Using the Java Persistence API in Desktop Applications
By John O'Conner June 2007
The JSR 220 specification defines Enterprise JavaBeans 3.0. One of its primary goals is to simplify the creation, management, and storage of entity beans. Working towards that goal, Sun Microsystems and supporting community developers created a new application programming interface (API) that lets you use " plain old Java objects" or POJOs as your persistable entities. The Java Persistence API facilitates your use of POJOs as entity beans and significantly reduces the need for complicated deployment descriptors and extra helper beans. Additionally, you can even use the API in desktop applications.
You'll discover many reasons of your own to use the new persistence API, but here are just a few:
- You won't have to create complex data access objects (DAO).
- The API helps you manage transactions.
- You write standards-based code that interacts with any relational database, freeing you from vendor-specific code.
- You can avoid SQL in preference to a query language that uses your class names and properties.
- You can use and manage POJOs.
- You can also use the Java Persistence API for desktop application persistence.
This article describes the Java Persistence API and how to use it in Java SE desktop applications that require object persistence. You will learn the following:
- How to define persistable entities in your application
- Important packages and classes of the API
- How to use the API in a sample application
- How to use the Java Persistence query language
- How to get a reference implementation and documentation
- How to configure your NetBeans integrated development environment (IDE) to use the API
Entities and Their Relationships
Whether your application sits on the desktop or on an application server like GlassFish, the Java Persistence API requires that you identify the classes that you will store in a database. The API uses the term entity to define classes that it will map to a relational database. You identify persistable entities and define their relationships using annotations. The Java compiler recognizes and uses annotations to save you work. Using annotations, the compiler can generate additional classes for you and perform compile time error checking.
Entity Declarations
Perhaps the most important annotation is javax.persistence.Entity. This annotation identifies persistable classes and is required for all class definitions that you intend to use with the persistence API. Entity classes become tables in a relational database. Entity instances map into rows in one or more tables.
The following code sample begins the definition of a baseball Player class. Annotations in your code begin with the @ symbol.
@Entity
public class Player {
...
Notice that the Entity annotation comes immediately before the class definition. The Java Persistence API implementation will create a table for the Player entity in your relational database. By default, the table name corresponds to the unqualified class name. In this case, a PLAYER table will represent Player entities.
The restrictions on entities are few but important. First, entities must be top-level classes. You cannot create entities from enumerations or interfaces. Additionally, your class must be non-final, with no final methods or final persistent instance variables.
Other than these few limitations, entities can use most of the other Java language features for classes. For example, entities can be abstract or concrete classes. However, abstract entities must also be subclassed by another entity class for database storage. Classes can be hierarchical, extending or extended by other entity or non-entity classes.
Fields and Properties
An entity's state is defined by the value of its fields or properties. You get to decide whether the Java Persistence API uses your variable fields or your property getters and setters when retrieving and saving entities. If you annotate the instance variables themselves, the persistence provider will directly access the instance variables. If you annotate your JavaBean-style getter and setter methods, the persistence provider will use those accessors for loading and storing persistent state. You should choose one style or the other; mixing the two is illegal in the current specification. The current persistence specification shows examples that have annotated property accessors, so this article will follow that convention.
You can use most basic types for persistent fields, including primitive types, wrappers for those primitive types, Strings, and many others. You should consult the API specification for details on the allowed field types.
All entities must have a primary key. Keys can be a single unique field or a combination of fields. This article uses single field keys, but you can create keys from multiple fields if necessary. Identify single field keys with the Id annotation.
Key fields must have one of the following types:
- primitive type (like
int,long, etc) - wrappers for primitive types (
Integer,Long, etc) java.lang.Stringjava.util.Datejava.sql.Date
The next code sample defines a Player class. This example shows how you can use four different annotations: Entity, Id, GeneratedValue, and Transient.
@Entity
public class Player implements Serializable {
private Long id;
private String lastName;
private String firstName;
private int jerseyNumber;
private String lastSpokenWords;
/** Creates a new instance of Player */
public Player() {
}
/**
* Gets the id of this Player. The persistence provider should
* autogenerate a unique id for new player objects.
* @return the id
*/
@Id
@GeneratedValue
public Long getId() {
return this.id;
}
/**
* Sets the id of this Player to the specified value.
* @param id the new id
*/
public void setId(Long id) {
this.id = id;
}
public String getLastName() {
return lastName;
}
public void setLastName(String name) {
lastName = name;
}
// ...
// some code excluded for brevity
// ...
/**
* Returns the last words spoken by this player.
* We don't want to persist that!
*/
@Transient
public String getLastSpokenWords() {
return lastSpokenWords;
}
public void setLastSpokenWords(String lastWords) {
lastSpokenWords = lastWords;
}
// ...
// some code excluded for brevity
// ...
}
The entity's primary key is the id property and is correctly marked with the Id annotation. Primary keys can be auto-generated values. Behavior for auto-generated ids is not completely specified, but the reference implementation will generate a key automatically if you add the GeneratedValue annotation to the primary key:
@Id
@GeneratedValue
public Long getId() {
...
Always explicitly mark properties or fields that should not be persisted. Use the annotation Transient for marking transient properties. You can also use the language keyword transient for fields. Properties and fields marked with the Transient annotation will not be permanently stored in your database. In the previous Player code sample, notice that the lastSpokenWords property uses the Transient annotation. Fields marked with the transient Java language keyword will not be serialized or persisted. Fields or properties marked with the Transient annotation will not be persisted to the database.
Entity Relationships
Like real world entities, your persistent objects won't usually work alone. Entity classes typically interact with other classes, either using or providing services. Classes can have one to one, one to many, many to one, and many to many relationships with other classes. You can find each of these relationships in the baseball player and team examples shown in this article.
For example, a Player has a batting average. The batting average and the player have a one to one relationship. One player has one average. That one instance of the average belongs to just one player.
Teams have players. Although individual players belong to only one team, a team consists of multiple players. The relationship between Team and Player classes is one to many. One team has many players. Another similar relationship type is the many to one relationship. The many to one relationship is often the reverse perspective of a one to many relationship. You could, for example, just as easily say that Player and Team classes have a many to one relationship if you consider the relationship from a player's perspective.
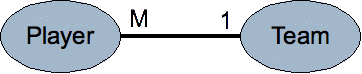
Figure 1. Many players associate with a single team.
A team will play in many games each season, and each game has many -- just two actually -- participating teams. For relational database purposes, the team to game relationship is many to many.
You can model these entity relationships within the persistence API. Anytime your entity objects have these relationships, you should apply one of these annotations to the related entity property:
OneToOneOneToManyManyToOneManyToMany
Database relationships can be one-sided, meaning that only one entity knows about the other entity or entities in the relationship. Unidirectional relationships have an "owning" side, the side that maintains the relationship in the database.
Bidirectional relationships have both an owning and an "inverse" side. The owning side determines how and when updates affect the relationship. Also, the owning side usually contains the foreign key to the other entity.
Returning to the baseball example, Player objects have a ManyToOne relationship with a Team object. Although it may not be literally true in the real world, in the database, the Player will own the relationship. Declare this many to one relationship between Player and Team entities by adding the ManyToOne annotation to the team property of the Player class:
@Entity
public class Player implements Serializable {
...
private Team team;
@ManyToOne
public Team getTeam() {
return team;
}
...
}
Since the Team and Player classes have a bidirectional relationship, you now must define the inverse side of the relationship and relate it to the owning side. From the Team class perspective, the relationship is OneToMany. Additionally, a Player instance will refer to the Team instance through its team variable. Use the attribute mappedBy with the OneToMany annotation so that the persistence engine knows how to match players and teams. The mappedBy attribute exists in the inverse side of the bidirectional relationship, which is the Team. In this example, the mappedBy attribute shows that a Player instance's team property maps to the Team instance. Being mapped by a Player object's team property means that the Team object's identifier will exist as a foreign key column in the PLAYER table. The owning Player side of the relationship is responsible for storing the foreign key.
The Team class is immediately below. Notice the getPlayers method, which has the inverse OneToMany annotation with the mappedBy attribute.
@Entity
public class Team implements Serializable {
private Long id;
private String teamName;
private String division;
private Collection<Player> players;
/** Creates a new instance of Team */
public Team() {
players = new HashSet();
}
/**
* Gets the id of this Team.
* @return the id
*/
@Id
@GeneratedValue
public Long getId() {
return this.id;
}
/**
* Sets the id of this Team to the specified value.
* @param id the new id
*/
public void setId(Long id) {
this.id = id;
}
@OneToMany(mappedBy = "team")
public Collection<Player> getPlayers() {
return players;
}
public void setPlayers(Collection<Player> players) {
this.players = players;
}
...
}
Table and Column Name Defaults
The Java Persistence API specification provides useful defaults for many of the annotation attributes. You may want to read the specification for the details, but several examples are provided here.
Every entity has a name. By default, the entity name is the entity's unqualified class name. The Entity annotation has a name attribute that allows you to explicitly specify a name. You will use the entity name in queries. In the Player example, you will use the name Player in your queries. If you want to use the name BaseballPlayer as the entity name, use the name attribute to specify that fact:
@Entity (name="BaseballPlayer")
public class Player {
...
BASEBALLPLAYER is now also the table name for this entity, but you can change that with the Table annotation. Table has three optional elements, and one determines the entity's table name. Change the table name to BASEBALL_PLAYER with the name attribute of the Table annotation like this:
@Entity
@Table(name="BASEBALL_PLAYER")
public class Player {
...
By default, persistence provider implementations use an entity's field or property names as the column names in the entity table. For example, since the Player class name has a lastName property, the corresponding column is LASTNAME. The defaults are nothing surprising since they are practically identical to the names you use in the application code itself. You can, however, override the default using the Column annotation and its name element. If you prefer SURNAME instead of LASTNAME, you can annotate the lastName property like this:
@Column(name="SURNAME")
public String getLastName() {
...
Many other annotations and optional elements exist. They help you control column length or size, uniqueness requirements, cascade operations, and other standard options associated with relational databases. This article provides information and examples for only a few of the most common combinations that will help you get started with this API.
Persistence Units
The set of entities in your application is called a persistence unit. You must define your application's persistence unit in a configuration file called persistence.xml. This file should exist alongside your application in a META-INF directory. You can put the META-INF subdirectory within your project's source directory. In this article's Persistence project, which you can download, you will find a directory structure similar to that shown in Figure 2.

Figure 2. The persistence.xml file lets the persistence API implementation know about entities.
The persistence.xml file has many functions, but its most important task in the desktop environment is to list all the entities in your application and to name the persistence unit. Listing entity classes is required for portability in Java SE environments. The simplest persistence.xml file for this article's entities might look like this:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://www.oracle.com/webfolder/technetwork/jsc/xml/ns/persistence/index.html"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.oracle.com/webfolder/technetwork/jsc/xml/ns/persistence/index.html
http://bit.ly/cDXfCA">
<persistence-unit name="league" transaction-type="RESOURCE_LOCAL">
<provider>oracle.toplink.essentials.ejb.cmp3.EntityManagerFactoryProvider</provider>
<class>com.sun.demo.jpa.Player</class>
<class>com.sun.demo.jpa.Team</class>
<properties>
<property name="toplink.jdbc.user" value="league"/>
<property name="toplink.jdbc.password" value="league"/>
<property name="toplink.jdbc.url" value="jdbc:derby://localhost:1527/league"/>
<property name="toplink.jdbc.driver" value="org.apache.derby.jdbc.ClientDriver"/>
<property name="toplink.ddl-generation" value="create-tables"/>
</properties>
</persistence-unit>
</persistence>
The majority of this file is template, and tools like the NetBeans IDE 5.5 can create the outline correctly for you. The important elements for this article are the following:
persistence-unitproviderclassproperty
The persistence-unit's name attribute can be anything you choose. This name isn't necessarily your database or schema name, but keeping consistency may be helpful. In this example, the persistence unit (PU) is league. When using the API from Java SE applications, the default transaction type is RESOURCE-LOCAL. In Java EE environments, you will also see the JTA transaction type, which means that the entity manager participates in the transaction. If you don't specify the type, the default setting is used, which makes it easier to move your application from one environment to another.
The provider element declares the class file that provides the initial factory for creating an EntityManager instance. Your persistence API implementor should provide details about correct values for this element. The persistence.xml example shows the provider class name used in the GlassFish reference implementation.
Use the class element to list the entity class names in your application. In this article's example code, only two entities are needed: com.sun.demo.jpa.Player and com.sun.demo.jpa.Team. The full package and class names are necessary. The persistence provider knows which application classes to map to the relational database by reading the entity names from the persistence.xml file.
Finally, in Java SE desktop environments you should put database connection properties in the persistence.xml file if Java Naming and Directory Interface (JNDI) lookups aren't possible. Database connection properties include the username and password for the database connection, the database connection string, and driver classname. Additionally, you can even include persistence provider properties like options to create or drop-create new tables. The property namespace javax.persistence is reserved for properties defined by the specification. Vendor-specific options and properties must use their own namespace to avoid conflicts with the specification. The previously shown persistence.xml file uses the GlassFish reference implementation. Its vendor-specific properties are in the toplink namespace and are not part of the specification itself. Persistence providers will ignore any properties that are not in the specification itself or that are not part of their own vendor-specific properties.
API Overview
The Java Persistence API is part of the Java EE 5 specification. You'll find everything you need to work with entities in the javax.persistence package. One of the first things you need is an EntityManager instance. An EntityManager provides methods to begin and end transactions, to persist and find entities in the persistence context, and to merge or even remove those entities. Additionally, an EntityManager instance can create and execute queries.
A persistence context is a grouping of unique entity instances that are managed by the persistence provider at runtime. A similar term is persistence unit, which is the set of all entity classes that an application might use. A persistence unit defines a group of entities mapped to a single database.
Entities have lifecycle states in the API specification. Knowing about their lifecycle state will help you understand the effects of the API operations on those entities. The various states are listed here:
- New -- New entities are new objects in your application. A new entity may exist in your application, but the persistence context is not yet aware of the entity.
- Managed -- Managed entities are entities that you have persisted or that already exist in the database. These entities have an identity in the persistence context.
- Detached -- Detached entities have a persistent identity, but they are not currently actively managed within a persistence context.
- Removed -- Removed entities exist in a persistence context, but are scheduled to be removed or deleted from that context.
The next few sections will describe some of the operations you can use on entities and will give you an idea about how entities move through the various lifecycle states.
New Entity Creation
Since entities are POJOs, you create them just like you would any other object. You can use the new keyword to create new instances of your class. You create new Player entities by using the new keyword that invokes the Player constructor:
Player p = new Player();
At this point, you can set the player's name, number, and related information programmatically. Also, you can set the properties with a suitable constructor. This is especially useful and convenient when you use field-based persistence annotations instead of property-based annotations. New entities are not yet managed by any persistence context.
Entity Manager
To persist a new entity, you need an EntityManager instance. Getting an EntityManager instance is easy but circuitous in desktop environments. You'll need an EntityManagerFactory instance to create an EntityManager object. You'll need to use the Persistence class to get the factory. The Persistence class is the bootstrap class used in Java SE environments.
The following code demonstrates how to create an EntityManager instance in a Java SE desktop environment. Since EntityManager instances represent a persistence unit, you must provide the persistence unit name. In this example, league is the persistence unit name. Again, a persistence unit simply defines a set of entities that are typically associated with a single application and that are stored in a single database. The name league is declared in the persistence.xml file along with other properties.
// Create the EntityManager
EntityManagerFactory factory = Persistence.createEntityManagerFactory("league");
EntityManager em = factory.createEntityManager();
Managed Entities
Now that you have an EntityManager object, you can use it to create queries and transactions in a desktop environment. Before storing new Player and Team entities, you should begin a transaction. During the transaction, use the entity manager's persist method to manage a new entity. New entities move to the managed state when you persist them. You must commit the transaction for changes to occur in the database. Not surprisingly, you will use the begin and commit methods for these operations.
The following code demonstrates how you can create and save several Players and their Team assignments -- at least how they are assigned so far in the Major League Baseball 2007 season.
public class CreatePlayersAndTeams {
/** Creates a new instance of CreatePlayersAndTeams */
public CreatePlayersAndTeams() {
}
/**
* @param args the command line arguments
*/
public static void main(String[] args) {
// Create the EntityManager
EntityManagerFactory emf = Persistence.createEntityManagerFactory("league");
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
for(Team team: teams) {
em.persist(team);
}
for(Player player: players) {
player.setTeam(teams[0]);
teams[0].addPlayer(player);
em.persist(player);
}
em.getTransaction().commit();
em.close();
emf.close();
}
private static Player[] players = new Player[] {
// name, number, last quoted statement
new Player("Lowe", "Derek", 23, "The sinker's been good to me."),
new Player("Kent", "Jeff", 12, "I wish I could run faster."),
new Player("Garciaparra", "Nomar", 5,
"No, I'm not superstitious at all.")
};
public static Team[] teams = new Team[] {
new Team("Los Angeles Dodgers", "National"),
new Team("San Francisco Giants", "National"),
new Team("Anaheim Angels", "American"),
new Team("Boston Red Sox", "American")
};
}
This code creates players and their teams and makes those team assignments. Once you've created the new entities, you call the entity manager's persist method. Finally, once you've created the objects and called the persist method, you complete the transaction by calling the commit method. When you are finished with the database, typically after all transactions, use the close method on both the entity manager and its factory.
Figure 3 shows the TEAM table. Since the Team entity has auto-generated identifiers, the sequence ids 1 through 4 are the primary key values for the first 4 rows of this table.

Figure 3. The Team entity becomes the TEAM table by default.
Figure 4 shows the PLAYER table. The auto-generated identifiers continue where they left off from the TEAM table. Notice that each player row contains a foreign key value to its related Team entity. In this case, each player is on the Dodgers team, which has the primary key value 1 in this example.

Figure 4. Player rows have a foreign key (TEAM_ID) to their assigned team.
The GlassFish reference implementation can actually create the PLAYER and TEAM tables for you. Once you've created the league database using your database tools, the previous code sample creates the necessary entity tables if they don't already exist. This behavior is optional, of course, and it is determined in this case by the persistence.xml file's vendor-specific property toplink.ddl-generation, which has the create-tables value in the downloadable sample code. Of course, if the tables already exist, the code inserts the records into the existing tables and generates lots of warning messages telling you about the existing tables. Using the toplink.ddl-generation property to automatically create tables, columns, and keys is productive for quick development cycles when you make changes, test, drop tables, change the code, and test repeatedly.
Creating large database schemas by simply committing the newly persisted entities may not be standard practice. You might prefer to generate tables and other schema database elements using SQL or your database vendor's own tools. The persistence specification carefully describes the rules that provider implementations must use when mapping object entities to their relational representations. The specification defines how entities, properties, and identifiers will be established in the database as tables, columns, primary keys, and foreign keys. You must keep those naming conventions in mind when you create database tables that will be used with the Java Persistence API. Alternatively, you can use annotations to override the defaults.
Entity Find Method
The database now has several players and their team assignments. You can use the persistence API to retrieve those same entities from the database without any complex queries. Of course, you must know the entity's primary key. Call the find method to retrieve entities. In the examples so far, you have created only a few entity instances, and the persistence provider has inserted those entities with generated sequence identifiers starting with the number 1. The following code will simply iterate through a few possible identifiers, call the find method with that id, and will then print the results when a Player exists with that id.
// The EntityManager, em, has already been created at this point.
...
// Retrieve Player entities using their keys.
for(long primaryKey = 1; primaryKey < 10; primaryKey++) {
Player player = em.find(Player.class, primaryKey);
if (player != null) {
System.out.println(player.toString());
}
}
Assuming you have created the db and tables correctly from the sample code provided with this article, the following player data will be displayed on your console:
[Jersey Number: 23, Name: Derek Lowe, Team: Los Angeles Dodgers]
[Jersey Number: 12, Name: Jeff Kent, Team: Los Angeles Dodgers]
[Jersey Number: 5, Name: Nomar Garciaparra, Team: Los Angeles Dodgers]
Entity Merge Method
Detached entities have a persistent identity in the database, but are not in the current persistence context. That situation will exist if you have created a Player from a previously serialized file or if you have either cleared or closed the entity manager. You can update the entity and merge it back into the persistence context with the merge method.
The following code demonstrates how to change the Team assignment of a detached entity. The Player instance is detached from the persistence context once you call the entity manager's clear method. Also, entities become detached when you close the entity manager. The entity is still in the database, yet the entity manager no longer actively manages it.
// The EntityManager, em, already exists for this example.
...
// We just happen to know that '5' is one of the
// player identifiers. You shouldn't normally hard-code this
// into any application.
Player p = em.find(Player.class, 5L);
em.clear();
// p is now detached for the convenience of this example
Team t = new Team("Ventura Surfers", "National");
p.setTeam(t);
em.getTransaction().begin();
Player managedPlayer = em.merge(p);
em.getTransaction().commit();
...
The merge command places the detached object back into the managed state. Additionally, the command returns a managed copy of the entity.
Entity Remove Method
Remove an entity with the remove method. The remove method requires that you provide an actively managed entity as a parameter of the call. Removing an entity requires that the action be part of a transaction as shown here:
// 'em' is an EntityManager instance
em.getTransaction().begin();
// use a hard-coded player id for convenience in this sample only
Player player = em.find(Player.class, 5L);
if (player != null) {
System.out.println(player.toString());
em.remove(player);
}
em.getTransaction().commit();
Other Methods and Options
An EntityManager instance provides numerous other methods to help you interact with entities and the persistent storage. The APIs include methods for closing and clearing the entity manager, flushing entities to their underlying storage, refreshing the in-memory entity with its persistent data, locking entities, cascading operations, and more.
You should definitely investigate the createQuery method and the related methods that create Query objects. A Query object represents a query in the Java Persistence query language, which is described in the following section.
Querying the Persistence Storage
The Java Persistence query language (JPQL) is an extension of the Enterprise JavaBeans query language (EJB QL). This query language allows you to perform both dynamic and static queries on the entities in your application. The language is like SQL in many ways. However, it does have benefits over SQL. The Java Persistence query language operates over the entities and their relationships rather than over the actual relational database schema. This makes queries portable regardless of the underlying database.
Queries come in three different flavors: select, update, and delete. A select query returns a set of entities from your database. The set usually has specific constraints that limit the result set. An update query changes one or more properties of an existing entity or set of entities. Finally, a delete statement removes one or more entities from the database.
You have several options to create a query. The most basic way is to simply ask the entity manager for one. The following query examples use queries obtained by the createQuery method of an entity manager:
Query query = em.createQuery(queryStatement);
When you use the Query object, you can create, read, update, or delete entities using a more expressive query language. Although the find, remove, persist, and merge methods work well, queries give you much more flexible options.
Entity Selection
The select query applies your specific criteria when it retrieves entities. The following query language statement selects all players on the Dodgers team:
select c from Player c where c.team.teamName = 'Los Angeles Dodgers'
Construct a Query instance and execute it like this:
Query q = em.createQuery("select c from Player c where c.team.teamName = 'Los Angeles Dodgers'");
List<Player> playerList = q.getResultList();
Of course, you may want to programmatically set the parameters of the where clause. You can do that by calling the query object's setParameter method when it has parameterized elements. The following code creates the same query and prints the results, but it allows you to dynamically set the team name:
Query q = em.createQuery("select c from Player c where c.team.teamName = :name");
q.setParameter("name", aTeamName);
List<Player> playerList = q.getResultList();
for(Player p : playerList) {
System.out.println(p.toString());
}
Entity Updates
One you've retrieved a managed entity, either by querying the database with the query language or by using the find method, updating the entity is as easy as modifying its properties and committing the open transaction. For example, you can change a player's number by simply calling the player's setJerseyNumber method. Once you commit the transaction, the entities have new numbers. In the following, example, all players get updated jersey numbers:
em.getTransaction().begin();
for(Player p : playerList) {
// add 1 to each players jersey number
int jersey = p.getJerseyNumber();
p.setJerseyNumber(jersey + 1);
}
em.getTransaction().commit();
Of course a query can do the same job:
Query q = em.createQuery("update Player p " +
"set p.jerseyNumber = (p.jerseyNumber + 1) " +
"where p.team.teamName = :name");
q.setParameter("name", aTeamName);
em.getTransaction().begin();
q.executeUpdate();
em.getTransaction().commit();
Entity Deletes
Finally, you can delete entities using queries. The following code deletes the Anaheim Angels from the database.
String aTeamName = "Anaheim Angels";
...
Query q = em.createQuery("delete from Team t " +
"where t.teamName = :name");
q.setParameter("name", aTeamName);
em.getTransaction().begin();
q.executeUpdate();
em.getTransaction().commit();
Reference Implementation
Persistence provider implementations may be optimized for specific database vendors, but you should avoid using proprietary extensions. One major reason for using the new API is to decouple your application from the underlying database technology. Avoiding proprietary extensions ensures that you can use the widest range of database technologies now and in the future. You should contact your provider vendor for information about what databases they support. In the meantime, you can use the reference implementation provided by the GlassFish Project.
GlassFish is an industrial-strength, open source application server. Being the reference implementation of the Java EE 5 standard, GlassFish also provides a Java Persistence API implementation. You don't have to download the entire GlassFish product to get the API implementation.
Persistence Provider Library Installation
Installing the reference implementation is fairly straightforward. Remember, the filename for your installer may be different depending on when you download it. You will most likely use a more recent version than the one shown here.
Create a subdirectory in your development environment for third-party libraries. For example, you can create a lib subdirectory under your project or home directory. Download and put the installer jar file into the lib directory. Then execute the downloaded installer application like this:
java -Xmx256m -jar glassfish-persistence-installer-v2-b46.jar
This command will create a subdirectory and several files as shown here:
glassfish-persistence
glassfish-persistence/README
glassfish-persistence/3RD-PARTY-LICENSE.txt
glassfish-persistence/LICENSE.txt
glassfish-persistence/toplink-essentials-agent.jar
glassfish-persistence/toplink-essentials.jar
Desktop Project Configuration
You now have all the Java Persistence API reference implementation files on your desktop filesystem. However, you must now configure your development environment to use these files in your project. The goals for configuration are these:
- Include the reference implementation in the Java language compiler classpath
- Include the reference implementation in the Java runtime environment (JRE) classpath
Succeeding in the first goal allows you to use the API implementation when you compile your project. The second goal allows you to run your application on the desktop.
NetBeans 5.5 and later versions already have an installed version of the reference implementation, which is called Toplink Essentials. If you want updated versions of this library, however, you can use these instructions to add the library to your environment. The simplest way to accomplish both goals is to use an integrated development environment. NetBeans or Eclipse are both examples of popular IDEs that will help you include the provider implementation jar files in your compiler and JRE classpaths. The following examples use the NetBeans IDE, but you will use similar steps regardless of your IDE choice.
In NetBeans 5.5, you can create user-defined libraries to include in both the compilation and runtime classpaths. Create a library with these steps:
- Select Tools from the menu. Select Library Manager.
- Select New Library...
- Type the new library name. This article uses "JPA" as the library name. Press the OK button.
- At this point you've defined a library, but no jar files are part of it. You must now add jar files to the library. Click the "Add Jar/Folder..." button and navigate your filesystem to the lib subdirectory you created earlier.
- Select the toplink-essentials.jar file. The toplink-essentials-agent.jar file exists for backwards compatibility with some existing build scripts for the reference implementation project.
- Close the Library Manager windows by clicking the OK button.
Figure 5 shows the new library definition:

Figure 5. You can add multiple jar files to a user-defined library in NetBeans.
You have now created a persistence API library in NetBeans. You can add this library to your project, and NetBeans will include the files in the classpath. Your deployed application will also have copies of these files.
After you've created a NetBeans project, add the persistence provider library to your project library like this:
- Select your project's properties page. One way to select your project's properties is to open the NetBeans File menu, then select the menu item for your project's property page.
- Select the Libraries category, and then click the Add Library button.
- Select the persistence provider library that you previously created, and then add it to your project.

Figure 6. You can modify your project's properties from the IDE.
At this point, you can use the provider classes and methods because their libraries are part of your project.

Figure 7. NetBeans shows the jar files in your project's libraries.
Desktop Application Distribution
You have many options for distributing a desktop application. One common way is to simply create an application jar file and provide it in a shared network folder. You can also copy the application's files to your target desktop. Another popular technology is Java Web Start, which is beyond the scope of this article. For purposes of this article, your project files will be packaged as a jar file with supporting libraries, and you will either put them on a shared network folder or directly on the target desktop.
Again, an IDE is a helpful time saver for creating files for desktop distribution. However, regardless of your IDE, the end goal is to package your application along with the persistence provider libraries that it needs.
You should probably package your application as one or more jar files. Supporting libraries like the provider's jar files should accompany your application in a subdirectory immediately under whatever directory contains your own jar files. For example, if you distribute your application as Persistence.jar, you might place the provider jar files in a lib subdirectory immediately below wherever the Persistence.jar file resides. The following image shows this relationship from within the NetBeans IDE, which packaged the demo code for this article:

Figure 8. Package the reference implementation file in a library subdirectory along with your application.
In this figure, notice that the dist directory contains the Persistence.jar file and a lib subdirectory. The reference implementation files toplink-essentials.jar and toplink-essentials-agent.jar are inside the lib subdirectory. You should consider putting other necessary libraries in the lib subdirectory too. For example, this project used the Java DB database client, which is in the file derbyclient.jar. For more information about how to use Java DB or Derby as your desktop embedded database, please read the article Using Java DB in Desktop Applications.
To make this easy to run, you should put the lib/* libraries in your application's manifest.xml file. Again, IDEs are helpful with this type of task, and the NetBeans IDE can package the Persistence.jar file so that it contains the following manifest.xml file:
Manifest-Version: 1.0
Ant-Version: Apache Ant 1.6.5
Created-By: 1.5.0_07-87 ("Apple Computer, Inc.")
Main-Class: com.sun.demo.jpa.CreatePlayersAndTeams
Class-Path: lib/derbyclient.jar lib/toplink-essentials.jar
Besides declaring the main class of the jar file, the manifest.xml file can do another job; it can help you declare your application's runtime classpath. Notice the Class-Path value in the manifest file. The line tells the runtime environment where to find the libraries it needs.
That powerful feature allows users to run your application without needing to define a separate classpath on the command line. The final effect is that they can launch the application easily by either clicking on the application in their file chooser or by running the following command:
java -jar Persistence.jar
Summary
The Java Persistence API was developed as part of the EJB 3.0 specification. The API simplifies object persistence by enabling use of POJOs throughout your application and in your database.
You can download the Java Persistence API reference implementation from the GlassFish project. Although originally part of the enterprise application server, the reference implementation works well in desktop applications too.
You can easily use and package the reference implementation in your desktop applications. Using the reference implementation, you can simplify your desktop applications to use simple POJOs for both application logic and persistence. Adding the API to your development environment usually involves just including the provider's jar files in your compiler and runtime environment classpaths. An IDE can help you automate the process of packaging an API implementation with your application.
For More Information
- Read JSR 220, the Enterprise JavaBeans 3.0 specification.
- Read the Java Persistence API FAQ
- Study the Java EE 5 Tutorial section entitled Introduction to the Java Persistence API
- Read Using Java DB in Desktop Applications for details on how to embed a 100% Java language database in your application.