Java API for XML Processing (JAXP) Tutorial
Chapter 4
Extensible Stylesheet Language Transformations
The Extensible Stylesheet Language Transformations (XSLT) standard defines mechanisms for addressing XML data (XPath) and for specifying transformations on the data in order to convert it into other forms. JAXP includes an interpreting implementation of XSLT.
In this chapter, you will write out a Document Object Model as an XML file, and you will see how to generate a DOM from an arbitrary data file in order to convert it to XML. Finally, you will convert XML data into a different form, learning about the XPath addressing mechanism along the way.
- Introducing XSL, XSLT, and XPath
- JAXP Transformation Packages
- XSLT Sample Programs
- How XPath Works
- XPath Exliressions
- XSLT/XPath Data Model
- Templates and Contexts
- Basic XPath Addressing
- Basic XPath Exliressions
- Combining Index Addresses
- Wild Cards
- Extended-Path Addressing
- XPath Data Tylies and Olierators
- String-Value of an Element
- XPath Functions
- Node-Set Functions
- Positional Functions
- String Functions
- Boolean Functions
- Numeric Functions
- Conversion Functions
- Namesliace Functions
- Summary
- Writing Out a DOM as an XML File
- Reading the XML
- Creating a Transformer
- Running the
TransformationApp01Sample - Writing Out a Subtree of the DOM
- Running the
TranformationApp02Sample - Generating XML from an Arbitrary Data Structure
- Creating a Simple File
- Creating a Simple Parser
- Running the
AddressBookReader01Sample - Creating a Parser that Generates SAX Events
- Using the Parser as a
SAXSource - Running the
TransformationApp03Sample - Transforming XML Data with XSLT
- Defining a Simple Document Tylie
- Creating a Test Document
- Writing an XSLT Transform
- Processing the Basic Structure Elements
- Process the
<TITLE>Element - Process Headings
- Generate a Runtime Message
- Writing the Basic Program
- Running the
StylizerSample - Trimming the Whitespace
- Running the
StylizerSample with Trimmed Whitespace - Removing the Last Whitespace
- Running the
StylizerSample with All Whitespace Trimmed - Processing the Remaining Structure Elements
- Modify
<PARA>Handling - Process
<LIST>and<ITEM>Elements - Ordering Templates in a Stylesheet
- Process
<NOTE>Elements - Running the
StylizerSample WithLISTandNOTEElements Defined - Process Inline (Content) Elements
- Running the
StylizerSample With Inline Elements Defined - Printing the HTML
- What Else Can XSLT Do?
- The Trouble with Variables
Introducing XSL, XSLT, and XPath
The Extensible Stylesheet Language (XSL) has three major subcomponents:
XSL-FOThe Formatting Objects standard. By far the largest subcomponent, this standard gives mechanisms for describing font sizes, page layouts, and other aspects of object rendering. This subcomponent is not covered by JAXP, nor is it included in this tutorial.
XSLTThis is the transformation language, which lets you define a transformation from XML into some other format. For example, you might use XSLT to produce HTML or a different XML structure. You could even use it to produce plain text or to put the information in some other document format. (And as you will see in Generating XML from an Arbitrary Data Structure, a clever application can press it into service to manipulate non-XML data as well).
XPathAt bottom, XSLT is a language that lets you specify what sorts of things to do when a particular element is encountered. But to write a program for different parts of an XML data structure, you need to specify the part of the structure you are talking about at any given time. XPath is that specification language. It is an addressing mechanism that lets you specify a path to an element so that, for example, <article><title> can be distinguished from <person><title>. In that way, you can describe different kinds of translations for the different <title> elements.
The remainder of this section describes the packages that make up the JAXP Transformation APIs.
JAXP Transformation Packages
Here is a description of the packages that make up the JAXP Transformation APIs:
javax.xml.transform
This package defines the factory class you use to get a Transformer object. You then configure the transformer with input (source) and output (result) objects, and invoke its transform() method to make the transformation happen. The source and result objects are created using classes from one of the other three packages.
javax.xml.transform.dom
Defines the DOMSource and DOMResult classes, which let you use a DOM as an input to or output from a transformation.
javax.xml.transform.sax
Defines the SAXSource and SAXResult classes, which let you use a SAX event generator as input to a transformation, or deliver SAX events as output to a SAX event processor.
javax.xml.transform.stream
Defines the StreamSource and StreamResult classes, which let you use an I/O stream as an input to or output from a transformation.
XSLT Sample Programs
Unlike for the other chapters in this tutorial, the sample programs used in this chapter are not included in the install-dir /jaxp-1_4_2- release-date /samples directory provided with the JAXP 1.4.2 Reference Implementation. However you can download a ZIP file of the XSLT samples here.
How XPath Works
The XPath specification is the foundation for a variety of specifications, including XSLT and linking/addressing specifications such as XPointer. So an understanding of XPath is fundamental to a lot of advanced XML usage. This section provides an introduction to XPath in the context of XSLT.
XPath Expressions
In general, an XPath expression specifies a pattern that selects a set of XML nodes. XSLT templates then use those patterns when applying transformations. ( XPointer, on the other hand, adds mechanisms for defining a point or a range so that XPath expressions can be used for addressing).
The nodes in an XPath expression refer to more than just elements. They also refer to text and attributes, among other things. In fact, the XPath specification defines an abstract document model that defines seven kinds of nodes:
- Root
- Element
- Text
- Attribute
- Comment
- Processing instruction
- Namespace
The root element of the XML data is modeled by an element node. The XPath root node contains the document's root element as well as other information relating to the document.
XSLT/XPath Data Model
Like the Document Object Model (DOM), the XSLT/XPath data model consists of a tree containing a variety of nodes. Under any given element node, there are text nodes, attribute nodes, element nodes, comment nodes, and processing instruction nodes.
In this abstract model, syntactic distinctions disappear, and you are left with a normalized view of the data. In a text node, for example, it makes no difference whether the text was defined in a CDATA section or whether it included entity references. The text node will consist of normalized data, as it exists after all parsing is complete. So the text will contain a < character, whether or not an entity reference such as < or a CDATA section was used to include it. (Similarly, the text will contain an & character, whether it was delivered using & or it was in a CDATA section).
In this section, we will deal mostly with element nodes and text nodes. For the other addressing mechanisms, see the XPath specification.
Templates and Contexts
An XSLT template is a set of formatting instructions that apply to the nodes selected by an XPath expression. In a stylesheet, an XSLT template would look something like this:
<xsl:template match="//LIST">
...
</xsl:template>
The expression //LIST selects the set of LIST nodes from the input stream. Additional instructions within the template tell the system what to do with them.
The set of nodes selected by such an expression defines the context in which other expressions in the template are evaluated. That context can be considered as the whole set - for example, when determining the number of the nodes it contains.
The context can also be considered as a single member of the set, as each member is processed one by one. For example, inside the LIST-processing template, the expression @type refers to the type attribute of the current LIST node. (Similarly, the expression @* refers to all the attributes for the current LIST element).
Basic XPath Addressing
An XML document is a tree-structured (hierarchical) collection of nodes. As with a hierarchical directory structure, it is useful to specify a path that points to a particular node in the hierarchy (hence the name of the specification: XPath). In fact, much of the notation of directory paths is carried over intact:
- The forward slash (/) is used as a path separator.
- An absolute path from the root of the document starts with a /.
- A relative path from a given location starts with anything else.
- A double period (..) indicates the parent of the current node.
- A single period (.) indicates the current node.
For example, in an Extensible HTML (XHTML) document (an XML document that looks like HTML but is well formed according to XML rules), the path /h1/h2/ would indicate an h2 element under an h1. (Recall that in XML, element names are case-sensitive, so this kind of specification works much better in XHTML than it would in plain HTML, because HTML is case-insensitive).
In a pattern-matching specification such as XPath, the specification /h1/h2 selects all h2 elements that lie under an h1 element. To select a specific h2 element, you use square brackets [] for indexing (like those used for arrays). The path /h1[4]/h2[5] would therefore select the fifth h2 element under the fourth h1 element.
Note - In XHTML, all element names are in lowercase. That is a fairly common convention for XML documents. However, uppercase names are easier to read in a tutorial like this one. So for the remainder of the XSLT chapter, all XML element names will be in uppercase. (Attribute names, on the other hand, will remain in lowercase).
A name specified in an XPath expression refers to an element. For example, h1 in /h1/h2 refers to an h1 element. To refer to an attribute, you prefix the attribute name with an @ sign. For example, @type refers to the type attribute of an element. Assuming that you have an XML document with LIST elements, for example, the expression LIST/@type selects the type attribute of the LIST element.
Note - Because the expression does not begin with /, the reference specifies a list node relative to the current context-whatever position in the document that happens to be.
Basic XPath Expressions
The full range of XPath expressions takes advantage of the wild cards, operators, and functions that XPath defines. You will learn more about those shortly. Here, we look at a couple of the most common XPath expressions simply to introduce them.
The expression @type="unordered" specifies an attribute named type whose value is unordered. An expression such as LIST/@type specifies the type attribute of a LIST element.
You can combine those two notations to get something interesting. In XPath, the square-bracket notation ( []) normally associated with indexing is extended to specify selection criteria. So the expression LIST[@type="unordered"] selects all LIST elements whose type value is unordered.
Similar expressions exist for elements. Each element has an associated string-value, which is formed by concatenating all the text segments that lie under the element. (A more detailed explanation of how that process works is presented in String-Value of an Element).
Suppose you model what is going on in your organization using an XML structure that consists of PROJECT elements and ACTIVITY elements that have a text string with the project name, multiple PERSON elements to list the people involved and, optionally, a STATUS element that records the project status. Here are other examples that use the extended square-bracket notation:
/PROJECT[.="MyProject"]: Selects aPROJECTnamed"MyProject"./PROJECT[STATUS]: Selects all projects that have aSTATUSchild element./PROJECT[STATUS="Critical"]: Selects all projects that have aSTATUSchild element with the string-valueCritical.
Combining Index Addresses
The XPath specification defines quite a few addressing mechanisms, and they can be combined in many different ways. As a result, XPath delivers a lot of expressive power for a relatively simple specification. This section illustrates other interesting combinations:
LIST[@type="ordered"][3]: Selects allLISTelements of the typeordered, and returns the third.LIST[3][@type="ordered"]: Selects the thirdLISTelement, but only if it is of the typeordered.
Note - Many more combinations of address operators are listed in section 2.5 of the XPath specification. This is arguably the most useful section of the specification for defining an XSLT transform.
Wild Cards
By definition, an unqualified XPath expression selects a set of XML nodes that matches that specified pattern. For example, /HEAD matches all top-level HEAD entries, whereas /HEAD[1] matches only the first. Table 4-1 lists the wild cards that can be used in XPath expressions to broaden the scope of the pattern matching.
Table 4-1 XPath Wild Cards
|
Wild card |
Meaning |
|---|---|
* | Matches any element node (not attributes or text). |
node() | Matches any node of any kind: element node, text node, attribute node, processing instruction node, namespace node, or comment node. |
@* | Matches any attribute node. |
In the project database example, /*/PERSON[.="Fred"] matches any PROJECT or ACTIVITY element that names Fred.
Extended-Path Addressing
So far, all the patterns you have seen have specified an exact number of levels in the hierarchy. For example, /HEAD specifies any HEAD element at the first level in the hierarchy, whereas /*/* specifies any element at the second level in the hierarchy. To specify an indeterminate level in the hierarchy, use a double forward slash ( //). For example, the XPath expression //PARA selects all paragraph elements in a document, wherever they may be found.
The // pattern can also be used within a path. So the expression /HEAD/LIST//PARA indicates all paragraph elements in a subtree that begins from / HEAD/LIST.
XPath Data Types and Operators
XPath expressions yield either a set of nodes, a string, a Boolean (a true/false value), or a number. Table 4-2 lists the operators that can be used in an Xpath expression:
Table 4-2 XPath Operators
| Operator | Meaning |
|---|---|
|
|
Alternative. For example, PARA|LIST selects all PARA and LIST elements.
|
or, and
| Returns the or/and of two Boolean values. |
=, != | Equal or not equal, for Booleans, strings, and numbers. |
<, >, <=, >= | Less than, greater than, less than or equal to, greater than or equal to, for numbers. |
+, -, *, div, mod | Add, subtract, multiply, floating-point divide, and modulus (remainder) operations (e.g., 6 mod 4 = 2). |
Expressions can be grouped in parentheses, so you do not have to worry about operator precedence.
Note - Operator precedence is a term that answers the question, "If you specify a + b * c, does that mean (a+b) * c or a + (b*c)?" (The operator precedence is roughly the same as that shown in the table).
String-Value of an Element
The string-value of an element is the concatenation of all descendent text nodes, no matter how deep. Consider this mixed-content XML data:
<PARA>This paragraph contains a <B>bold</B> word</PARA>
The string-value of the <PARA> element is This paragraph contains a bold word. In particular, note that <B> is a child of <PARA> and that the text bold is a child of <B>.
The point is that all the text in all children of a node joins in the concatenation to form the string-value.
Also, it is worth understanding that the text in the abstract data model defined by XPath is fully normalized. So whether the XML structure contains the entity reference < or < in a CDATA section, the element's string-value will contain the < character. Therefore, when generating HTML or XML with an XSLT stylesheet, you must convert occurrences of < to < or enclose them in a CDATA section. Similarly, occurrences of & must be converted to &.
XPath Functions
This section ends with an overview of the XPath functions. You can use XPath functions to select a collection of nodes in the same way that you would use an element specification such as those you have already seen. Other functions return a string, a number, or a Boolean value. For example, the expression /PROJECT/text() gets the string-value of PROJECT nodes.
Many functions depend on the current context. In the preceding example, the context for each invocation of the text() function is the PROJECT node that is currently selected.
There are many XPath functions - too many to describe in detail here. This section provides a brief listing that shows the available XPath functions, along with a summary of what they do. For more information about functions, see section 4 of the XPath specification.
Node-Set Functions
Many XPath expressions select a set of nodes. In essence, they return a node-set. One function does that, too. The id(...) function returns the node with the specified ID. (Elements have an ID only when the document has a DTD, which specifies which attribute has the ID type).
Positional Functions
These functions return positionally based numeric values.
last(): Returns the index of the last element. For example,/HEAD[last()]selects the lastHEADelement.position(): Returns the index position. For example,/HEAD[position() <= 5]selects the first fiveHEADelements.count(...): Returns the count of elements. For example,/HEAD[count(HEAD)=0]selects allHEADelements that have no subheads.
String Functions
These functions operate on or return strings.
concat(string, string, ...): Concatenates the string values.starts-with(string1, string2): Returns true ifstring1starts withstring2.contains(string1, string2): Returns true ifstring1containsstring2.substring-before(string1, string2): Returns the start ofstring1beforestring2occurs in it.substring-after(string1, string2): Returns the remainder ofstring1afterstring2occurs in it.substring(string, idx): Returns the substring from the index position to the end, where the index of the firstchar= 1.substring(string, idx, len): Returns the substring of the specified length from the index position.string-length(): Returns the size of the context node's string-value; the context node is the currently selected node-the node that was selected by an XPath expression in which a function such asstring-length()is applied.string-length(string): Returns the size of the specified string.normalize-space(): Returns the normalized string-value of the current node (no leading or trailing white space, and sequences of white space characters converted to a single space).normalize-space(string): Returns the normalized string-value of the specified string.translate(string1, string2, string3): Convertsstring1, replacing occurrences of characters instring2with the corresponding character fromstring3.
Note - XPath defines three ways to get the text of an element: text(), string(object), and the string-value implied by an element name in an expression like this: /PROJECT[PERSON="Fred"].
Boolean Functions
These functions operate on or return Boolean values.
not(...): Negates the specified Boolean value.true(): Returns true.false(): Returns false.lang(string): Returns true if the language of the context node (specified byxml:Langattributes) is the same as (or a sub-language of) the specified language; for example, Lang("en") is true for<PARA_xml:Lang="en">...</PARA>.
Numeric Functions
These functions operate on or return numeric values.
sum(...): Returns the sum of the numeric value of each node in the specified node-set.floor(N): Returns the largest integer that is not greater than N.ceiling(N): Returns the smallest integer that is not less than N.round(N): Returns the integer that is closest to N.
Conversion Functions
These functions convert one data type to another.
string(...): Returns the string value of a number, Boolean, or node-set.boolean(...): Returns a Boolean value for a number, string, or node-set (a non-zero number, a non-empty node-set, and a non-empty string are all true).number(...): Returns the numeric value of a Boolean, string, or node-set (true is 1, false is 0, a string containing a number becomes that number, the string-value of a node-set is converted to a number).
Namespace Functions
These functions let you determine the namespace characteristics of a node.
local-name(): Returns the name of the current node, minus the namespace prefix.local-name(...): Returns the name of the first node in the specified node set, minus the namespace prefix.namespace-uri(): Returns the namespace URI from the current node.namespace-uri(...): Returns the namespace URI from the first node in the specified node-set.name(): Returns the expanded name (URI plus local name) of the current node.name(...): Returns the expanded name (URI plus local name) of the first node in the specified node-set.
Summary
XPath operators, functions, wild cards, and node-addressing mechanisms can be combined in wide variety of ways. The introduction you have had so far should give you a good head start at specifying the pattern you need for any particular purpose.
Writing Out a DOM as an XML File
After you have constructed a DOM (either by parsing an XML file or building it programmatically) you frequently want to save it as XML. This section shows you how to do that using the Xalan transform package.
Using that package, you will create a transformer object to wire a DOMSource to a StreamResult. You will then invoke the transformer's transform() method to write out the DOM as XML data.
Reading the XML
The first step is to create a DOM in memory by parsing an XML file. By now, you should be getting comfortable with the process.
Note - The code discussed in this section is in the file TransformationApp01.java. Download the XSLT examples and unzip them into the install-dir /jaxp-1_4_2- release-date /samples directory.
The following code provides a basic template to start from. It is basically the same code as was used at the start of Chapter 3, Document Object Model.
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.FactoryConfigurationError;
import javax.xml.parsers.ParserConfigurationException;
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
import org.w3c.dom.Document;
import org.w3c.dom.DOMException;
import java.io.*;
public class TransformationApp01
{
static Document document;
public static void main(String argv[])
{
if (argv.length != 1) {
System.err.println (
"Usage: java TransformationApp01 filename");
System.exit (1);
}
DocumentBuilderFactory factory =
DocumentBuilderFactory.newInstance();
//factory.setNamespaceAware(true);
//factory.setValidating(true);
try {
File f = new File(argv[0]);
DocumentBuilder builder =
factory.newDocumentBuilder();
document = builder.parse(f);
} catch (SAXParseException spe) {
// Error generated by the parser
System.out.println("\n** Parsing error"
+ ", line " + spe.getLineNumber()
+ ", uri " + spe.getSystemId());
System.out.println(" " + spe.getMessage() );
// Use the contained exception, if any
Exception x = spe;
if (spe.getException() != null)
x = spe.getException();
x.printStackTrace();
} catch (SAXException sxe) {
// Error generated by this application
// (or a parser-initialization error)
Exception x = sxe;
if (sxe.getException() != null)
x = sxe.getException();
x.printStackTrace();
} catch (ParserConfigurationException pce) {
// Parser with specified options cannot be built
pce.printStackTrace();
} catch (IOException ioe) {
// I/O error
ioe.printStackTrace();
}
} // main
}
Creating a Transformer
The next step is to create a transformer you can use to transmit the XML to System.out. To begin with, the following import statements are required.
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import java.io.*;
Here, you add a series of classes that should now be forming a standard pattern: an entity ( Transformer), the factory to create it ( TransformerFactory), and the exceptions that can be generated by each. Because a transformation always has a source and a result, you then import the classes necessary to use a DOM as a source ( DOMSource) and an output stream for the result ( StreamResult).
Next, add the code to carry out the transformation:
try {
File f = new File(argv[0]);
DocumentBuilder builder = factory.newDocumentBuilder();
document = builder.parse(f);
// Use a Transformer for output
TransformerFactory tFactory =
TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer();
DOMSource source = new DOMSource(document);
StreamResult result = new StreamResult(System.out);
transformer.transform(source, result);
Here, you create a transformer object, use the DOM to construct a source object, and use System.out to construct a result object. You then tell the transformer to operate on the source object and output to the result object.
In this case, the "transformer" is not actually changing anything. In XSLT terminology, you are using the identity transform, which means that the "transformation" generates a copy of the source, unchanged.
Note - You can specify a variety of output properties for transformer objects, as defined in the W3C specification at //www.w3.org/TR/xslt#output.. For example, to get indented output, you can invoke the following method:
% transformer.setOutputProperty(OutputKeys.INDENT, "yes");
Finally, the following highlighted code catches the new errors that can be generated:
} catch (TransformerConfigurationException tce) {
System.out.println ("* Transformer Factory error");
System.out.println(" " + tce.getMessage() );
Throwable x = tce;
if (tce.getException() != null)
x = tce.getException();
x.printStackTrace();
} catch (TransformerException te) {
System.out.println ("* Transformation error");
System.out.println(" " + te.getMessage() );
Throwable x = te;
if (te.getException() != null)
x = te.getException();
x.printStackTrace();
} catch (SAXParseException spe) {
...
Notes:
TransformerExceptionsare thrown by the transformer object.TransformerConfigurationExceptionsare thrown by the factory.- To preserve the XML document's
DOCTYPEsetting, it is also necessary to add the following code:import javax.xml.transform.OutputKeys; ... if (document.getDoctype() != null){ String systemValue = (new File(document.getDoctype().getSystemId())).getName(); transformer.setOutputProperty( OutputKeys.DOCTYPE_SYSTEM, systemValue ); }
To find out more about configuring the factory and handling validation errors, see Reading XML Data into a DOM.
Running the TransformationApp01 Sample
- Navigate to the
samplesdirectory.% cd install-dir /jaxp-1_4_2- release-date /samples. - Download the XSLT examples by clicking this link and unzip them into the install-dir
/jaxp-1_4_2-release-date/samplesdirectory. - Navigate to the
xsltdirectory.% cd xslt. - Compile the
TransformationApp01sample.Type the following command:
% javac TransformationApp01.java - Run the
TransformationApp01sample on an XML file.In the case below,
TransformationApp01is run on the filefoo.xml, found in thexslt/datadirectory after you have unzipped the samples bundle.% java TransformationApp01 data/foo.xmlYou will see the following output:
<?xml version="1.0" encoding="UTF-8" standalone="no"?><doc> <name first="David" last="Marston"/> <name first="David" last="Bertoni"/> <name first="Donald" last="Leslie"/> <name first="Emily" last="Farmer"/> <name first="Joseph" last="Kesselman"/> <name first="Myriam" last="Midy"/> <name first="Paul" last="Dick"/> <name first="Stephen" last="Auriemma"/> <name first="Scott" last="Boag"/> <name first="Shane" last="Curcuru"/>As mentioned in Creating a Transformer, this transformer has not actually changed anything, but rather has just performed the identity transform, to generate a copy of the source. A real transformation will be performed in Generating XML from an Arbitrary Data Structure.
Writing Out a Subtree of the DOM
It is also possible to operate on a subtree of a DOM. In this section, you will experiment with that option.
Note - The code discussed in this section is in TranformationApp02.java. If you have not done so already, download the XSLT examples and unzip them into the install-dir /jaxp-1_4_2- release-date /samples directory.
The only difference in the process is that now you will create a DOMSource using a node in the DOM, rather than the entire DOM. The first step is to import the classes you need to get the node you want, as shown in the following highlighted code:
import org.w3c.dom.Document;
import org.w3c.dom.DOMException;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
The next step is to find a good node for the experiment. The following highlighted code selects the first <name> element.
try {
File f = new File(argv[0]);
DocumentBuilder builder = factory.newDocumentBuilder();
document = builder.parse(f);
NodeList list = document.getElementsByTagName("name");
Node node = list.item(0);
In Creating a Transformer, the source object was constructed from the entire document by the following line of code
DOMSource source = new DOMSource(document);
However, the highlighted line of code below constructs a source object that consists of the subtree rooted at a particular node.
DOMSource source = new DOMSource(node);
StreamResult result = new StreamResult(System.out);
transformer.transform(source, result);
Running the TranformationApp02 Sample
- Navigate to the
samplesdirectory.% cd install-dir /jaxp-1_4_2- release-date /samples. - Download the XSLT examples by clicking this link and unzip them into the install-dir
/jaxp-1_4_2-release-date/samplesdirectory. - Navigate to the
xsltdirectory.cd xslt - Compile the
TranformationApp02sample.Type the following command:
% javac xslt/TranformationApp02.java - Run the
TranformationApp02sample on an XML file.In the case below,
TranformationApp02is run on the filefoo.xml, found in thexslt/datadirectory after you have unzipped the samples bundle.% java TranformationApp02 data/foo.xmlYou will see the following output:
<?xml version="1.0" encoding="UTF-8" standalone="no"?><doc><name first="David" last="Marston"/>This time, only the first
<name>element was printed out.At this point, you have seen how to use a transformer to write out a DOM and how to use a subtree of a DOM as the source object in a transformation. In the next section, you will see how to use a transformer to create XML from any data structure you are capable of parsing.
Generating XML from an Arbitrary Data Structure
This section uses XSLT to convert an arbitrary data structure to XML.
Here is an outline of the process:
- Modify an existing program that reads the data, to make it generate SAX events. (Whether that program is a real parser or simply a data filter of some kind is irrelevant for the moment).
- Use the SAX "parser" to construct a
SAXSourcefor the transformation. - Use the same
StreamResultobject as created in the last exercise to display the results. (But note that you could just as easily create aDOMResultobject to create a DOM in memory). - Wire the source to the result using the transformer object to make the conversion.
For starters, you need a data set you want to convert and a program capable of reading the data. The next two sections create a simple data file and a program that reads it.
Creating a Simple File
This example uses data set for an address book, PersonalAddressBook.ldif. If you have not done so already, download the XSLT examples and unzip them into the install-dir /jaxp-1_4_2- release-date /samples directory. The file shown here was produced by creating a new address book in Netscape Messenger, giving it some dummy data (one address card), and then exporting it in LDAP Data Interchange Format (LDIF) format. It contained in the directory xslt/data after you unzip the XSLT examples.
Figure 4-1 shows the address book entry that was created.
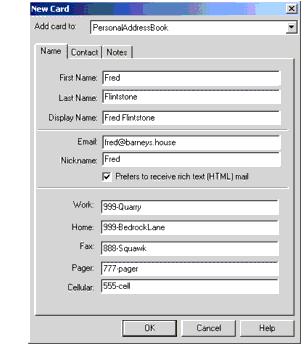
Figure 4-1 Address Book Entry
Exporting the address book produces a file like the one shown next. The parts of the file that we care about are shown in bold.
dn: cn=Fred Flintstone,mail=fred@barneys.house
modifytimestamp: 20010409210816Z
cn: Fred Flintstone
xmozillanickname: Fred
mail: Fred@barneys.house
xmozillausehtmlmail: TRUE
givenname: Fred
sn: Flintstone
telephonenumber: 999-Quarry
homephone: 999-BedrockLane
facsimiletelephonenumber: 888-Squawk
pagerphone: 777-pager
cellphone: 555-cell
xmozillaanyphone: 999-Quarry
objectclass: top
objectclass: person
Note that each line of the file contains a variable name, a colon, and a space followed by a value for the variable. The sn variable contains the person's surname (last name) and the variable cn contains the DisplayName field from the address book entry.
Creating a Simple Parser
The next step is to create a program that parses the data.
Note - The code discussed in this section is in AddressBookReader01.java, which is found in the xslt directory after you unzip XSLT examples into the install-dir /jaxp-1_4_2- release-date /samples directory.
The text for the program is shown next. It is an extremely simple program that does not even loop for multiple entries because, after all, it is only a demo.
import java.io.*;
public class AddressBookReader01
{
public static void main(String argv[])
{
// Check the arguments
if (argv.length != 1) {
System.err.println (
"Usage: java AddressBookReader01 filename");
System.exit (1);
}
String filename = argv[0];
File f = new File(filename);
AddressBookReader01 reader = new AddressBookReader01();
reader.parse(f);
}
/** Parse the input */
public void parse(File f)
{
try {
// Get an efficient reader for the file
FileReader r = new FileReader(f);
BufferedReader br = new BufferedReader(r);
// Read the file and display its contents.
String line = br.readLine();
while (null != (line = br.readLine())) {
if (line.startsWith("xmozillanickname: "))
break;
}
output("nickname", "xmozillanickname", line);
line = br.readLine();
output("email", "mail", line);
line = br.readLine();
output("html", "xmozillausehtmlmail", line);
line = br.readLine();
output("firstname","givenname", line);
line = br.readLine();
output("lastname", "sn", line);
line = br.readLine();
output("work", "telephonenumber", line);
line = br.readLine();
output("home", "homephone", line);
line = br.readLine();
output("fax", "facsimiletelephonenumber",
line);
line = br.readLine();
output("pager", "pagerphone", line);
line = br.readLine();
output("cell", "cellphone", line);
}
catch (Exception e) {
e.printStackTrace();
}
}
This program contains three methods:
main
The main method gets the name of the file from the command line, creates an instance of the parser, and sets it to work parsing the file. This method will disappear when we convert the program into a SAX parser. (That is one reason for putting the parsing code into a separate method).
parse
This method operates on the File object sent to it by the main routine. As you can see, it is very straightforward. The only concession to efficiency is the use of a BufferedReader, which can become important when you start operating on large files.
output
The output method contains the logic for the structure of a line. It takes three arguments. The first argument gives the method a name to display, so it can output html as a variable name, instead of xmozillausehtmlmail. The second argument gives the variable name stored in the file ( xmozillausehtmlmail). The third argument gives the line containing the data. The routine then strips off the variable name from the start of the line and outputs the desired name, plus the data.
Running the AddressBookReader01 Sample
- Navigate to the
samplesdirectory.% cd install-dir /jaxp-1_4_2- release-date /samples. - Download the XSLT examples by clicking this link and unzip them into the install-dir
/jaxp-1_4_2-release-date/samplesdirectory. - Navigate to the
xsltdirectory.cd xslt - Compile the
AddressBookReader01sample.Type the following command:
% javac AddressBookReader01.java - Run the
AddressBookReader01sample on a data file.In the case below,
AddressBookReader01is run on the filePersonalAddressBook.ldifshown above, found in thexslt/datadirectory after you have unzipped the samples bundle.% java AddressBookReader01 data/PersonalAddressBook.ldifYou will see the following output:
nickname: Fred email: Fred@barneys.house html: TRUE firstname: Fred lastname: Flintstone work: 999-Quarry home: 999-BedrockLane fax: 888-Squawk pager: 777-pager cell: 555-cellThis is a bit more readable than the file shown in Creating a Simple File.
Creating a Parser that Generates SAX Events
This section shows how to make the parser generate SAX events, so that you can use it as the basis for a SAXSource object in an XSLT transform.
Note - The code discussed in this section is in AddressBookReader02.java, which is found in the xslt directory after you unzip XSLT examples into the install-dir /jaxp-1_4_2- release-date /samples directory. AddressBookReader02.java is adapted from AddressBookReader01.java, so only the differences in code between the two examples will be discussed here.
AddressBookReader02 requires the following highlighted classes that were not used in AddressBookReader01.
import java.io.*;
import org.xml.sax.*;
import org.xml.sax.helpers.AttributesImpl;
The application also extends XmlReader. This change converts the application into a parser that generates the appropriate SAX events.
public class AddressBookReader02
implements XMLReader
{
Unlike the AddressBookReader01 sample, this application does not have a main method.
The following global variables will be used later in this section:
public class AddressBookReader02
implements XMLReader
{
ContentHandler handler;
String nsu = "";
Attributes atts = new AttributesImpl();
String rootElement = "addressbook";
String indent = "\n ";
The SAX ContentHandler is the object that will get the SAX events generated by the parser. To make the application into an XmlReader, the application defines a setContentHandler method. The handler variable will hold a reference to the object that is sent when setContentHandler is invoked.
When the parser generates SAX element events, it will need to supply namespace and attribute information. Because this is a simple application, it defines null values for both of those.
The application also defines a root element for the data structure ( addressbook) and sets up an indent string to improve the readability of the output.
Furthermore, the parse method is modified so that it takes an InputSource (rather than a File) as an argument and accounts for the exceptions it can generate:
public void parse
(InputSource input)
throws IOException, SAXException
Now, rather than creating a new FileReader instance as was done in AddressBookReader01, the reader is encapsulated by the InputSource object:
try {
java.io.Reader r = input.getCharacterStream();
BufferedReader Br = new BufferedReader(r);
Note - The next section shows how to create the input source object and what is put in it will, in fact, be a buffered reader. But the AddressBookReader could be used by someone else, somewhere down the line. This step makes sure that the processing will be efficient, regardless of the reader you are given.
The next step is to modify the parse method to generate SAX events for the start of the document and the root element. The following highlighted code does that:
public void parse(InputSource input)
...
{
try {
...
String line = br.readLine();
while (null != (line = br.readLine())) {
if (line.startsWith("xmozillanickname: ")) break;
}
if (handler==null) {
throw new SAXException("No content handler");
}
handler.startDocument();
handler.startElement(nsu, rootElement,
rootElement, atts);
output("nickname", "xmozillanickname", line);
...
output("cell", "cellphone", line);
handler.ignorableWhitespace("\n".toCharArray(),
0, // start index
1 // length
);
handler.endElement(nsu, rootElement, rootElement);
handler.endDocument();
}
catch (Exception e) {
...
Here, the application checks to make sure that the parser is properly configured with a ContentHandler. (For this application, we do not care about anything else). It then generates the events for the start of the document and the root element, and finishes by sending the end event for the root element and the end event for the document.
Two items are noteworthy at this point:
- The
setDocumentLocatorevent has not been sent, because that is optional. Were it important, that event would be sent immediately before thestartDocumentevent. - An
ignorableWhitespaceevent is generated before the end of the root element. This, too, is optional, but it drastically improves the readability of the output, as will be seen shortly. (In this case, the whitespace consists of a single newline, which is sent in the same way that characters are sent to the characters method: as a character array, a starting index, and a length).
Now that SAX events are being generated for the document and the root element, the next step is to modify the output method to generate the appropriate element events for each data item. Removing the call to System.out.println(name + ": " + text) and adding the following highlighted code achieves that:
void output(String name, String prefix, String line)
throws SAXException
{
int startIndex = prefix.length() + 2; // 2=length of ": "
String text = line.substring(startIndex);
int textLength = line.length() - startIndex;
handler.ignorableWhitespace(indent.toCharArray(),
0, // start index
indent.length()
);
handler.startElement(nsu, name, name /*"qName"*/, atts);
handler.characters(line.toCharArray(),
startIndex,
textLength);
handler.endElement(nsu, name, name);
}
Because the ContentHandler methods can send SAXExceptions back to the parser, the parser must be prepared to deal with them. In this case, none are expected, so the application is simply allowed to fail if any occur.
The length of the data is then calculated, again generating some ignorable whitespace for readability. In this case, there is only one level of data, so we can use a fixed-indent string. (If the data were more structured, we would have to calculate how much space to indent, depending on the nesting of the data).
Note - The indent string makes no difference to the data but will make the output a lot easier to read. Without that string, all the elements would be concatenated end to end:
<addressbook><nickname>Fred</nickname><email>...
Next, the following method configures the parser with the ContentHandler that is to receive the events it generates:
void output(String name, String prefix, String line)
throws SAXException
{
...
}
/** Allow an application to register a content event handler. */
public void setContentHandler(ContentHandler handler) {
this.handler = handler;
}
/** Return the current content handler. */
public ContentHandler getContentHandler() {
return this.handler;
}
Several other methods must be implemented in order to satisfy the XmlReader interface. For the purpose of this exercise, null methods are generated for all of them. A production application, however, would require that the error handler methods be implemented to produce a more robust application. For this example, though, the following code generates null methods for them:
/** Allow an application to register an error event handler. */
public void setErrorHandler(ErrorHandler handler)
{ }
/** Return the current error handler. */
public ErrorHandler getErrorHandler()
{ return null; }
Then the following code generates null methods for the remainder of the XmlReader interface. (Most of them are of value to a real SAX parser but have little bearing on a data-conversion application like this one).
/** Parse an XML document from a system identifier (URI). */
public void parse(String systemId)
throws IOException, SAXException
{ }
/** Return the current DTD handler. */
public DTDHandler getDTDHandler()
{ return null; }
/** Return the current entity resolver. */
public EntityResolver getEntityResolver()
{ return null; }
/** Allow an application to register an entity resolver. */
public void setEntityResolver(EntityResolver resolver)
{ }
/** Allow an application to register a DTD event handler. */
public void setDTDHandler(DTDHandler handler)
{ }
/** Look up the value of a property. */
public Object getProperty(String name)
{ return null; }
/** Set the value of a property. */
public void setProperty(String name, Object value)
{ }
/** Set the state of a feature. */
public void setFeature(String name, boolean value)
{ }
/** Look up the value of a feature. */
public boolean getFeature(String name)
{ return false; }
You now have a parser you can use to generate SAX events. In the next section, you will use it to construct a SAX source object that will let you transform the data into XML.
Using the Parser as a SAXSource
Given a SAX parser to use as an event source, you can construct a transformer to produce a result. In this section, TransformerApp will be updated to produce a stream output result, although it could just as easily produce a DOM result.
Note - Note: The code discussed in this section is in TransformationApp03.java, which is found in the xslt directory after you unzip XSLT examples into the install-dir /jaxp-1_4_2- release-date /samples directory.
To start with, TransformationApp03 differs from TransformationApp02 in the classes it needs to import to construct a SAXSource object. These classes are shown highlighted below. The DOM classes are no longer needed at this point, so have been discarded, although leaving them in does not do any harm.
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
import org.xml.sax.ContentHandler;
import org.xml.sax.InputSource;
import javax.xml.transform.sax.SAXSource;
import javax.xml.transform.stream.StreamResult;
Next, instead of creating a DOM DocumentBuilderFactory instance, the application creates a SAX parser, which is an instance of the AddressBookReader:
public class TransformationApp03
{
static Document document;
public static void main(String argv[])
{
...
// Create the sax "parser".
AddressBookReader saxReader = new AddressBookReader();
try {
File f = new File(argv[0]);
Then, the following highlighted code constructs a SAXSource object
// Use a Transformer for output
...
Transformer transformer = tFactory.newTransformer();
// Use the parser as a SAX source for input
FileReader fr = new FileReader(f);
BufferedReader br = new BufferedReader(fr);
InputSource inputSource = new InputSource(br);
SAXSource source = new SAXSource(saxReader, inputSource);
StreamResult result = new StreamResult(System.out);
transformer.transform(source, result);
Here, TransformationApp03 constructs a buffered reader (as mentioned earlier) and encapsulates it in an input source object. It then creates a SAXSource object, passing it the reader and the InputSource object, and passes that to the transformer.
When the application runs, the transformer configures itself as the ContentHandler for the SAX parser (the AddressBookReader) and tells the parser to operate on the inputSource object. Events generated by the parser then go to the transformer, which does the appropriate thing and passes the data on to the result object.
Finally, TransformationApp03 does not generate exceptions, so the exception handling code seen in TransformationApp02 is no longer present.
Running the TransformationApp03 Sample
- Navigate to the
samplesdirectory.% cd install-dir /jaxp-1_4_2- release-date /samples. - Download the XSLT examples by clicking this link and unzip them into the install-dir
/jaxp-1_4_2-release-date/samplesdirectory. - Navigate to the
xsltdirectory.cd xslt - Compile the
TransformationApp03sample.Type the following command:
% javac TransformationApp03.java - Run the
TransformationApp03sample on a data file you wish to convert to XML.In the case below,
TransformationApp03is run on thePersonalAddressBook.ldiffile, found in thexslt/datadirectory after you have unzipped the samples bundle.% java TransformationApp03 data/PersonalAddressBook.ldifYou will see the following output:
<?xml version="1.0" encoding="UTF-8"?> <addressbook> <nickname>Fred</nickname> <email>Fred@barneys.house</email> <html>TRUE</html> <firstname>Fred</firstname> <lastname>Flintstone</lastname> <work>999-Quarry</work> <home>999-BedrockLane</home> <fax>888-Squawk</fax> <pager>777-pager</pager> <cell>555-cell</cell> </addressbook>As you can see, the LDIF format file
PersonalAddressBookhas been converted to XML!
Transforming XML Data with XSLT
The Extensible Stylesheet Language Transformations (XSLT) APIs can be used for many purposes. For example, with a sufficiently intelligent stylesheet, you could generate PDF or PostScript output from the XML data. But generally, XSLT is used to generate formatted HTML output, or to create an alternative XML representation of the data.
In this section, an XSLT transform is used to translate XML input data to HTML output.
Note - The XSLT specification is large and complex, so this tutorial can only scratch the surface. It will give you a little background so you can understand simple XSLT processing tasks, but it does not examine in detail how to write an XSLT transform, rather concentrating on how to use JAXP's XSLT transform API. For a more thorough grounding in XSLT, consult a good reference manual, such as Michael Kay's XSLT 2.0 and XPath 2.0: Programmer's Reference (Wrox, 2008).
Defining a Simple Document Type
Start by defining a very simple document type that can be used for writing articles. Our article documents will contain these structure tags:
<TITLE>: The title of the article<SECT>: A section, consisting of a heading and a body<PARA>: A paragraph<LIST>: A list<ITEM>: An entry in a list<NOTE>: An aside, that is offset from the main text
The slightly unusual aspect of this structure is that we will not create a separate element tag for a section heading. Such elements are commonly created to distinguish the heading text (and any tags it contains) from the body of the section (that is, any structure elements underneath the heading).
Instead, we will allow the heading to merge seamlessly into the body of a section. That arrangement adds some complexity to the stylesheet, but it will give us a chance to explore XSLT's template-selection mechanisms. It also matches our intuitive expectations about document structure, where the text of a heading is followed directly by structure elements, an arrangement that can simplify outline-oriented editing.
Note - This kind of structure is not easily validated, because XML's mixed-content model allows text anywhere in a section, whereas we want to confine text and inline elements so that they appear only before the first structure element in the body of the section. The assertion-based validator can do it, but most other schema mechanisms cannot. So we will dispense with defining a DTD for the document type.
In this structure, sections can be nested. The depth of the nesting will determine what kind of HTML formatting to use for the section heading (for example, h1 or h2). Using a plain SECT tag (instead of numbered sections) is also useful with outline-oriented editing, because it lets you move sections around at will without having to worry about changing the numbering for any of the affected sections.
For lists, we will use a type attribute to specify whether the list entries are unordered (bulleted), alpha (enumerated with lowercase letters), ALPHA (enumerated with uppercase letters), or numbered.
We will also allow for some inline tags that change the appearance of the text.
<B>: Bold<I>: Italics<U>: Underline<DEF>: Definition<LINK>: Link to a URL
Note - An inline tag does not generate a line break, so a style change caused by an inline tag does not affect the flow of text on the page (although it will affect the appearance of that text). A structure tag, on the other hand, demarcates a new segment of text, so at a minimum it always generates a line break in addition to other format changes.
The <DEF> tag will be used for terms that are defined in the text. Such terms will be displayed in italics, the way they ordinarily are in a document. But using a special tag in the XML will allow an index program to find such definitions and add them to an index, along with keywords in headings. In the preceding Note, for example, the definitions of inline tags and structure tags could have been marked with <DEF> tags for future indexing.
Finally, the LINK tag serves two purposes. First, it will let us create a link to a URL without having to put the URL in twice; so we can code <link>http//...</link> instead of <a href="http//...">http//...</a>. Of course, we will also want to allow a form that looks like <link target="...">...name...</link>. That leads to the second reason for the <link> tag. It will give us an opportunity to play with conditional expressions in XSLT.
Note - Although the article structure is exceedingly simple (consisting of only eleven tags), it raises enough interesting problems to give us a good view of XSLT's basic capabilities. But we will still leave large areas of the specification untouched. In What Else Can XSLT Do?, we will point out the major features we skipped.
Creating a Test Document
Here, you will create a simple test document using nested <SECT> elements, a few <PARA> elements, a <NOTE> element, a <LINK>, and a <LIST type="unordered">. The idea is to create a document with one of everything so that we can explore the more interesting translation mechanisms.
Note - The code discussed in this section is in article1.xml, which is found in the xslt/data directory after you unzip XSLT examples into the install-dir /jaxp-1_4_2- release-date /samples directory.
To make the test document, create a file called article.xml and enter the following XML data.
<?xml version="1.0"?>
<ARTICLE>
<TITLE>A Sample Article</TITLE>
<SECT>The First Major Section
<PARA>This section will introduce a subsection.</PARA>
<SECT>The Subsection Heading
<PARA>This is the text of the subsection.
</PARA>
</SECT>
</SECT>
</ARTICLE>
Note that in the XML file, the subsection is totally contained within the major section. (In HTML, on the other hand, headings do not contain the body of a section). The result is an outline structure that is harder to edit in plain text form, like this, but is much easier to edit with an outline-oriented editor.
Someday, given a tree-oriented XML editor that understands inline tags such as <B> and <I>, it should be possible to edit an article of this kind in outline form, without requiring a complicated stylesheet. (Such an editor would allow the writer to focus on the structure of the article, leaving layout until much later in the process). In such an editor, the article fragment would look something like this:
<ARTICLE>
<TITLE>A Sample Article
<SECT>The First Major Section
<PARA>This section will introduce a subsection.
<SECT>The Subheading
<PARA>This is the text of the subsection. Note that ...
Note - At the moment, tree-structured editors exist, but they treat inline tags such as <B> and <I> in the same way that they treat structure tags, and that can make the "outline" a bit difficult to read.
Writing an XSLT Transform
Now it is time to begin writing an XSLT transform that will convert the XML article and render it in HTML.
Note - The code discussed in this section is in article1a.xsl, which is found in the xslt/data directory after you unzip XSLT examples into the install-dir /jaxp-1_4_2- release-date /samples directory.
Start by creating a normal XML document:
<?xml version="1.0" encoding="ISO-8859-1"?>
Then add the following highlighted lines to create an XSL stylesheet:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0"
>
</xsl:stylesheet>
Now set it up to produce HTML-compatible output.
<xsl:stylesheet
[...]
>
<xsl:output method="html"/>
[...]
</xsl:stylesheet>
We will get into the detailed reasons for that entry later in this section. For now, note that if you want to output anything other than well-formed XML, then you will need an <xsl:output> tag like the one shown, specifying either text or html. (The default value is xml).
Note - When you specify XML output, you can add the indent attribute to produce nicely indented XML output. The specification looks like this: <xsl:output method="xml" indent="yes"/>.
Processing the Basic Structure Elements
You will start filling in the stylesheet by processing the elements that go into creating a table of contents: the root element, the title element, and headings. You will also process the PARA element defined in the test document.
Note - If on first reading you skipped the section that discusses the XPath addressing mechanisms, How XPath Works, now is a good time to go back and review that section.
Begin by adding the main instruction that processes the root element:
<xsl:template match="/">
<html><body>
<xsl:apply-templates/>
</body></html>
</xsl:template>
</xsl:stylesheet>
The new XSL commands are shown in bold. (Note that they are defined in the xsl namespace). The instruction <xsl:apply-templates> processes the children of the current node. In this case, the current node is the root node.
Despite its simplicity, this example illustrates a number of important ideas, so it is worth understanding thoroughly. The first concept is that a stylesheet contains a number of templates, defined with the <xsl:template> tag. Each template contains a match attribute, which uses the XPath addressing mechanisms described in How XPath Works to select the elements that the template will be applied to.
Within the template, tags that do not start with the xsl: namespace prefix are simply copied. The newlines and whitespace that follow them are also copied, and that helps to make the resulting output readable.
Note - When a newline is not present, whitespace is generally ignored. To include whitespace in the output in such cases, or to include other text, you can use the <xsl:text> tag. Basically, an XSLT stylesheet expects to process tags. So everything it sees needs to be either an <xsl:..> tag, some other tag, or whitespace.
In this case, the non-XSL tags are HTML tags. So when the root tag is matched, XSLT outputs the HTML start tags, processes any templates that apply to children of the root, and then outputs the HTML end tags.
Process the <TITLE> Element
Next, add a template to process the article title:
<xsl:template match="/ARTICLE/TITLE">
<h1 align="center"> <xsl:apply-templates/> </h1>
</xsl:template>
</xsl:stylesheet>
In this case, you specify a complete path to the TITLE element and output some HTML to make the text of the title into a large, centered heading. In this case, the apply-templates tag ensures that if the title contains any inline tags such as italics, links, or underlining, they also will be processed.
More importantly, the apply-templates instruction causes the text of the title to be processed. Like the DOM data model, the XSLT data model is based on the concept of text nodes contained in element nodes (which, in turn, can be contained in other element nodes, and so on). That hierarchical structure constitutes the source tree. There is also a result tree, which contains the output.
XSLT works by transforming the source tree into the result tree. To visualize the result of XSLT operations, it is helpful to understand the structure of those trees, and their contents. (For more on this subject, see XSLT/XPath Data Model).
Process Headings
To continue processing the basic structure elements, add a template to process the top-level headings:
<xsl:template match="/ARTICLE/SECT">
<h2> <xsl:apply-templates
select="text()|B|I|U|DEF|LINK"/> </h2>
<xsl:apply-templates select="SECT|PARA|LIST|NOTE"/>
</xsl:template>
</xsl:stylesheet>
Here, you specify the path to the topmost SECT elements. But this time, you apply templates in two stages using the select attribute. For the first stage, you select text nodes, as well as inline tags such as bold and italics, using the XPath text() function. (The vertical pipe ( |) is used to match multiple items: text or a bold tag or an italics tag, etc). In the second stage, you select the other structure elements contained in the file, for sections, paragraphs, lists, and notes.
Using the select attribute lets you put the text and inline elements between the <h2>...</h2> tags, while making sure that all the structure tags in the section are processed afterward. In other words, you make sure that the nesting of the headings in the XML document is not reflected in the HTML formatting, a distinction that is important for HTML output.
In general, using the select clause lets you apply all templates to a subset of the information available in the current context. As another example, this template selects all attributes of the current node:
<xsl:apply-templates select="@*"/></attributes>
Next,add the virtually identical template to process subheadings that are nested one level deeper:
<xsl:template match="/ARTICLE/SECT/SECT">
<h3> <xsl:apply-templates
select="text()|B|I|U|DEF|LINK"/> </h3>
<xsl:apply-templates select="SECT|PARA|LIST|NOTE"/>
</xsl:template>
</xsl:stylesheet>
Generate a Runtime Message
You could add templates for deeper headings, too, but at some point you must stop, if only because HTML goes down only to five levels. For this example, you will stop at two levels of section headings. But if the XML input happens to contain a third level, you will want to deliver an error message to the user. This section shows you how to do that.
Note - We could continue processing SECT elements that are further down, by selecting them with the expression /SECT/SECT//SECT. The // selects any SECT elements, at any depth, as defined by the XPath addressing mechanism. But instead we will take the opportunity to play with messaging.
Add the following template to generate an error when a section is encountered that is nested too deep:
<xsl:template match="/ARTICLE/SECT/SECT/SECT">
<xsl:message terminate="yes">
Error: Sections can only be nested 2 deep.
</xsl:message>
</xsl:template>
</xsl:stylesheet>
The terminate="yes" clause causes the transformation process to stop after the message is generated. Without it, processing could still go on, with everything in that section being ignored.
As an additional exercise, you could expand the stylesheet to handle sections nested up to four sections deep, generating <h2>...<h5> tags. Generate an error on any section nested five levels deep.
Finally, finish the stylesheet by adding a template to process the PARA tag:
<xsl:template match="PARA">
<p><xsl:apply-templates/></p>
</xsl:template>
</xsl:stylesheet>
Writing the Basic Program
Now you will modify the program that uses XSLT to echo an XML file unchanged, changing it so that it uses your stylesheet.
Note - The code discussed in this section is in Stylizer.java, which is found in the xslt directory after you unzip XSLT examples into the install-dir /jaxp-1_4_2- release-date /samples directory. The result is stylizer1a.html, found in xslt/data.
The Stylizer example is adapted from TransformationApp02, which parses an XML file and writes to System.out. The main differences between the two programs are described below.
Firstly, Stylizer uses the stylesheet when creating the Transformer object.
...
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamSource;
import javax.xml.transform.stream.StreamResult;
...
public class Stylizer
{
...
public static void main (String argv[])
{
...
try {
File stylesheet = new File(argv[0]);
File datafile = new File(argv[1]);
DocumentBuilder builder =
factory.newDocumentBuilder();
document = builder.parse(
datafile);
...
StreamSource stylesource =
new StreamSource(stylesheet);
Transformer transformer =
Factory.newTransformer(
stylesource);
This code uses the file to create a StreamSource object and then passes the source object to the factory class to get the transformer.
Note - You can simplify the code somewhat by eliminating the DOMSource class. Instead of creating a DOMSource object for the XML file, create a StreamSource object for it, as well as for the stylesheet.
Running the Stylizer Sample
- Navigate to the
samplesdirectory.% cd install-dir /jaxp-1_4_2- release-date /samples. - Download the XSLT examples by clicking this link and unzip them into the install-dir
/jaxp-1_4_2-release-date/samplesdirectory. - Navigate to the
xsltdirectory.cd xslt - Compile the
Stylizersample.Type the following command:
% javac Stylizer.java - Run the
Stylizersample onarticle1.xmlusing the stylesheetarticle1a.xsl.% java Stylizer data/article1a.xsl data/article1.xmlYou will see the following output:
<html> <body> <h1 align="center">A Sample Article</h1> <h2>The First Major Section </h2> <p>This section will introduce a subsection.</p> <h3>The Subsection Heading </h3> <p>This is the text of the subsection. </p> </body> </html>At this point, there is quite a bit of excess whitespace in the output. In the next section, you will see how to eliminate most of it.
Trimming the Whitespace
Recall that when you look at the structure of a DOM, there are many text nodes that contain nothing but ignorable whitespace. Most of the excess whitespace in the output comes from these nodes. Fortunately, XSL gives you a way to eliminate them. (For more about the node structure, see XSLT/XPath Data Model).
Note - The stylesheet discussed in this section is in article1b.xsl, which is found in the xslt/data directory after you unzip XSLT examples into the install-dir /jaxp-1_4_2- release-date /samples directory. The result is stylizer1b.html, found in xslt/data.
To remove some of the excess whitespace, add the following highlighted line to the stylesheet.
<xsl:stylesheet ...
>
<xsl:output method="html"/>
<xsl:strip-space elements="SECT"/>
[...]
This instruction tells XSL to remove any text nodes under SECT elements that contain nothing but whitespace. Nodes that contain text other than whitespace will not be affected, nor will other kinds of nodes.
Running the Stylizer Sample with Trimmed Whitespace
- Navigate to the
samplesdirectory.% cd install-dir /jaxp-1_4_2- release-date /samples. - Download the XSLT examples by clicking this link and unzip them into the install-dir
/jaxp-1_4_2-release-date/samplesdirectory. - Navigate to the
xsltdirectory.cd xslt - Compile the
Stylizersample.Type the following command:
% javac Stylizer.java - Run the
Stylizersample onarticle1.xmlusing the stylesheetarticle1b.xsl.% java Stylizer data/article1b.xsl data/article1.xmlYou will see the following output:
<html> <body> <h1 align="center">A Sample Article</h1> <h2>The First Major Section </h2> <p>This section will introduce a subsection.</p> <h3>The Subsection Heading </h3> <p>This is the text of the subsection. </p> </body> </html>That is quite an improvement. There are still newline characters and whitespace after the headings, but those come from the way the XML is written:
<SECT>The First Major Section ____<PARA>This section will introduce a subsection.</PARA> ^^^^Here, you can see that the section heading ends with a newline and indentation space, before the PARA entry starts. That is not a big worry, because the browsers that will process the HTML compress and ignore the excess space routinely. But there is still one more formatting tool at our disposal.
Removing the Last Whitespace
Note - The stylesheet discussed in this section is in article1c.xsl, which is found in the xslt/data directory after you unzip XSLT examples into the install-dir /jaxp-1_4_2- release-date /samples directory. The result is stylizer1c.html, found in xslt/data.
That last little bit of whitespace is disposed of by adding the following to the stylesheet:
<xsl:template match="text()">
<xsl:value-of select="normalize-space()"/>
</xsl:template>
</xsl:stylesheet>
Running Stylizer with this stylesheet will remove all remaining whitespace.
Running the Stylizer Sample with All Whitespace Trimmed
- Navigate to the
samplesdirectory.% cd install-dir /jaxp-1_4_2- release-date /samples. - Download the XSLT examples by clicking this link and unzip them into the install-dir
/jaxp-1_4_2-release-date/samplesdirectory. - Navigate to the
xsltdirectory.cd xslt - Compile the
Stylizersample.Type the following command:
% javac Stylizer.java - Run the
Stylizersample onarticle1.xmlusing the stylesheetarticle1c.xsl.% java Stylizer data/article1c.xsl data/article1.xmlThe output now looks like this:
<html> <body> <h1 align="center">A Sample Article</h1> <h2>The First Major Section</h2> <p>This section will introduce a subsection.</p> <h3>The Subsection Heading</h3> <p>This is the text of the subsection.</p> </body> </html>That is quite a bit better. Of course, it would be nicer if it were indented, but that turns out to be somewhat harder than expected. Here are some possible avenues of attack, along with the difficulties:
Indent optionUnfortunately, the
Indent variablesindent="yes"option that can be applied to XML output is not available for HTML output. Even if that option were available, it would not help, because HTML elements are rarely nested! Although HTML source is frequently indented to show the implied structure, the HTML tags themselves are not nested in a way that creates a real structure.The
Parameterized templates<xsl:text>function lets you add any text you want, including whitespace. So it could conceivably be used to output indentation space. The problem is to vary the amount of indentation space. XSLT variables seem like a good idea, but they do not work here. The reason is that when you assign a value to a variable in a template, the value is known only within that template (statically, at compile time). Even if the variable is defined globally, the assigned value is not stored in a way that lets it be dynamically known by other templates at runtime. When<apply-templates/>invokes other templates, those templates are unaware of any variable settings made elsewhere.Using a parameterized template is another way to modify a template's behavior. But determining the amount of indentation space to pass as the parameter remains the crux of the problem.
At the moment, then, there does not appear to be any good way to control the indentation of HTML formatted output. That would be inconvenient if you needed to display or edit the HTML as plain text. But it is not a problem if you do your editing on the XML form, using the HTML version only for display in a browser. (When you view
stylizer1c.html, for example, you see the results you expect).
Processing the Remaining Structure Elements
In this section, you will process the LIST and NOTE elements, which add more structure to an article.
Note - The sample document described in this section is article2.xml, and the stylesheet used to manipulate it is article2.xsl. The result is stylizer2.html. These files are found in the xslt/data directory after you unzip XSLT examples into the install-dir /jaxp-1_4_2- release-date /samples directory.
Start by adding some test data to the sample document:
<?xml version="1.0"?>
<ARTICLE>
<TITLE>A Sample Article</TITLE>
<SECT>The First Major Section
...
</SECT>
<SECT>The Second Major Section
<PARA>This section adds a LIST and a NOTE.
<PARA>Here is the LIST:
<LIST type="ordered">
<ITEM>Pears</ITEM>
<ITEM>Grapes</ITEM>
</LIST>
</PARA>
<PARA>And here is the NOTE:
<NOTE>Don't forget to go to the hardware store
on your way to the grocery!
</NOTE>
</PARA>
</SECT>
</ARTICLE>
Note - Although the list and note in the XML file are contained in their respective paragraphs, it really makes no difference whether they are contained or not; the generated HTML will be the same either way. But having them contained will make them easier to deal with in an outline-oriented editor.
Modify <PARA> Handling
Next, modify the PARA template to account for the fact that we are now allowing some of the structure elements to be embedded with a paragraph:
<xsl:template match="PARA">
<p> <xsl:apply-templates select="text()|B|I|U|DEF|LINK"/>
</p>
<xsl:apply-templates select="PARA|LIST|NOTE"/>
</xsl:template>
This modification uses the same technique you used for section headings. The only difference is that SECT elements are not expected within a paragraph. (However, a paragraph could easily exist inside another paragraph-for example, as quoted material).
Process <LIST> and <ITEM> Elements
Now you're ready to add a template to process LIST elements:
<xsl:template match="LIST">
<xsl:if test="@type='ordered'">
<ol>
<xsl:apply-templates/>
</ol>
</xsl:if>
<xsl:if test="@type='unordered'">
<ul>
<xsl:apply-templates/>
</ul>
</xsl:if>
</xsl:template>
</xsl:stylesheet>
The <xsl:if> tag uses the test="" attribute to specify a Boolean condition. In this case, the value of the type attribute is tested, and the list that is generated changes depending on whether the value is ordered or unordered.
Note two important things in this example:
- There is no else clause, nor is there a return or exit statement, so it takes two
<xsl:if>tags to cover the two options. (Or the<xsl:choose>tag could have been used, which provides case-statement functionality). - Single quotes are required around the attribute values. Otherwise, the XSLT processor attempts to interpret the word ordered as an XPath function instead of as a string.
Now finish LIST processing by handling ITEM elements:
<xsl:template match="ITEM">
<li><xsl:apply-templates/>
</li>
</xsl:template>
</xsl:stylesheet>
Ordering Templates in a Stylesheet
By now, you should have the idea that templates are independent of one another, so it does not generally matter where they occur in a file. So from this point on, we will show only the template you need to add. (For the sake of comparison, they're always added at the end of the example stylesheet).
Order does make a difference when two templates can apply to the same node. In that case, the one that is defined last is the one that is found and processed. For example, to change the ordering of an indented list to use lowercase alphabetics, you could specify a template pattern that looks like this: //LIST//LIST. In that template, you would use the HTML option to generate an alphabetic enumeration, instead of a numeric one.
But such an element could also be identified by the pattern //LIST. To make sure that the proper processing is done, the template that specifies //LIST would have to appear before the template that specifies //LIST//LIST.
Process <NOTE> Elements
The last remaining structure element is the NOTE element. Add the following template to handle that.
<xsl:template match="NOTE">
<blockquote><b>Note:</b><br/>
<xsl:apply-templates/>
</p></blockquote>
</xsl:template>
</xsl:stylesheet>
This code brings up an interesting issue that results from the inclusion of the <br/> tag. For the file to be well-formed XML, the tag must be specified in the stylesheet as <br/>, but that tag is not recognized by many browsers. And although most browsers recognize the sequence <br></br>, they all treat it like a paragraph break instead of a single line break.
In other words, the transformation must generate a <br> tag, but the stylesheet must specify <br/>. That brings us to the major reason for that special output tag we added early in the stylesheet:
<xsl:stylesheet ... >
<xsl:output method="html"/>
[...]
</xsl:stylesheet>
That output specification converts empty tags such as <br/> to their HTML form, <br>, on output. That conversion is important, because most browsers do not recognize the empty tags. Here is a list of the affected tags:
area frame isindex
base hr link
basefont img meta
br input param
col
To summarize, by default XSLT produces well-formed XML on output. And because an XSL stylesheet is well-formed XML to start with, you cannot easily put a tag such as <br> in the middle of it. The <xsl:output method="html"/> tag solves the problem so that you can code <br/> in the stylesheet but get <br> in the output.
The other major reason for specifying <xsl:output method="html"/> is that, as with the specification <xsl:output method="text"/>, generated text is not escaped. For example, if the stylesheet includes the < entity reference, it will appear as the < character in the generated text. When XML is generated, on the other hand, the < entity reference in the stylesheet would be unchanged, so it would appear as < in the generated text.
Note - If you actually want < to be generated as part of the HTML output, you will need to encode it as <. That sequence becomes < on output, because only the & is converted to an & character.
Running the Stylizer Sample With LIST and NOTE Elements Defined
- Navigate to the
samplesdirectory.% cd install-dir /jaxp-1_4_2- release-date /samples. - Download the XSLT examples by clicking this link and unzip them into the install-dir
/jaxp-1_4_2-release-date/samplesdirectory. - Navigate to the
xsltdirectory.cd xslt - Compile the
Stylizersample.Type the following command:
% javac Stylizer.java - Run the
Stylizersample onarticle2.xmlusing the stylesheetarticle2.xsl.% java Stylizer data/article2.xsl data/article2.xmlHere is the HTML that is generated for the second section when you run the program now:
... <h2>The Second Major Section</h2> <p>This section adds a LIST and a NOTE.</p> <p>Here is the LIST:</p> <ol> <li>Pears</li> <li>Grapes</li> </ol> <p>And here is the NOTE:</p> <blockquote> <b>Note:</b> <br>Do not forget to go to the hardware store on your way to the grocery! </blockquote>
Process Inline (Content) Elements
The only remaining tags in the ARTICLE type are the inline tags-the ones that do not create a line break in the output, but instead are integrated into the stream of text they are part of.
Inline elements are different from structure elements in that inline elements are part of the content of a tag. If you think of an element as a node in a document tree, then each node has both content and structure. The content is composed of the text and inline tags it contains. The structure consists of the other elements (structure elements) under the tag.
Note - The sample document described in this section is article3.xml, and the stylesheet used to manipulate it is article3.xsl. The result is stylizer3.html.
Start by adding one more bit of test data to the sample document:
<?xml version="1.0"?>
<ARTICLE>
<TITLE>A Sample Article</TITLE>
<SECT>The First Major Section
[...]
</SECT>
<SECT>The Second Major Section
[...]
</SECT>
<SECT>The <I>Third</I> Major Section
<PARA>In addition to the inline tag in the heading,
this section defines the term <DEF>inline</DEF>,
which literally means "no line break". It also
adds a simple link to the main page for the Java
platform (<LINK>http://www.oracle.com/technetwork/java</LINK>),
as well as a link to the
<LINK target="http://www.oracle.com/technetwork/java">XML</LINK>
page.
</PARA>
</SECT>
</ARTICLE>
Now process the inline <DEF> elements in paragraphs, renaming them to HTML italics tags:
<xsl:template match="DEF">
<i> <xsl:apply-templates/> </i>
</xsl:template>
Next, comment out the text-node normalization. It has served its purpose, and now you are to the point that you need to preserve important spaces:
<!-- <xsl:template match="text()">
<xsl:value-of select="normalize-space()"/>
</xsl:template>
-->
This modification keeps us from losing spaces before tags such as <I> and <DEF>. (Try the program without this modification to see the result).
Now process basic inline HTML elements such as <B>, <I>, and <U> for bold, italics, and underlining.
<xsl:template match="B|I|U">
<xsl:element name="{name()}">
<xsl:apply-templates/>
</xsl:element>
</xsl:template>
The <xsl:element> tag lets you compute the element you want to generate. Here, you generate the appropriate inline tag using the name of the current element. In particular, note the use of curly braces ( {}) in the name=".." expression. Those curly braces cause the text inside the quotes to be processed as an XPath expression instead of being interpreted as a literal string. Here, they cause the XPath name() function to return the name of the current node.
Curly braces are recognized anywhere that an attribute value template can occur. (Attribute value templates are defined in section 7.6.2 of the XSLT specification, and they appear several places in the template definitions). In such expressions, curly braces can also be used to refer to the value of an attribute, {@foo}, or to the content of an element {foo}.
Note - You can also generate attributes using <xsl:attribute>. For more information, see section 7.1.3 of the XSLT Specification.
The last remaining element is the LINK tag. The easiest way to process that tag will be to set up a named template that we can drive with a parameter:
<xsl:template name="htmLink">
<xsl:param name="dest" select="UNDEFINED"/>
<xsl:element name="a">
<xsl:attribute name="href">
<xsl:value-of select="$dest"/>
</xsl:attribute>
<xsl:apply-templates/>
</xsl:element>
</xsl:template>
The major difference in this template is that, instead of specifying a match clause, you give the template a name using the name="" clause. So this template gets executed only when you invoke it.
Within the template, you also specify a parameter named dest using the <xsl:param> tag. For a bit of error checking, you use the select clause to give that parameter a default value of UNDEFINED. To reference the variable in the <xsl:value-of> tag, you specify $dest.
Note - Recall that an entry in quotes is interpreted as an expression unless it is further enclosed in single quotes. That is why the single quotes were needed earlier in "@type='ordered'" to make sure that ordered was interpreted as a string.
The <xsl:element> tag generates an element. Previously, you have been able to simply specify the element we want by coding something like <html>. But here you are dynamically generating the content of the HTML anchor ( <a>) in the body of the <xsl:element> tag. And you are dynamically generating the href attribute of the anchor using the <xsl:attribute> tag.
The last important part of the template is the <apply-templates> tag, which inserts the text from the text node under the LINK element. Without it, there would be no text in the generated HTML link.
Next, add the template for the LINK tag, and call the named template from within it:
<xsl:template match="LINK">
<xsl:if test="@target">
<!--Target attribute specified.-->
<xsl:call-template name="htmLink">
<xsl:with-param name="dest" select="@target"/>
</xsl:call-template>
</xsl:if>
</xsl:template>
<xsl:template name="htmLink">
[...]
The test="@target" clause returns true if the target attribute exists in the LINK tag. So this <xsl-if> tag generates HTML links when the text of the link and the target defined for it are different.
The <xsl:call-template> tag invokes the named template, whereas <xsl:with-param> specifies a parameter using the name clause and specifies its value using the select clause.
As the very last step in the stylesheet construction process, add the <xsl-if> tag to process LINK tags that do not have a target attribute.
<xsl:template match="LINK">
<xsl:if test="@target">
[...]
</xsl:if>
<xsl:if test="not(@target)">
<xsl:call-template name="htmLink">
<xsl:with-param name="dest">
<xsl:apply-templates/>
</xsl:with-param>
</xsl:call-template>
</xsl:if>
</xsl:template>
The not(...) clause inverts the previous test (remember, there is no else clause). So this part of the template is interpreted when the target attribute is not specified. This time, the parameter value comes not from a select clause, but from the contents of the <xsl:with-param> element.
Note - Just to make it explicit: Parameters and variables (which are discussed in a few moments in What Else Can XSLT Do? can have their value specified either by a select clause, which lets you use XPath expressions, or by the content of the element, which lets you use XSLT tags.
In this case, the content of the parameter is generated by the <xsl:apply-templates/> tag, which inserts the contents of the text node under the LINK element.
Running the Stylizer Sample With Inline Elements Defined
- Navigate to the
samplesdirectory.% cd install-dir /jaxp-1_4_2- release-date /samples. - Download the XSLT examples by clicking this link and unzip them into the install-dir
/jaxp-1_4_2-release-date/samplesdirectory. - Navigate to the
xsltdirectory.cd xslt - Compile the
Stylizersample.Type the following command:
% javac Stylizer.java - Run the
Stylizersample onarticle3.xmlusing the stylesheetarticle3.xsl.% java Stylizer data/article3.xsl data/article3.xmlWhen you run the program now, the results should look something like this:
[...] <h2>The <I>Third</I> Major Section </h2> <p>In addition to the inline tag in the heading, this section defines the term <i>inline</i>, which literally means "no line break". It also adds a simple link to the main page for the Java platform (<a href="http://java. sun.com">http://www.oracle.com/technetwork/java</a>), as well as a link to the <a href="#">XML</a> page. </p>Good work! You have now converted a rather complex XML file to HTML. (As simple as it appears at first, it certainly provides a lot of opportunity for exploration).
Printing the HTML
You have now converted an XML file to HTML. One day, someone will produce an HTML-aware printing engine that you will be able to find and use through the Java Printing Service API. At that point, you will have ability to print an arbitrary XML file by generating HTML. All you will have to do is to set up a stylesheet and use your browser.
What Else Can XSLT Do?
As lengthy as this section has been, it has only scratched the surface of XSLT's capabilities. Many additional possibilities await you in the XSLT specification. Here are a few things to look for:
import (Section 2.6.2) and include (section 2.6.1)
rt (Section 2.6.2) and include (section 2.6.1) Use these statements to modularize and combine XSLT stylesheets. The include statement simply inserts any definitions from the included file. The import statement lets you override definitions in the imported file with definitions in your own stylesheet.
for-each loops (section 8)
Loop over a collection of items and process each one in turn.
choose (case statement) for conditional processing (section 9.2)
Branch to one of multiple processing paths depending on an input value.
Generating numbers (section 7.7)Dynamically generate numbered sections, numbered elements, and numeric literals. XSLT provides three numbering modes:
-
Single: Numbers items under a single heading, like an ordered list in HTML
-
Multiple: Produces multilevel numbering such as "A.1.3"
-
Any: Consecutively numbers items wherever they appear, as with footnotes in a chapter.
Control enumeration formatting so that you get numerics ( format="1"), uppercase alphabetics ( format="A"), lowercase alphabetics ( format="a"), or compound numbers, like "A.1," as well as numbers and currency amounts suited for a specific international locale.
Produce output in a desired sorting order.
Mode-based templates (section 5.7)Process an element multiple times, each time in a different "mode." You add a mode attribute to templates and then specify <apply-templates mode="..."> to apply only the templates with a matching mode. Combine with the <apply-templates select="..."> attribute to apply mode-based processing to a subset of the input data.
Variables are something like method parameters, in that they let you control a template's behavior. But they are not as valuable as you might think. The value of a variable is known only within the scope of the current template or <xsl:if> tag (for example) in which it is defined. You cannot pass a value from one template to another, or even from an enclosed part of a template to another part of the same template.
These statements are true even for a "global" variable. You can change its value in a template, but the change applies only to that template. And when the expression used to define the global variable is evaluated, that evaluation takes place in the context of the structure's root node. In other words, global variables are essentially runtime constants. Those constants can be useful for changing the behavior of a template, especially when coupled with include and import statements. But variables are not a general-purpose data-management mechanism.
The Trouble with Variables
It is tempting to create a single template and set a variable for the destination of the link, rather than go to the trouble of setting up a parameterized template and calling it two different ways. The idea is to set the variable to a default value (say, the text of the LINK tag) and then, if the target attribute exists, set the destination variable to the value of the target attribute.
That would be a good idea-if it worked. But again, the issue is that variables are known only in the scope within which they are defined. So when you code an <xsl:if> tag to change the value of the variable, the value is known only within the context of the <xsl:if> tag. Once </xsl:if> is encountered, any change to the variable's setting is lost.
A similarly tempting idea is the possibility of replacing the text()|B|I|U|DEF|LINK specification with a variable ( $inline). But because the value of the variable is determined by where it is defined, the value of a global inline variable consists of text nodes, <B> nodes, and so on, that happen to exist at the root level. In other words, the value of such a variable, in this case, is null.