Part 4: Security and Performance Tuning of a REST and Ajax Application
Note: This article was written and tested using NetBeans IDE 6.8.
Introduction
This article is the last in a four-part series of articles and follows these previous articles:
In this article, we will look at advanced topics, such as security and performance. We will learn how to secure our application against XSS (cross-site scripting) attacks and how to improve the application's performance on both the server and the client sides.
This article uses the ArticleEvaluator sample application that was developed in the previous articles of this series. You can download the sample application for the first article using a link provided at the end of the first article. Similarly, you can download the sample application for the second and third articles using links provided at the end of those articles.
As with the three previous articles in this series, the sample application can be developed using NetBeans 6.8 or 6.9.
Security
A Naive Approach to Security: Securing the URLs and Objects
Usually, Java applications are secured at two levels: at the URL level and at the object level.
URLs are normally secured using standard Java Platform, Enterprise Edition (Java EE) security, which allows you to add constraints to URLs in the web.xml file. A similar and very popular approach is to use servlet filters. For instance, that's how Spring Security (a popular open source security framework) is typically used.
For our sample application, the JavaServer Faces part of the application is used for managing articles, authors, and votes, and hence, it should be secured. A very common solution to this security requirement is to add a rule stating that the faces/* URL can be used only by users who have the administrator role.
Objects can also be secured at the class level or at the method level. In this approach, annotations or aspect-oriented programming (AOP) are used to control who can execute what. This is typically done in the business layer of the application, so the presentation layer can execute only well-defined, secured business methods.
Let's test this approach by securing the create method of the Enterprise JavaBeans (EJB) fr.responcia.otn.articleevaluator.AuthorFacade object:
@RolesAllowed("Administrator")
public void create(Author author) {
em.persist(author);
}
If you now try to create a new author by using the JavaServer Faces application, you get a security error:
INFO: JACC Policy Provider: Failed Permission Check, context(ArticleEvaluator/ArticleEvaluator_internal)-
permission((javax.security.jacc.EJBMethodPermission AuthorFacade create,Local,fr.responcia.otn.articleevaluator.Author))
ATTENTION: A system exception occurred during an invocation on EJB AuthorFacade method public void
fr.responcia.otn.articleevaluator.AuthorFacade.create(fr.responcia.otn.articleevaluator.Author)
javax.ejb.AccessLocalException: Client not authorized for this invocation.
at com.sun.ejb.containers.BaseContainer.preInvoke(BaseContainer.java:1801)
at com.sun.ejb.containers.EJBLocalObjectInvocationHandler.invoke(EJBLocalObjectInvocationHandler.java:188)
at com.sun.ejb.containers.EJBLocalObjectInvocationHandlerDelegate.invoke(EJBLocalObjectInvocationHandlerDelegate.java:84)
at $Proxy233.create(Unknown Source)
at fr.responcia.otn.articleevaluator.__EJB31_Generated__AuthorFacade__Intf____Bean__.create(Unknown Source)
at fr.responcia.otn.articleevaluator.AuthorController.create(AuthorController.java:82)
As we can see, the @RolesAllowed annotation protected the method from being called by a user who does not have the required authorization.
Now that we have tested this security measure, you can remove the annotation from your code.
Securing an application at the URL level and at the object level is very important. Doing this makes it very difficult for an attacker to access or compromise secured data. In our example, it would be impossible for an attacker to add a new author if both security methods are applied.
However, we are going to discover that this is not enough to prevent our application from getting hacked.
Hacking the Sample Application
Let's use a near real-world case. As an author, I would like all readers to vote for my article with five stars.
As an author, I have limited access to the application back end. I can update personal information, such as my name, first name, Web site, and so on. This information is probably secured using the traditional security methods we saw in the previous section.
Let's start by doing a simple test: using the JavaServer Faces application to edit the #1 author.
Note: If you just deployed this application for the first time (that is, you did not follow the first article), your database will be empty. In this case, you need to use the JavaServer Faces application (deployed at http://localhost:8080/ArticleEvaluator ) to create a new author (you do not need to provide its ID; by default the ID will be “1”). You also need a new article, which you need to link to that author.
Now, if you go to the REST application (http://localhost:8080/ArticleEvaluator/article.html ), you should be able to see this author's information updated at the bottom of the page:
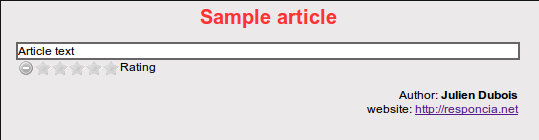
Let's do a first simple hack by going back to the JavaServer Faces front end to change the author's first name, as follows:
Julien <script type="text/javascript">alert("You have been hacked. Read this Security and Performance
Tuning of a REST and Ajax Application article for details.");
If we go back to the REST front end, we have a surprise:
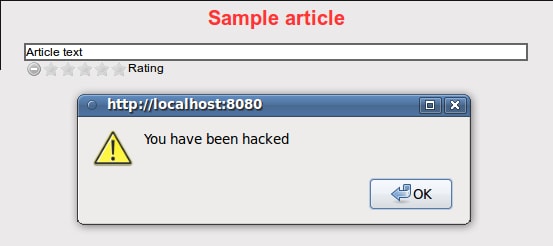
What's happening? Because the NetBeans-generated JavaServer Faces front end does not know we can insert HTML in the “first name” field, it does not check the content of the text String that we input. As a result, a normal user who looks at an article from the REST front end can execute JavaScript code that was maliciously inserted by an author. Of course, the author could insert something much more interesting than just an alert box, such as giving himself a 5-star vote and then hiding the voting panel!
Such attacks are relatively elaborate but happen more and more often on public Web sites. eBay and MySpace have suffered such XSS attacks, which have been widely publicized. How can you prevent them?
The easiest answer is to prevent the insertion of HTML and JavaScript by a user. That's why wikis have their own syntax. In fact, many Web sites just “escape” all HTML characters entered by a user. A very popular solution for this is the org.apache.commons.lang.StringEscapeUtils class from Apache Commons.
Of course, this solution is not enough for more complex Web sites. That's why there are various solutions for cleaning up the HTML code provided by users. Some of them involve the use of black lists (that's what MySpace does) or some intelligent parsing. The AntiSamy project provides an open source implementation of such a solution, which allows you to configure what users can or cannot input, with an advanced validation system.
Performance
Why Client-Side Performance Matters
Tools such as Yahoo! YSlow have shown that, contrary to popular belief among developers, the client side of an application is where most performance problems occur. Downloading and rendering a complex HTML or JavaScript page can take a lot of time, especially if the user is accessing it with an older browser or with a low-performance computer, such as a netbook.
As a result, if you want a smooth user experience, you should focus as much on your client-side code as on optimizing your Java and SQL code.
How to Serve Static Data
Ajax applications usually make heavy use of JavaScript, images, and CSS files. That's exactly what happens with our sample application, which uses JQuery.
There are a few rules that can make dramatic improvements for such applications:
- All static data should be served separately. Static data should be hosted on a cookie-free domain (cookies are sent with each request) by a specific Web server or a Content Delivery Network (CDN).
- Static data should be compressed. Some files can be compressed using gzip (modern browsers all support gzipped data), but you can also run some specific compressors for JavaScript.
- The number of served files should be minimal, because each one requires a separate HTTP connection. While this is easy to do for some type of files (JavaScript files just need to be concatenated), it is a bit more difficult for images. The best technique to use for images is called CSS (sprites), which uses CSS to display parts of a larger image containing many small images.
- “expires”, “last-modified” and “ETag” headers should be configured on the HTTP requests serving those files. Doing this allows the user's browser to store all those files in its cache instead of downloading them at each visit. This dramatically cuts the number of downloaded files, but may cause an important issue: What happens when you want to change one of those files? How can you force the user's browser to download it again? The trick is to use a version number in the URL of all static content and then increment this number at each release.
Improving Client-Side Performance by Using gzip and HTTP Headers
Some of the techniques used for serving static content also can be used for dynamic content.
The most obvious solution is to use gzip to compress all dynamic content. If your Web pages are big enough, this method can lead to a large improvement on the client side, because the pages will be downloaded faster. Of course, this comes at a cost on both sides, due to the need to compress and uncompress the content. On the server side, this compression and decompression can be processed by the Web server (see Apache's mod_deflate module), by the application server, or simply by a servlet filter.
Another, more-advanced technique is to use HTTP headers in the same way as we did for the static content. In fact, because a REST application uses standard URLs, some of its content can automatically be cached by proxies, front-end Web servers, or client browsers. Of course, this is valid only for information that is not changing very often. This is a perfectly valid approach for Wikipedia, but not for Twitter.
Let's look again at our REST service that serves author information. This information is probably not changing very often, and doesn't need to be updated in real time, so we could give it some specific HTTP headers in order to cache it.
Open the AuthorResource class (under the fr.responcia.otn.articleevaluator.rest.resource package or under the package structure you provided when you created the project in the first article of this series), and change the get method:
@GET
@Produces({"application/xml", "application/json"})
public Response get(@QueryParam("expandLevel")
@DefaultValue("1")
int expandLevel) {
AuthorConverter converter = new AuthorConverter(getEntity(),
uriInfo.getAbsolutePath(), expandLevel);
Calendar expiresDate = Calendar.getInstance();
expiresDate.add(Calendar.DATE, 1);
Response.ResponseBuilder response = Response.ok(converter).expires(expiresDate.getTime());
return response.build();
}
Here, we are using some more-advanced methods from the JSR 311 API (RESTful Web Services), in order to configure our resource to expire tomorrow. This is a very simple way to ask the client browser to cache the author information for one day.
You can test this behavior in the following way:
- With the REST front end, look at an article and note the author's name.
- With the JavaServer Faces front end, change that author's name.
If you go back to the REST front end, the author's name will not have changed. However, if you force the page to reload, or if you clean up the browser's cache, the author's name will change.
A more-advanced system would be to use the last-modified or ETag headers. That approach is more complex to implement, because you need to know when a resource has changed. For a simple resource, it means you need to store a date field and update that field for each update. For something more complex, such as a graph of objects, you need to know when the last of those objects was changed, which quickly becomes very difficult to achieve.
As a result, people often use a servlet filter that calculates a Message-Digest algorithm 5 (MD5) hash of each response, and then use that hash as a key for ETags. If you want a good example of such a filter, look at the org.springframework.web.filter.ShallowEtagHeaderFilter class from the Spring Framework. Of course, you still need to compute your whole page before being able to calculate the MD5 hash. You consume more CPU power than before (because you still need to generate the page, and you also need to calculate the MD5 hash), but you gain in bandwidth, which means your page loads faster in the client browsers.
Caching Content to Reduce the Server-Side Load
Server-side, our REST application is not different from any classic Java EE application. We should use caching appropriately to increase performance. Because we are using standard EJB objects, we can use the new Java Persistence API (JPA) 2.0 @Cacheable annotation.
Open the fr.responcia.otn.articleevaluator.Author class, and add this annotation at the top of the class:
import javax.persistence.Cacheable;
@Entity
@Cacheable
public class Author implements Serializable {
Adding the annotation automatically caches the EJB object. A simple way to test this behavior is to run an SQL query directly against the database, which bypasses the cache:
update AUTHOR set LASTNAME = "test";
If you reload your Web page, the author's name should not have changed, proving that the cache is working correctly.
Using this approach prevents the database from being hit each time an author is requested, which is the #1 performance problem that is encountered in Java applications.
Conclusion
In the four articles of this series, we learned how to build a Jersey-based RESTful application and how to efficiently access it with the JQuery framework. Because both frameworks rely on open and standard architectures, we saw that it was easy to make them work together, even for advanced tasks such as HTTP caching.
We also saw that such an application can provide an advanced user interface, thanks to JQuery, and it can scale very easily, thanks to the REST architecture. We also studied how such applications scan be secured, even against modern XSS attacks.
The completed sample application can be downloaded here:
See Also
- JQuery Web site: http://jquery.com/
About the Author
Julien Dubois has been a Java developer and architect for more than 10 years. He is the co-author of a top-selling French book on the Spring Framework, and he worked for SpringSource before the company was bought by VMware. He now leads his own consulting company, Responcia, which provides http://responcia.net, a French knowledge management solution.