permit collection of remote objects that become garbage. Local GC activity that results from normal application execution is often but not necessarily sufficient for effective DGC-- a local GC implementation does not generally know that the detection of particular objects becoming unreachable in a timely fashion is desired for some reason, such as to collect garbage in another Java virtual machine (VM). Therefore, an RMI implementation may take steps to stimulate local GC to detect unreachable objects sooner than it otherwise would.
The local GC initiated is a Full GC, and the default period is 60000 ms. This can be postponed or disabled completely to avoid Full GCs by setting the following options:
-Dsun.rmi.dgc.server.gcInterval=0x7FFFFFFFFFFFFFFE -Dsun.rmi.dgc.client.gcInterval=0x7FFFFFFFFFFFFFFE -XX:+DisableExplicitGC
11.1.3.16 Controlling Degree of Parallelism
The default degree of parallelism, as many threads as the number of CPUs, could degrade collection times especially in concurrent situations with other applications. The collection performance could be improved by reducing the parallelism using the - XX:ParallelGCThreads option.
11.1.3.17 References - Soft, Weak, Phantom
Soft,Weak, Phantom References are used to implement data structures like caches. But this is expensive in terms of garbage collection, especially with the concurrent collector. So if possible avoid or use sparingly, especially Weak references as these are collected at every GC cycle.
11.1.3.18 Finalizers
If possible just avoid finalizers as they are very expensive in terms of GC, since the collector needs to do extra processing [ 30] and run the finalize method if implemented. Another drawback with Finalizers is that finalizer chaining is not automatic and needs to be done explicitly. Not being aware of this, leads to unexpected behavior like holding onto precious resources and maybe memory leaks.
11.1.3.19 Permanent Generation Expansion
Sometimes you will see Full GCs in the log file, and this could be due to the permanent generation being expanded - most interactive applications like Forte Studio have this problem. This could be prevented by specifying a bigger permanent generation using the - XX:PermSize and - XX:MaxPermSize options.
For example:
java -Xms512m -Xmx512m -XX:NewSize=256m -XX:MaxNewSize=256m \
-XX:SurvivorRatio=2 - XX:PermSize=64m - XX:MaxPermSize=64m application 11.2 Old-Generation Collection Times
11.2.1 Low Pause collectors
While the young-generation collector is a stop-the-world collector but parallel, the old generation concurrent collector runs concurrently with the application. The old collection is made in four stages, two of which are stop-the-world. The stages are:
- Initial Mark phase (stop-the-world)
- Concurrent Mark + precleaning phase
- Remark phase (stop-the-world)
- Concurrent Sweep-reset-phase
11.2.1.1 Initial Mark Phase
When the free memory in the old heap drops below a certain percentage, usually between 40% and 32%, the old-generation collector starts an "initial mark" phase. The initial mark phase takes a snapshot of the heap, and starts traversing the object graph to distinguish the referenced and unreferenced objects. Marking, in a nutshell, is the process of tagging each object that is reachable , so that it can be preserved when unmarked objects are collected.
11.2.1.1.1 Snippet of an Initial Mark Phase
97.3699: [GC [1 CMS-initial-mark: 95031K(139264K)] 99056K(157696K), 0.0109899 secs1]1.1. stop-the-world pause in seconds
11.2.1.2 Concurrent Marking Phase
Once the intial-mark phase is completed, ie., a snapshot of the heap is taken, the marking or tagging of live objects is performed concurrently.
11.2.1.2.1 Snippet of an Concurrent Mark + PreCleaning Phase
97.3913: [CMS-concurrent-mark-start]
138.425: [CMS-concurrent-mark: 28.8972/41.0341 secs]
1.Total concurrent mark time in seconds
2.Current time on a CPU
138.479: [CMS-concurrent-preclean-start]
139.412: [CMS-concurrent-preclean: 0.8262/0.9331 secs]
1.92Total concurrent precleaning time in seconds
2.Current time on a CPU
3.
11.2.1.3 Remark Phase
Once the concurrent mark + precleaning phase is complete, the "remark" phase begins. The collector re-walks parts of the object graph that have potentially changed after they were scanned initially.
11.2.1.3.1 Snippet of a Remark Phase
139.766: [GC139.766: [dirty card accumulation, 0.0042464 secs]139.771: [dirty card rescan, 0.0003622
secs]139.771: [remark from roots, 0.4646618 secs]140.236: [weak refs processing, 0.0104430 secs] [1 CMS-
remark: 95031K(139264K)] 104620K(157696K), 0.4803311 secs1]
1. stop-the-world remark time
11.2.1.4 Sweep Phase
The concurrent sweep phase follows the remark phase. In this phase memory is recycled by clearing the unreferenced objects.
11.2.1.4.1 Snippet of Sweep Phase
140.247: [CMS-concurrent-sweep-start]
227.279: [CMS-concurrent-sweep: 64.8272/87.0311 secs]
1.Total concurrent sweep time in seconds
2.Current time on a CPU
Note:
- If the object creation rate is too high, the concurrent collector will be unable to keep up with the collection. The free threshold may drop below 5%, and the old generation, instead of using the concurrent collector, will employ the traditional mark-sweep, stop-the-world collector to collect the older heap.
- Another workaround is to start the concurrent collector early by specifying the -XX:CMSInitiatingOccupancyFraction=<percent> option. Set this to 30% or lower so that the concurrent collection can be initiated earlier.
11.2.1.5 Snippet of Traditional Mark-Sweep GC
0.1839: [Full GC {Heap before GC invocations=9:
Heap
par new generation total 49152K, used 40869K [0xd6800000, 0xda800000, 0xda800000)
eden space 32768K, 74% used [0xd6800000, 0xd7fe94f0, 0xd8800000)
from space 16384K, 100% used [0xd9800000, 0xda800000, 0xda800000)
to space 16384K, 0% used [0xd8800000, 0xd8800000, 0xd9800000)
concurrent mark-sweep generation total 458752K, used 3351K [0xda800000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 458752K, 0% used [0xda800000, 0xf6800000)
concurrent-mark-sweep perm gen total 17416K, used 12459K [0xf6800000, 0xf7902000, 0xfa800000)
CompactibleFreeListSpace space 17416K, 71% used [0xf6800000, 0xf7902000)
60.1849: [ParNew
Desired survivor size 8388608 bytes, new threshold 31 (max 31)
- age 1: 5582064 bytes, 5582064 total
: 40869K->5478K(49152K), 0.4599039 secs]60.6449: [CMS61.267: [dirty card accumulation, 0.0121228 secs]61.2793: [dirty card rescan, 0.0009173 secs]61.2803: [remark from roots, 0.0922212 secs]61.3727: [weak refs processing, 0.0100280 secs]: 19659K->19059K(458752K), 0.9234530 secs] 44221K->24538K(507904K) Heap after GC invocations=10:
Heap
par new generation total 49152K, used 5478K [0xd6800000, 0xda800000, 0xda800000)
eden space 32768K, 0% used [0xd6800000, 0xd6800000, 0xd8800000)
from space 16384K, 33% used [0xd8800000, 0xd8d59b48, 0xd9800000)
to space 16384K, 0% used [0xd9800000, 0xd9800000, 0xda800000)
concurrent mark-sweep generation total 458752K, used 19059K [0xda800000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 458752K, 4% used [0xda800000, 0xf6800000)
concurrent-mark-sweep perm gen total 20768K, used 12459K [0xf6800000,0xf7c48000, 0xfa800000)
CompactibleFreeListSpace space 20768K, 59% used [0xf6800000, 0xf7c48000)
} , 1.3867174 secs] 11.2.2 Throughput Collectors
While the young-generation collector is parallel, the old generation collection is executed using the stop-the-world, mark-sweep-compact collector.
11.2.3 Observations Regarding Old-Generation Collections
11.2.3.1 Undersized Old Heaps
After a sweep phase, the size of the heap collected should be equal to or greater than the size of an active duration. Depending on the heap size, more than one active-duration segment could be in the old generation. Based on the time of the active duration, and the frequency of the old-generation GC, all of the objects in the active duration could be collectable.
The GC analyzer provides this ratio, (size of active durations / resize heap space). This value should be less than 1. A value greater than 1 indicates that, when an old generation GC takes place, there are active-duration segments still alive. With the ratio greater than 1, the call rate could be putting pressure on the older generation, forcing on it more frequent collections. If the ratio is too high, it can actually force the old generation to employ the traditional mark-sweep collector. Simply increasing the size of the old-generation heap can alleviate this pressure. Note, though, that too great an increase could lead to a smear effect ( 16.2.6 Locality of Reference Problems with an Oversized Heap).
The GC analyzer is able to determine the pressure on the older collector, as is described in " 13. Detection of Memory Leaks."
11.2.3.2 Checks and Balances
At the end of an active duration, the amount of heap resized should be equal to the size of the objects promoted. If there are lingering references or if the timers are not very sensitive to the actual duration, then a memory leak may result. Memory leaks will fill up the old heap, degrading the old collector's performance and increasing the frequency of the old-generation GC. The GC analyzer reports such behavior.
For a final verification, at the end of the application run, the total size of the old generation objects collected should be compared to the total size of the objects promoted. These should be approximately equal. See " 13. Detection of Memory Leaks" for more details.
12. Reducing the Frequency of Young and Old GCs
The frequency of the young GC is directly related to:
- The young generation size
- The call-setup rate
- The rate of object creation
- The objects' lifetimes
12.1 The Young Generation Size - EDEN, Semi-space and Survivor Ratio
Young generation is now made up of Eden space and a semi-space, controlled by the survivor ratio (see 3.1).
Increasing the Eden reduces young-GC frequency but increases individual collection times, because the promotion size could be higher. On the other hand, a ratio of temporary to long-lived objects that is very high could decrease the collection time, as more intermediate objects could die before a tenure GC or a promotion GC occurs. Changing the Eden size entails a trade-off between decreasing frequency and increasing collection times. See " 11.1 Young-Generation Collection Times" and " 11.2 Old-Generation Collection Times" for details on the effects of a change in the Eden size on frequency and collection time.
12.2 The Incoming Call-Setup Rate and the Rate of Object Creation
Frequency of GC is directly proportional to the call-setup rate and to the size of the objects created per call setup. The GC analyzer reports, per call setup, the total size of objects created, and of the temporary and long-term data created, and the average object size. This information can be used to reduce unnecessary object creation and optimize the application code.
12.3 Object Lifetimes (Low Pause apps and Throughput apps)
The frequency of young GC is also dependent on the lifetimes of the objects created. Long lifetimes lead to unnecessary tenuring in the young generation. Using the promoteall modifier could alleviate this problem, by shifting to the old generation's collector the burden of collecting, sooner or later, all objects alive at the beginning of any young GC. For details on using the promoteall modifier, see " 11.1.3.2 Simulated promoteall Modifier Usage".
The lifetimes of objects have a big impact on application performance, as they affect GC frequency, collection times, and the young and old heaps. If objects never die, then at some time there will be no more heap space available and an out-of-memory exception will arise.
Increased object lifetimes reduce old-generation memory available and lead to more frequent old-generation GCs. Object lifetimes also affect the young generation, because the promotion size increases as lifetimes increase, and in turn increases collection times. For maximum performance, references to objects should be nulled when they are no longer needed.
The analyzer determines the number of active call setups currently alive in the old heap. It does so by taking into account the active duration of call setups and the call-setup rate. If the application is well behaved, the entire active-duration segment should be freed at the end of the live time of the call setups. The analyzer verifies this by calculating the size of the heap that is freed and correlating this information with the size of the active-duration segments that should have been freed. Some of the ratios are shown below; for example:
CPS = 200 // Call setups per second
Call-setup rate = 1 call every 5 ms
Active duration of each call setup = 32,000 ms -> (40)
Number of call setups in active duration = 6,400
Number of promotions in active duration = 79.74
Long-lived objects (promoted objects)
/ active duration = 109,334,972 bytes -> (41)
Number of active durations freed by old GC = 6.28 -> (42)
Average resized memory size = 687,152,824 bytes -> (43)
Ratio of live to freed data = 0.83
Time when init GC might take place = 109,267 ms
Periodicity of old GC = 166,000 ms -> (44)
From the ratios above, the number of active durations that should ideally be freed would be:
= (periodicity of old GC / active duration of each call setup) = ((#44) / (#40))
= (166,000 / 32,000) = 5.185
-> (45)
From above, the number of active durations freed (#42) is 6.28, which indicates call setups are being freed, and old-heap free memory is in good shape. If the ratio (#42) / (#45) is very low, less than 1, then the old-heap sizing should be inspected, or object references are lingering even after the call setup that generated them is no longer active.
Note: A developer should size the heap to hold at least two or more active durations, so that when an old GC takes place, at least 1 or more active durations are freed. From the model above, (#42 = #43 / #41), 6.3 active durations were dead at the end of 160,000 ms. Comparing this to the theoretical or ideal number that could be dead at the time of old GC (#45) reveals that the application is freeing its references properly.A good way to detect memory leaks is to compare the total size of the objects promoted to the total size of the objects reclaimed for the entire test. Any substantial difference signals a leak. Memory leaks lead to various problems:
- Increase in frequency of old GC
- Increase in collection times
- Execution of the less efficient mark-sweep collector
- An out-of-memory exception
Ratios from the GC analyzer for memory verification:
Total size of objects promoted:
= 1,661,646 KB |
-> (51) |
Total size of objects fully GC collected in application run:
= 1,307,750 KB |
-> (52) |
The difference should be one or more active-duration segments:
= (#51) - (#52)
= 1,661,646 - 1,307,750
|
||
= 353,896 KB |
-> (53) | |
= (#53) / ((#42) / (#41)
= (353,896 * 1,024) / (687,152,824 / 5.22)
= 3.31 active durations
|
14. Finding the Optimal Call-Setup Rate by Using the Rates of Creation and Destruction
Using the call-setup rate as input, the analyzer provides various call-setup rate calculations, which can be used to determine the following:
- Average number of objects created per call setup
- Average size of each object
- Total size of temporary objects
- Total size of long-lived objects
If the application is creating too many objects, either temporary or long-lived, developers should devise a strategy to maintain an optimum ratio of temporary to long-lived objects. This tuning will help reduce the young GC collection time and the frequency of collection.
Based on the size and number of objects promoted to the old generation, developers can adopt a strategy of sizing the heap to accommodate the desired maximum call-setup rate. A case for pooling could also be made, if the average number of the long-lived objects is large, and it takes many computational cycles to create the objects for each call setup.
Call setups per second (CPS) = 200
Call-setup rate, 1 call every = 5 ms
Call setup before young gen GC = 80.26
Size of objects / call setup = 78,390 bytes
Size of short-lived objects / call = 61,307 bytes
Size of long-lived objects / call setup = 17,084 bytes
Ratio of young GC (short/long) objects / call setup = 3.59
Average number of objects promoted / call setup = 367
15. Learning the Actual Object Lifetimes
It is very important to know the lifetime of an object, whether it is temporary or long-lived. Because objects are associated with call setups, knowing the real lifetime will make it possible to size both the young- and the old-generation heaps properly. If this could be exactly calculated, then the young-generation semi-space could be sized to destroy as many short-lived objects as possible, and promote only the necessarily long-lived objects. The promoteall modifier could be used if the ratio of temporary objects to long-lived objects is low.
Knowing the real lifetime also helps developers size the old-generation heap optimally, to accommodate the desired maximum call-setup rate. It also helps detect memory leaks by identifying objects that linger beyond their necessary lifetime. The GC analyzer can currently detect active-duration segments but not individual object lifetimes. The JVMPI (Java Virtual Machine Profiler Interface) [ 25] can be used to report the lifetime of individual objects, and this information can then be integrated with the output of the GC analyzer to verify heap usage accurately.
16. Sizing the Young and Old Generations' Heaps
Heap sizing is one of the most important aspects of tuning an application, because so many things are affected by the sizes of the young- and old-generation heaps:
- Young-GC frequency
- Young-GC collection times
- The number of short-term and long-term objects
- The number of call setups received before promotion
- Promotion size
- Number of active-duration segments
- Old-GC frequency
- Old-GC collection times
- Old-heap fragmentation
- Old-heap locality problems
16.1 Sizing the Young Generation
16.1.2 Low Pause apps
The young generation's copying collector does not have fragmentation problems, but could have locality problems, depending on the size of the generation. The young heap must be sized to maximize the collection of short-term objects, which would reduce the number of long-term objects that are promoted or tenured. Frequency of the collection cycle is also determined by heap size, so the young heap must be sized for optimal collection frequency as well.
Basically, finding the optimal size for the young generation is pretty easy. The rule of thumb is to make it about as large as possible, given acceptable collection times. There is a certain amount of fixed overhead with each collection, so their frequency should be minimized.
16.1.3 Throughput apps
The young generation is sized the opposite with the throughput collector. Instead of using smaller younger generation to keep the pause down, the young generation is made very big, maybe in gigabytes so that the throughput collector with AdaptiveTenuring can make use of this space to parallelize young generation collection. Since throughput or enterprise applications are not pause sensitive, this gives them more application time and when a collection does occur, the collection is parallelized over many CPUs, usually more than 8.
16.2 Sizing the Old Generation
16.2.1 Low Pause apps
The concurrent collector manages the old-generation heap so it needs to be carefully sized, taking into account the call-setup rate and active duration of call setups. An undersized heap will lead to fragmentation, increased collection cycles, and possibly a stop-the-world traditional mark-sweep collection. An oversized heap will lead to increased collection times and smear problems ( 16.2.6 Locality of Reference Problems with an Oversized Heap). If the heap does not fit into physical memory, it will magnify these problems.
The GC analyzer helps developers find the optimal heap size by providing the following information:
- Tenure- and promotion-GC information
- Old-generation concurrent collection times
- Traditional-GC information
- Percentage of time spent in young- and old-generation GC
Reducing the percentage of time spent in young and old GC will increase application efficiency.
16.2.2 Throughput apps
Similar to the young generation sizing, the throughput apps usually have a bigger younger generation, and a smaller older generation. The idea is to increase the number of temporary objects and minimize the intermediate objects. Only needed long term objects get stored in the older heap.
16.2.3 An Undersized Heap and a High Call-Setup Rate
As the call-setup rate increases, the rate of promotion increases. The old heap fills faster, and the number of active-duration segments rises. Frequency of old-generation GCs increases because the older generation fills up faster. If the pressure on the old collector is heavy enough, it can force the old collector to revert to the traditional mark-sweep collector. If the old collector is still unable to keep up, the system can begin to thrash, and finally, throw an out-of-memory exception.
Increasing the old-generation heap size can alleviate this pressure on the old collector. The heap should be enlarged to the point that a GC collects from one to three active-duration segments. Use the following information from the GC analyzer to determine whether the heap size is configured properly:
- Initial mark threshold
- Remark threshold
- Number of bytes collected by the sweep phase
- Number of active-duration segments collected in the collection
- Number of active-duration segments promoted
16.2.4 An Undersized Heap Causes Fragmentation
An undersized heap can lead to fragmentation because the old-generation collector is a mark-sweep collector, and hence never compacts the heap. When the collector frees objects, it combines adjacent free spaces into a single larger space, so that in can be optimally allocated for future objects. Over time, an undersized heap may begin to fragment, making it difficult to find space to allocate an object. If space cannot be found, a collection takes place prematurely, and the concurrent collector cannot be used, because that object must be allocated immediately. The traditional mark-sweep collector runs, causing the application to pause during the collection. Again, simply increasing the heap size, without making it too large, could prevent these conditions from arising.
If the heap does fragment, and the call-setup rate slows, then the fragmentation problem will resolve itself. As more and more objects die and are collected, space in the heap becomes available again. Take the extreme example, where there are no call setups for a period of time greater than an active duration. Now all call-setup objects will be collected at the next GC, and the heap will no longer be fragmented.
Note:
- The -XX:+UseCMSCompactAtFullCollection option can be used to enable compaction of the old generation heap. This hurts performance but will eliminate the fragmentation problem.
- The above option can be used in conjunction with this option to -XX:CMSFullGCsBeforeCompaction=0 to force compaction.
- The -XX:CMSInitiatingOccupancyFraction=< percent> can be set lower so that the concurrent collection can be started earlier to reduce heap fragmentation. Set this to 30 or lower.
16.2.5 An Oversized Heap Increases Collection Times
When using the concurrent collector, the cost of each collection is directly proportional to the size of the heap. So an oversized heap is more costly to the application. The pause times associated with the collections will still not be that bad, but the time the collector spends collecting will increase. This does not pause the application, but does take valuable CPU time away from the application.
To aid its interaction with the young collector, the old heap is managed using a card table, in which each card represents a subregion of the heap. Increasing the heap size increases the number of cards and the total size of the data structures associated with managing the free lists in the old collector. An increased heap size and a high call rate will add to the pressure on the old collector, forcing it to search more data structures, and thus increasing collection times.
16.2.6 Locality of Reference Problems with an Oversized Heap
Another problem with an oversized heap is "locality of reference." This is related to the operating system, which manages memory. If the heap is larger than physical memory, parts of the heap will reside in virtual memory. Because the concurrent collector looks at the heap as one contiguous chunk of memory, the objects allocated and deallocated could reside anywhere in the heap. That some objects will be in virtual memory leads to paging, translation-lookahead-buffer (TLB) misses, and cache-memory misses. Some of these problems are solved by reducing the heap size so that it fits entirely in physical memory, but that still does not eliminate the TLB misses or cache-memory misses, because object references in a large heap may still be very far away from each other.
This problem with fragmentation and locality of reference is called a "spread," or " smear," problem. Optimizing heap sizes will help avoid this problem.
16.2.6.1 Using ISMs and Variable Page Sizes To Overcome Locality Problems
TLB misses can be minimized or almost eliminated by using Intimate Shared Memory (ISM) on Solaris. ISM makes available 4 MB pages to the JVM. So instead of accessing many 8KB pages, default page size, less number of pages are accessed since the page size is now 4 MB. Striding across the heap will incur less page faults.
ISM can be enabled by using -XX:+UseISM option. This option is operating system dependent and works only on Solaris. Changes need to made to /etc/system file to include the following parameters:
set shmsys:shminfo_shmmax=0xffffffff
set shmsys:shminfo_shmseg=32
A system reboot is also needed to make ISM work.
ISM is a kludge way of making use of bigger page sizes. Solaris 9 offers an elegant way of overcoming this problem by offering variable pages sizes. Page sizes can be varied from 8KB to 4MB. This can be enabled with the following option: -XX:+UseMPSS [ 28].
16.3 Sizing the Heap for Peak and Burst Configurations
Developers should test the application under expected sustained peak and burst configuration loads, to discover whether collection times and frequency are acceptable at maximum loads. The heap size should be set to enable maximum throughput under these most demanding conditions. Far better to discover the application's limitations before it encounters peak and burst loads during actual operation.
17. Determining the Scalability and Execution Efficiency of a Java Application
As was discussed in ( 6. How GC Pauses Affect Scalability and Execution Efficiency), the serial parts of an application greatly reduce its scalability on a multi-processor machine. One of the principal serial components of a Java application is its garbage collection. The concurrent collection greatly reduces the serial nature of old-generation collection, but young-generation collection remains serial.
The GC analyzer calculates the effects of young- and old-generation GCs. It uses this information to determine the execution efficiency of the application. This, in turn, can be used to reduce the serial percentage and increase scalability. Output from the GC analyzer also helps developers evaluate other solutions, such as running multiple JVMs or using the concurrent collector.
17.1 GC Analyzer Snippet Showing the Cost of Concurrent GC and Execution Efficiency
Execution efficiency of application:
GC Serial portion of application = 23.86%
Actual CPUs = 1
CPUs used for concurrent processing = 0.41
Application Speedup = 0.48
Application Execution efficiency = 0.48
Application CPU Utilization = 47.85 %
Concurrent GC CPU Utilization = 52.15 %
In the above snippet, the serial percentage is very high, and needs to be reduced to less than 10%. The application execution efficiency should be increased to above 0.9, while lowering the concurrent cost to less than 5%. See section 11 on how to achieve this.
18. Other Ways to Improve Performance
Other means to improve application performance on Solaris :
- using the Solaris RT (real-time) scheduling class
- using the alternate thread library (/usr/lib/lap), which is the default thread library on Solaris 9
- using hires tick to change clock resolution
- processor sets
- binding process to CPUs
- turning of interrupts
- modifying the dispatch table
- tuning fsflush
Experimenting with the JVM options that are available, and re-testing with various combinations until an optimal configuration is found, is one way to change application behavior and get more performance without making any code changes.
19. On the Horizon & Research Ideas
19.1 Self Tuning JVM
Modeling described above can be used to tune GC and in turn application behavior to improve application perofrmance. But this modeling process is static ie. verbose:gc logs are needed to analyze application behavior and then changes are made to the Java code and Java environment. How about making this dynamic by incorporating modeling into the JVM itself ? The JVM could interact with the garbage collector to construct the model dynamically and based on criteria like throughput, pause, sequential overhead, etc. adjust the environment to meet the cirteria. This idea was presented at USENIX, JVM02-WIPS [ 2].
19.2 Ergonomics
Future JVMs might provide modes where the developer might not have to remember the different tuning options, and instead specify a desired functionality like realtime performance, pause or throughput oriented, etc., and the JVM would automatically choose the right collector and the environment suitable for this.
19.3 Hardware based Garabage collection
Garbage collection is reaching a stage where it is now stable and so can be supplemented in hardware through GC specific instructions or a GC accelerator. This should allow GC issues to become a non-issue, and allow Java application performance to reach or exceed that of C++ applications.
19.4 JSR 174 - Monitoring and Management Specification For Java
This is a specification for monitoring and management of the JVM. These APIs will provide the ability to monitor the health of the JVM at run-time such as:
Health Indicators
- Class load/unload
- Memory allocation statistics
- Garbage collection statistics
- Monitor info & statistics
- Thread info & statistics
- Just-in-Time statistics
- Object info (show/count all objects in the Java heap)
- Underlying OS and platform info
- etc.
Run-Time Control
- Minimum heap size
- Verbose GC on demand
- Garbage collection control
- Thread creation control
- Just-in-Time compilation control
- etc.
From a GC and modeling perspective, the Verbose GC on demand, GC statistics, Memory statistics, Object info will allow the modeling to be precise and dynamic. There is no mention of controlling the JVM environment, else this could have been used to implement a self-tuning VM. Maybe an addendum can be made to this specification to allow this so that finer control over the VM could be exercised by the VM itself or from a monitor class of applications.
19.5 GC Portal & Automatic Tuning
GC Portal is an implementation of the model, and offers modeling and tuning of Java applications from a garbage collection perspective. Developers can submit log files, analyze them for performance problems and implement the tuning suggestions to improve application performance. Apart from the basic analysis, the portal offers empirical modeling - allows the most optimum environment to selected --, and what-if scenarios. What-if scenarios can be used to project application behavior without having to really the run the application under the different scenarios. For eg., what happens to throughput, GC pause, if the size of the young generation is increased/decreased ?
Empirical modeling and what-if scenarios can be used to tune application performance automatically. This feature will be part of the portal sometime in the near-future.
This portal exists within Sun today, and will be made available outside of Sun very soon.
19.6 Enhancements to the concurrent collector
The concurrent collector will be enhanced in future releases, and compaction of the older generation heap might happen automatically. Incremental functionality will be added to the collector so that the concurrent processing is done incrementally allowing the application threads to run more.
19.7 Enhancements to the parallel collector
The parallel collector is now stop-the-world. This behavior could be changed and application threads could run on some CPUs while collection happens on the other CPUs. This again allows more time for the application threads, and and not affect cache-affinity, a very important factor for performance.
Insight into how an application behaves is critical to optimizing its performance. A Java application's performance can be tuned and improved by a variety of means related to garbage collection. GC times can be reduced by employing the parallel and concurrent collectors, and by using properly sized young- and old-generation heaps.
Using the GC analyzer will enable developers to size the young- and old-generation heaps optimally. It will also point out what types of optimization might most fully enhance an application's performance. By analyzing, optimizing, and re-analyzing, developers can see which variations improve application performance. This is a continuous, iterative process that should eventually yield optimal performance from each application.
Now that some of the GC bottlenecks is in the processes of being eliminated, we should start seeing Java application performance improve, and maybe start closing the performance gap with C++. Java has an advantage of using dynamic adaptive compiler technology, meaning it can be adapted on the fly on newer hardware with no changes to existing Java code. So existing applications should immediately start seeing performance benefits with no code changes with the new collectors.
I would like to thank the Java VM, GC team, especially Y.S. Ramakrishna, Ross Knippel, John Coomes, Jon Masmitsu, and James Mcllree, as this work and the analysis would not have been possible without significant help from them. I would like to specially thank Y.S. Ramakrishna for taking the time to review this lengthy document. I would also like to thank Peter Jones for the RMI DGC information, Erice Reid for a tech. review through MDE Pubs Portal, Gal Shalif for some encouraging comments, Alka Gupta, S.R. Venkataramanan, Mayank Srivastava part of the GC Portal Team for any tuning suggestions. I would also like to thank my other colleagues in Market Development Engineering (IPE) at Sun for any help provided.
- Nagendra Nagarajayya, J. Steven Mayer, "Improving Java Application Performance and Scalability by Reducing Garbage Collection Times and Sizing Memory"
- Nagendra Nagarajayya, Alka Gupta, S.R. Venkatramanan, Mayank Srivastava, Self Tuning JVM To Improver Performance And Scalability, USENIX JVM02-WIPS, http://www.usenix.org/events/javavm02/tech.html
- David Detlefs, William D. Clinger, Matthias Jacob, and Ross Knippel, "Concurrent Remembered Set Refinement in Generational Garbage Collection", USENIX JVM'02, http://www.usenix.org/events/javavm02/tech.html
- Christine H. Flood and David Detlefs, Xiolan Zhang, Nir Shavit, "Parallel Garbage Collection for Shared Memory Multiprocessors", USENIX JVM'01, http://www.usenix.org/events/jvm01/flood.html
- Link /developer/onlineTraining/Programming/BasicJava2/oo.html
- Hotspot Whitepaper
- Monica Pawlan
- Paul R. Wilson, "Uniprocessor Garbage Collection Techniques"
- Jacob Seligmann and Steffen Grarup, "Incremental Mature Garbage Collection Using the Train Algorithm"
- Richard Jones, "The Garbage Collection page," http://www.cs.ukc.ac.uk/people/staff/rej/gc.html
- David Chase, "GC FAQ" HotSpot
- Derek White and Alex Garthwaite, "The GC interface in the Exact VM,"
- James Gosling, Bill Joy, and Guy Steele, "The Java Language Specification," Java SE Specifications
- Tony Eyers, and Henning Schulzrinne, "Predicting Internet Telephony Call Setup Delay", http://www.cs.columbia.edu/~hgs/papers/Eyer0004_Predicting.pdf
- M. Handley, H. Schulzrinne, E. Schooler, and J. Rosenberg, "SIP: session initiation protocol," Request for Comments 2543, Internet Engineering Task Force, Mar. 1999. http://www.ietf.org/rfc/rfc2543.txt
- Tony Eyers, and Henning Schulzrinne, "Predicting Internet Telephony Call Setup Delay"
- R. Fielding, J. Gettys, J. Mogul, H. Frystyk, L. Masinter, P. Leach, and T. Berners-Lee, "Hypertext Transfer Protocol -- HTTP/1.1," Request for Comments 2616, Internet Engineering Task Force, June 1999. http://www.ietf.org/rfc/rfc2616.txt
- Java Virtual Machine Profiler Interface (JVMPI)
- JDK 1.4.1 VM Options, here
- David Detlefs, Gcold
A1. GC Analyzer Usage
Usage:
gc_analyze.pl [-d] <gclogfile> <CPS> <active_call_duration> <CPUs> <application_run_time_in_ms>
| Parameter Name | Meaning |
|---|---|
| -d | Print out a detailed analysis and a summary |
| gclogfile | verbosegc log file to process |
| CPS | Call setups / second (default = 50) |
| active_call_duration | Duration call setup is active (default = 32,000 ms) |
| CPUs | Number of CPUs in the system (default = 1) |
| applcation_run_Time_in_ms | Number of ms application was run (default is calculated from GC time stamps) |
A2. GC Analyzer Output with -d Option
Running the GC analyzer with the -d option generates detailed output, which includes a summary. The detailed output provides in-depth insight into application behavior.
solaris% gc_analyze.pl -d ../12_12_60_60_par_conc.log
Processing ../12_12_60_60_par_conc.log ...
Call rate = 55 cps ...
Active call-setup duration = 32000 ms
Number of CPUs = 1
DEBUG timestr: bt=0.624769 et=103.713 to=103088.231
---- GC Analyzer Summary : ../12_12_60_60_par_conc.log ----
Application info:
Application run time = 103088.23 ms
Heap space = 60 MB
Eden space = 6144 KB
Semispace = 3072 KB
Tenured space = 49152 KB
Permanent space = 4096 KB
Young GC --------- (Copy GC + Promoted GC ) ---
Copy gc info:
Total # of copy gcs = 121
Avg. size copied = 1829854 bytes
Periodicity of copy gc = 783.529127272727 ms
Copy time = 68 ms
Percent of pause vs run time = 8%
Promoted gc info:
Total number# of promoted GCs = 245
Average size promoted = 258691 bytes
Periodicity of promoted GC = 349.22 ms
Promotion time = 71.55 ms
Percent of pause vs run time = 17.00 %
Young GC info:
Total number# of young GCs = 366
Average GC pause = 70.52 ms
Copy/Promotion time = 70.52 ms
Overhead(suspend,restart threads) time = 0.53 ms
Periodicity of GCs = 211.14 ms
Percent of pause vs run time = 25.04 %
Avg. size directly created old gen = 39.09 KB
Old concurrent GC info:
Heap size = 49152 KB
Avg. initial-mark threshold = 77.50 %
Avg. remark threshold = 78.47 %
Avg. Resize size = 275.74 KB
Total GC time (stop-the-world) = 1174.60 ms
Concurrent processing time = 28259.00 ms
Total number# of GCs = 180
Average pause = 6.53 ms
Periodicity of GC = 566.19 ms
Percent of pause vs run time = 1.14 %
Percent of concurrent processing vs run time = 27.41 %
Total (young and old) GC info:
Total count = 546
Total GC time = 26985.70 ms
Average pause = 49.42 ms
Percent of pause vs run time = 26.18 %
Call control info:
Call-setups per second (CPS) = 55
Call rate, 1 call every = 18 ms
Number# call-setups / young GC = 11.6126842513661
Total call throughput = 4250.24
Total size of short lived data / call-setup = 519497 bytes
Total size of long live data / call-setup = 22276 bytes
Average size of data / call = 541774
Total size of data created per young gen GC = 6291456 bytes
Execution efficiency of application:
GC Serial portion of application = 26.18%
Actual CPUs = 1
CPUs used for concurrent processing = 0.73
Application Speedup = 0.78
Application Execution efficiency = 0.78
Application CPU Utilization = 78.20 %
Concurrent GC CPU Utilization = 21.80 %
--- GC Analyzer End Summary ----------------
#--- Detailed and confusing calculations; dig into this if
you need more info about what is happening above ----
---- GC Log stats ...
---- Young generation calcs ...
Average young gen dead objects size / GC = 0.00 bytes
Average young gen live objects size / GC cycle = 0.00 bytes
Ratio of short lived / long lived for young GC = 23.32
Average young gen size promoted = 258691.66 bytes
Average number# of Objects promoted = 0
Total promoted times = 17529.89 ms
Average object promoted times = 0.00 ms
Total promoted GCs = 245
Periodicity of promoted GCs = 349.22 ms
Total copy times = 8281.21 ms
Total copy GCs = 121
Average copy GC time = 68.44 ms
Periodicity of copy GCs = 783.53 ms
Total number# of young GCs = 366
Total time of young GC = 25811.10 ms
Average young GC pause = 70.52 ms
Periodicity of young GCs = 211.14 ms
--- Old generation concgc calcs ....
Total concurrent old gen times = 1174.60 ms
Total number# of old gen GCs = 180
Average old gen pauses = 6.53 ms
Periodicity of old gen GC = 566.19 ms
--- Traditional MS calcs ...
Total number# mark sweep old GCs = 0
Total mark sweep old gen time = 0.00 ms
Average mark sweep pauses = 0.00 ms
Average free threshold = 0.00 %
Total mark sweep old gen application time = 0.00 ms
Average mark sweep apps time = 0.00 ms
--- Mark-Compact calcs ...
Total time taken by MC gc = 1174.60 ms
Total number# of old gen GCs = 180
Total number# of old gen pauses with 0 ms = 6
Periodicity of MC gc = 0.00 ms
---- GC as a whole ...
Total GC time = 26985.70 ms
Average GC pause = 49.42 ms
Total # of gcs = 546.00 ms
--- Heap calcs ...
Eden = 6291456 Bytes
Semispace = 3145728 Bytes
Old gen heap = 50331648 Bytes
Perm gen heap = 4194304 Bytes
Total heap = 59768832.00 Bytes
## for concgc
Live objects per old GC = 38570.32 KB
Dead objects per old GC = 275.74 KB
Ratio of (short/long) lived objects per old GC = 0.01
--- Memory leak verification ...
Total size of data promoted = 61894.00 KB
Total size of data directly created in
old generation = 14306.00 KB
Total size of data in old gen = 76200.00 KB
Total size of data collected throughout app. run = 49633.00 KB
--- Active duration calcs ...
Active duration of each call = 32000 ms
Number# number of calls in active duration = 1759
Number# of promotions in active duration = 91
Long lived objects(promoted objects) /
active duration = 23704790.78 bytes
Short lived objects (tenured or not promoted) /
active duration = 914316191.98 bytes
Total objects created / active duration = 938020982.77 bytes
Percent% long lived in active duration = 2.53 %
Percent% short lived in active duration = 97.47 %
Number# of active durations freed by old GC = 0.01
Ratio of live to freed data = 1.49
Average resized memory size = 275.74
Time when init GC might take place = 0.00 ms
Time when remark GC might take place = 0.00 ms
Periodicity of old GC = 566.19 ms
--- Application run times calcs ...
Total application run times during young GC = 77109.93 ms
Total application run times during old GC = 0.00 ms
Total application run time = 76601.70 ms
Calculated or specified app run time = 103088.23 ms
Ratio of young (gc_time/gc_app_time) = 0.33
Ratio of young (gc_time/app_run_time) = 0.25
Ratio of (old gc_time/total gc_app_time) = 0.00
Ratio of (old gc_time/app_run_time) = 0.01
Ratio of total (gc_time/gc_app_time) = 0.35
Ratio of total (gc_time/app_run_time) = 0.26
A3. GC Analyzer download
A4. GC Analyzer Patterns
The GC analyzer uses a table driven regular expression based state machine to parse the verbose:gc log file. About 9 patterns are supported at this time. Adding a new pattern is very easy. Add the pattern using an editor, and some new parsing code, and the new pattern could then be analyzed.
A4.1 Existing patterns
<smaller>
## pattern 2 in the log file
#250.932: [GC 250.932: [DefNew: 22070K->5645K(24576K), 0.2573941 secs] 227615K->213071K(253952K), 0.2576940 secs]
#252.645: [GC 252.646: [DefNew: 22029K->22029K(24576K), 0.0000613 secs]252.646: [Tenured: 207426K->49784K(229376K), 2.7216788 secs] 229455K->49784K(253952K), 2.7 221271 secs]
</smaller>
## data structure to recognize the pattern
@pattern2 = (
'\[GC .*: \[DefNew:.*\].*'
);
@pattern2_func = (
\&pattern2_defnew_func,
);
@pattern3 = (
'(.*: \[DefNew:.*\].* Heap after)'
);
<smaller>
## pattern 4 in the log file
##
0.112139: [GC {Heap before GC invocations=1:
Heap
def new generation total 1536K, used 1211K [0xf2c00000, 0xf2e00000, 0xf2e00000)
eden space 1024K, 96% used [0xf2c00000, 0xf2cf63d0, 0xf2d00000)
from space 512K, 44% used [0xf2d80000, 0xf2db8c10, 0xf2e00000)
to space 512K, 0% used [0xf2d00000, 0xf2d00000, 0xf2d80000)
tenured generation total 59392K, used 0K [0xf2e00000, 0xf6800000, 0xf6800000)
the space 59392K, 0% used [0xf2e00000, 0xf2e00000, 0xf2e00200, 0xf6800000)
compacting perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
the space 4096K, 28% used [0xf6800000, 0xf6921840, 0xf6921a00, 0xf6c00000)
0.112859: [DefNew
Desired survivor size 262144 bytes, new threshold 2 (max 31)
- age 1: 120048 bytes, 120048 total
- age 2: 152304 bytes, 272352 total
: 1211K->265K(1536K), 0.0093053 secs] 1211K->265K(60928K) Heap after GC invocations=2:
Heap
def new generation total 1536K, used 265K [0xf2c00000, 0xf2e00000, 0xf2e00000)
eden space 1024K, 0% used [0xf2c00000, 0xf2c00000, 0xf2d00000)
from space 512K, 51% used [0xf2d00000, 0xf2d427e0, 0xf2d80000)
to space 512K, 0% used [0xf2d80000, 0xf2d80000, 0xf2e00000)
tenured generation total 59392K, used 0K [0xf2e00000, 0xf6800000, 0xf6800000)
the space 59392K, 0% used [0xf2e00000, 0xf2e00000, 0xf2e00200, 0xf6800000)
compacting perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
the space 4096K, 28% used [0xf6800000, 0xf6921840, 0xf6921a00, 0xf6c00000)
} , 0.0105611 secs]
</smaller>
@pattern4 = (
'.*: \[GC \{Heap before GC invocations=\d+',
'eden space',
'tenured generation',
'(.*: \[DefNew:.*\].* Heap after)|(.*: \[DefNew)',
'eden space',
'from space',
'to\s+space',
'tenured generation',
'the space',
'the space',
'\} , \d+\.\d+ secs\]'
);
@defnew_pattern = (
'Desired survivor',
':\s+\d+K->\d+'
);
@pattern3_func = (
\&defnew1_func
);
@pattern4_func = (
\&gc_begin_func,
\&null_func,
\&tenure_gen_beforegc_func,
\&defnew_func,
\&eden_func,
\&from_func,
\&to_func,
\&tenure_gen_aftergc_func,
\&tenure_gen_func,
\&perm_gen_func,
\&gc_end_func
);
@defnew_pattern_func = (
\&defnew_begin_func,
\&defnew_data_func
);
## pattern 5 in the log file
##
0.568714: [GC {Heap before GC invocations=1:
Heap
par new generation total 9216K, used 6653K [0xec800000, 0xed400000, 0xed400000)
eden space 6144K, 99% used [0xec800000, 0xecdf8020, 0xece00000)
from space 3072K, 17% used [0xed100000, 0xed187740, 0xed400000)
to space 3072K, 0% used [0xece00000, 0xece00000, 0xed100000)
concurrent mark-sweep generation total 151552K, used 0K [0xed400000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 151552K, 0% used [0xed400000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000)
0.569664: [ParNew: 6653K->736K(9216K), 0.0240476 secs]
6653K->736K(160768K) Heap after GC invocations=2:
Heap
par new generation total 9216K, used 736K [0xec800000, 0xed400000, 0xed400000)
eden space 6144K, 0% used [0xec800000, 0xec800000, 0xece00000)
from space 3072K, 23% used [0xece00000, 0xeceb8070, 0xed100000)
to space 3072K, 0% used [0xed100000, 0xed100000, 0xed400000)
concurrent mark-sweep generation total 151552K, used 0K [0xed400000, 0xf6800000, 0xf6800000)
CompactibleFreeListSpace space 151552K, 0% used [0xed400000, 0xf6800000)
concurrent-mark-sweep perm gen total 4096K, used 1158K [0xf6800000, 0xf6c00000, 0xfa800000)
CompactibleFreeListSpace space 4096K, 28% used [0xf6800000, 0xf6c00000)
} , 0.0256695 secs]
## data structure to recongnize the pattern
@pattern5 = (
'(.*): \[GC \{Heap before GC invocations=(\d+)',
'eden space',
'concurrent mark-sweep generation',
'(.*: \[DefNew:.*\].* Heap after)|(.*: \[DefNew)|\[ParNew: |ParNew',
'eden space',
'from space',
'to\s+space',
'concurrent mark-sweep generation',
'concurrent-mark-sweep perm gen',
'\} , \d+\.\d+ secs\]'
);
@pattern5_func = (
\&gc_begin_func,
\&null_func,
\&cms_gen_beforegc_func,
\&defnew_func,
\&eden_func,
\&from_func,
\&to_func,
\&cms_gen_aftergc_func,
\&cms_perm_gen_func,
\&gc_end_func
);
## concurrent GC pattern in the log file
## data structure to recognize the pattern
13.1551: [GC [1 CMS-initial-mark: 12812K(40960K)] 15977K(59392K), 0.0005906 secs]
13.1558: [CMS-concurrent-mark-start]
13.3008: [CMS-concurrent-mark: 0.145/0.145 secs]
13.301: [CMS-concurrent-preclean-start]
13.3032: [CMS-concurrent-preclean: 0.002/0.002 secs]
13.3038: [GC13.3039: [dirty card accumulation, 0.0012606 secs]13.3052:
[dirty card rescan, 0.0001800 secs]13.3055: [remark from roots, 0.0012050 secs]13.3068:
[weak refs processing, 0.0000478 secs] [1 CMS-remark: 12812K(40960K)]
23418K(59392K), 0.0032351 secs]
13.3169: [CMS-concurrent-sweep-start]
13.3188: [CMS-concurrent-sweep: 0.002/0.002 secs]
13.3189: [CMS-concurrent-reset-start]
13.3511: [CMS-concurrent-reset: 0.032/0.032 secs]
## data structure to recognize the pattern
@pattern6 = (
'CMS-initial-mark:',
'CMS-concurrent-mark-start',
'CMS-concurrent-mark',
'CMS-concurrent-preclean-start',
'CMS-concurrent-preclean',
'dirty card accumulation',
'CMS-concurrent-sweep-start',
'CMS-concurrent-sweep',
'CMS-concurrent-reset-start',
'CMS-concurrent-reset:'
);
@pattern6_func = (
\&cms_init_mark_func,
\&cms_mark_start_func,
\&cms_mark_end_func,
\&cms_preclean_start_func,
\&cms_preclean_end_func,
\&cms_remark_func,
\&cms_sweep_start_func,
\&cms_sweep_end_func,
\&cms_reset_start_func,
\&cms_reset_end_func
);
## pattern 7 in the log file
#131.174: [GC 131.174: [ParNew: 24320K->0K(24448K), 0.0601556 secs]
359469K->337531K(1048448K), 0.0604045 secs]
## data structure to recongnize the pattern
@pattern7 = (
'\[GC .*: \[DefNew:.*\].*|\[ParNew:'
);
@pattern7_func = (
\&pattern7_defnew_func,
);
A4.2 State Machine To Change State To Detect Pattern
A4.2.1 Pattern 2 States
@pattern2_string_states=(0,-1);
$pattern2_err_state_table{"pattern"} = 2;
$pattern2_err_state_table{"err_depth"} = 0;
$pattern2_err_state_table{"pattern_state"} = 0;
$pattern2_err_state_table{"current_pattern_state"} = 0;
A4.2.2 Pattern 4 States
@pattern4_string_states=(0,1,2,3,4,5,6,7,8,9,10-1);
$pattern4_err_state_table{"pattern"} = 4;
$pattern4_err_state_table{"err_depth"} = 1;
$pattern4_err_state_table{"pattern_state"} = 0;
$pattern4_err_state_table{"current_pattern_state"} = 0;
A4.2.3 Pattern 5 States
@pattern5_string_states=(0,1,2,3,4,5,6,7,8,9,-1);
$pattern5_err_state_table{"pattern"} = 4;
$pattern5_err_state_table{"err_depth"} = 1;
$pattern5_err_state_table{"pattern_state"} = 0;
$pattern5_err_state_table{"current_pattern_state"} = 0;
A4.2.4 Pattern 6 States
@pattern6_string_states=(0,1,2,3,4,5,6,7,8,9,-1);
$pattern6_err_state_table{"pattern"} = 3;
$pattern6_err_state_table{"err_depth"} = 0;
$pattern6_err_state_table{"pattern_state"} = 0;
$pattern6_err_state_table{"current_pattern_state"} = 0;
A4.2.5 Pattern 7 States
@pattern7_string_states=(0,-1);
$pattern7_err_state_table{"pattern"} = 4;
$pattern7_err_state_table{"err_depth"} = 1;
$pattern7_err_state_table{"pattern_state"} = 0;
$pattern7_err_state_table{"current_pattern_state"} = 0;
A4.2.6 Pattern 3 States
@pattern3_string_states=(0,-1);
$pattern3_err_state_table{"pattern"} = 4;
$pattern3_err_state_table{"err_depth"} = 0;
$pattern3_err_state_table{"pattern_state"} = 0;
$pattern3_err_state_table{"current_pattern_state"} = 0;
A4.2.7 DefNew States
@defnew_string_states=(0,1,-1);
$defnew_err_state_table{"pattern"} = 2;
$defnew_err_state_table{"err_depth"} = 1;
$defnew_err_state_table{"pattern_state"} = 0;
$defnew_err_state_table{"current_pattern_state"} = 0;
$pattern5_err_transition_state{5} = 5;
$pattern5_err_state_table{5} = \@pattern6;
$pattern5_err_transition_state{5} = 5;
$pattern7_err_transition_state{5} = 7;
$pattern7_err_state_table{5} = \@pattern6;
$pattern7_err_transition_state{5} = 7;
$pattern2_err_transition_state{5} = 2;
$pattern2_err_state_table{5} = \@pattern2;
$pattern5_err_transition_state{5} = 2;
@pattern_states=(1,2,1);
A4.3 Pattern State Table
$pattern_table{1} = \@pattern4;
$pattern_table{2} = \@pattern5;
$pattern_table{3} = \@pattern3;
$pattern_table{4} = \@pattern6;
$pattern_table{5} = \@pattern2;
$pattern_table{6} = \@pattern7;
$pattern_string_state{1} = \@pattern4_string_states;
$pattern_string_state{2} = \@pattern5_string_states;
$pattern_string_state{3} = \@pattern3_string_states;
$pattern_string_state{4} = \@pattern6_string_states;
$pattern_string_state{5} = \@pattern2_string_states;
$pattern_string_state{6} = \@pattern7_string_states;
$pattern_string_state_func{1} = \@pattern4_func;
$pattern_string_state_func{2} = \@pattern5_func;
$pattern_string_state_func{3} = \@pattern3_func;
$pattern_string_state_func{4} = \@pattern6_func;
$pattern_string_state_func{5} = \@pattern2_func;
$pattern_string_state_func{6} = \@pattern7_func;
$pattern_err_state{1} = \%pattern4_err_state_table;
$pattern_err_state{2} = \%pattern5_err_state_table;
$pattern_err_state{3} = \%pattern3_err_state_table;
$pattern_err_state{4} = \%pattern6_err_state_table;
$pattern_err_state{5} = \%pattern2_err_state_table;
$pattern_err_state{6} = \%pattern7_err_state_table;
$defnew_pattern_table{1} = \@defnew_pattern;
$defnew_pattern_table{2} = \@pattern6;
$defnew_pattern_string_state{1} = \@defnew_string_states;
$defnew_pattern_string_state{2} = \@pattern6_string_states;
$defnew_pattern_string_state_func{1} =\@defnew_pattern_func;
$defnew_pattern_string_state_func{2} = \@pattern6_func;
$defnew_pattern_err_state{1} = \%defnew_err_state_table;
$defnew_pattern_err_state{2} = \%pattern6_err_state_table;
A4.4 Selecting A Pattern To Parse Manually
In sub parse_pattern() {
## No tenure GC
$tenure_gc = 0;
## No concurrent GC
# $cms_gc = 1;
$cms_gc = 1;
## total number of type of patterns in the log file
# $num_defnew_pattern = 1;
$num_defnew_pattern = 0;
$num_patterns=keys(%pattern_table);
$num_patterns = 1;
## select index 2 in pattern associative array ie. pattern 5
## $pattern_table{1} = \@pattern4;
## $pattern_table{2} = \@pattern5;
## This is the real time collector, parallel and concurrent GC ## pattern
combination
$pattern = 2;
# $pattern = 6;
$pattern_state = 0;
A5 J2SE 1.4.1 Garbage Collector Options
A5.1 Heap Layout
| Option | Default value | Max Value | Description |
|---|---|---|---|
-XX:NewSize |
2Mb | < 100 GB | Controls the initial size of young generation |
-XX:MaxNewSize |
< 100 GB | Controls the maximum size of the young generation | |
-XX:SurvivorRatio |
8 on windows, and 64 on Solaris | <100000 | Controls the size of the eden and the survivor spaces |
-Xms |
5 MB | < 100 GB | Initial heap size |
-Xmx |
4 MB | < 100 GB | Maximum heap size |
-Xmn |
Size of young generation | ||
-XX:MaxTenuringThreshold |
31 | Maximum number of times object is aged. Set this to 0 to enable promoteall. | |
-XX:PermSize |
4 MB | < 10 GB | Initial size of permanent generation |
-XX:MaxPermSize |
64 MB | < 10 GB | Maximum size of permanent generation |
-XX:NewRatio |
2 for server, 8 for client on Solaris | Ratio of young generation / old generation | |
-XX:PretenureSizeThreshold |
0 | Objects size greater than this is directly allocated in the older generation | |
-XX:+UseISM |
Use intimate shared memory (see section 16.2.6.1) | ||
-XX:+UseMPSS |
Use multiple page sizes (see section 16.2.6.1) | ||
-XX:+UseTLAB |
True on Solaris | Use thread-local object allocation | |
-XX:+AggressiveHeap |
Use for throughput applications with lots of CPUs and memory > 256MB. Turns on various flags, uses parallel scavenge collector for young generation, turns on Adaptive
SizePolicy , increase sizes of TLAB and other data structures
|
||
-XX:TargetSurvivorRatio |
50 | 100 | Desired percentage of survivor space used after a scavenge |
A5.2 Parallel Copying Collector
| Option | Default value | Max Value | Description |
|---|---|---|---|
-XX:+UseParNewGC |
Enables young generation parallel copying collector. Use with concurrent collector or default mark-sweep-compact collector | ||
-XX:ParallelGCThreads |
As many threads as CPUs | Controls the number of threads used for copying collection |
A5.3 Concurrent Collector
| Option | Default value | Max Value | Description |
|---|---|---|---|
-XX:+UseConcMarkSweepGC |
Enables old generation concurrent collection | ||
-XX:UseCMSCompactAtFullCollection |
false | Enable compaction Full GC and if full collection are occurring too frequently | |
-XX:CMSFullGCsBeforeCompaction |
1 | Parameter that affects compaction of the old generation. If at least this number of concurrent collections has not succeeded between full collection, do a compaction on full collections. If 0, always do compactions on full collections when UseCMS
Compact
AtFull
Collection is true
|
|
-XX:PrintCMSStatistics |
0 | If > 0, Print statistics about the concurrent collections. For example, the number of times the concurrent collection yield to a young generation collection and the number of cards precleaned | |
-XX:PrintFLSStatistics |
0 | If > 0, print statistics about the concurrent free lists. For example, a fragmentation parameter | |
-XX:PrintFLSCensus |
0 | if > 0, print the populations of the CMS free lists | |
-XX:CMSInitiatingOccupancyFraction |
68% | Change the percentage when a CMS collection is started |
A5.4 Parallel Scavenge Collector
| Option | Default value | Max Value | Description |
|---|---|---|---|
-XX:UseParallelGC |
Enables young generation parallel scavenge collector. Works only with the default mark-sweep-compact collector. Do not use with the concurrent collector. | ||
-XX:+UseAdaptiveSizePolicy |
false | Automatically sizes the young generation and chooses an optimum survivor ratio to maximize performance. | |
-XX:+PrintAdaptiveSizePolicy |
false | Prints information about adaptive size policy | |
-XX:ParallelGCThreads |
As many threads as CPUs | Controls the number of threads used for copying collection |
A5.5 Verbose GC options
| Option | Default value | Max Value | Description |
|---|---|---|---|
-XX:+PrintGCDetails |
false | PrintGC details | |
-XX:+PrintGCTimeStamps |
false | Adds timestamp info to GC details | |
-XX:+PrintHeapAtGC |
false | Prints detailed GC info including heap occupancy before and after GC | |
-XX:+PrintTenuringDistribution |
false | Prints object aging or tenuring information | |
-XX:+PrintHeapUsageOverTime |
false | Print heap usage and capacity with timestamps | |
-Xloggc:filename |
false | Prints GC info to a log file | |
-verbose:gc |
false | Prints some GC info | |
-XX:+PrintTLAB |
false | Print TLAB information |
Nagendra Nagarajayya, has been working with Sun for the last 8+ years. Currently, he works as a Staff Engineer at Market Development Engineering (MDE). At MDE, he works with Independent Software Vendors (ISVs) in the tele-communications (telco) & Retail industry, on issues related to architecture, performance tuning, sizing and scaling, benchmarking, porting, etc. He is interested, and specializes in multi-threaded issues, concurrency and parallelism, HA, distributed computing, networking, and performance tuning, in Java and Solaris.
Nagendra has a MS from San Jose State University, published many papers, and has been awarded several patents. He is also a member of the Dean's List, and Tau Beta Pi.
Steve Mayer is a five-year veteran at dynamicsoft, the leading provider of mobile services infrastructure software. As dynamicsoft's Director of Technology, Steve led the development team to bring to market the first commercial SIP User Agent. Steve has pushed the envelope of server side Java computing. By using optimization techniques that he has pioneered, dynamicsoft's products are not only the industry standard for performance but run in the most advanced telecommunications networks in the world. Currently, he has been involved in scalability and performance engineering, with a special emphasis on garbage collection.
Steve graduated with a B.S. in Computer Science from the Rochester Institute of Technology.
1Scavenging is nothing but copy-collection
2Degree of parellelism is used instead of degree of concurrency since the collection is stop the world
3"Active duration" is the length of time, a call setup state is maintained. Active duration segment is the number of call setups in one active duration i.e., 32 seconds in SIP